Clear Sky Science · it
Modello autosupervisionato non dominato ordinato per il co-clustering
Trovare gruppi nascosti in dati complessi
Le moderne tabelle di dati — come le valutazioni di film da parte degli utenti, i geni per paziente o i prodotti per cliente — sono così grandi e intrecciate che è difficile scorgere schemi chiari. Questo articolo presenta un nuovo modo di rivelare tale struttura nascosta, chiamato Modello Autosupervisionato Non-dominato Ordinato per il Co-clustering (SNSC). Invece di raggruppare solo le persone o solo gli elementi, SNSC cerca gruppi significativi di entrambi contemporaneamente, rivelando quali sottoinsiemi di righe e colonne appartengono davvero insieme. Per i lettori curiosi di sapere come algoritmi più intelligenti possano estrarre maggiore intuizione dai dati esistenti, questo lavoro mostra come idee provenienti dall’evoluzione, dall’apprendimento autosupervisionato e dall’ottimizzazione multi-obiettivo possano essere combinate in uno strumento potente.
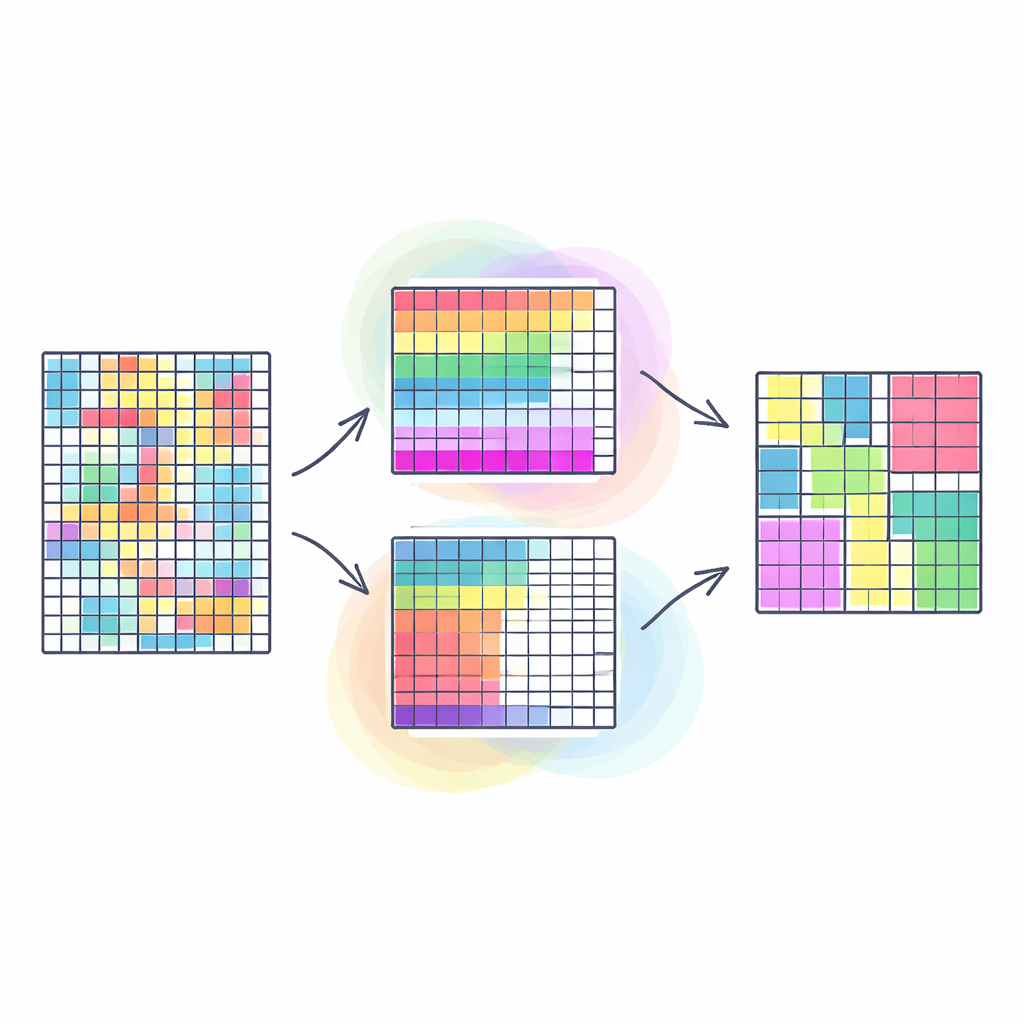
Perché è importante raggruppare righe e colonne insieme
I metodi di clustering tradizionali di solito raggruppano righe simili in una tabella — per esempio, clienti con abitudini d’acquisto simili — trattando tutte le colonne come ugualmente importanti. Il co-clustering va oltre: raggruppa simultaneamente sia le righe sia le colonne, in modo da scoprire blocchi di dati in cui un particolare sottoinsieme di clienti si comporta in modo simile su un particolare sottoinsieme di prodotti. Questo tipo di “doppio raggruppamento” spesso mette in luce schemi più chiari e utili, come comunità nelle reti sociali o segmenti nelle immagini. Tuttavia, la maggior parte degli approcci esistenti cerca di comprimere questo problema naturalmente multi-sfaccettato in un unico obiettivo, il che può semplificare eccessivamente la realtà e rendere la qualità dei risultati molto sensibile a scelte arbitrarie di pesatura.
Trasformare il co-clustering in molti obiettivi simultanei
Gli autori trattano il co-clustering come un vero compito a obiettivi multipli. Il loro modello SNSC ottimizza quattro obiettivi contemporaneamente: quanto compatte sono le aggregazioni di campioni, quanto nettamente sono separate le aggregazioni di caratteristiche e quanto entrambi concordano con informazioni di similarità apprese direttamente dai dati. Invece di usare etichette fornite dall’uomo, SNSC costruisce due mappe di similarità — una per i campioni e una per le caratteristiche — basate su quanto sono vicini l’uno all’altro nello spazio dei dati originale. Queste mappe servono come una sorta di guida interna: campioni o caratteristiche che appaiono simili secondo i dati grezzi sono incoraggiati a finire nello stesso cluster, senza trasformare il metodo in un sistema completamente supervisionato. Bilanciando la struttura complessiva con questi indizi locali, SNSC mira a trovare cluster che siano sia compatti sia fedeli alla geometria interna dei dati.
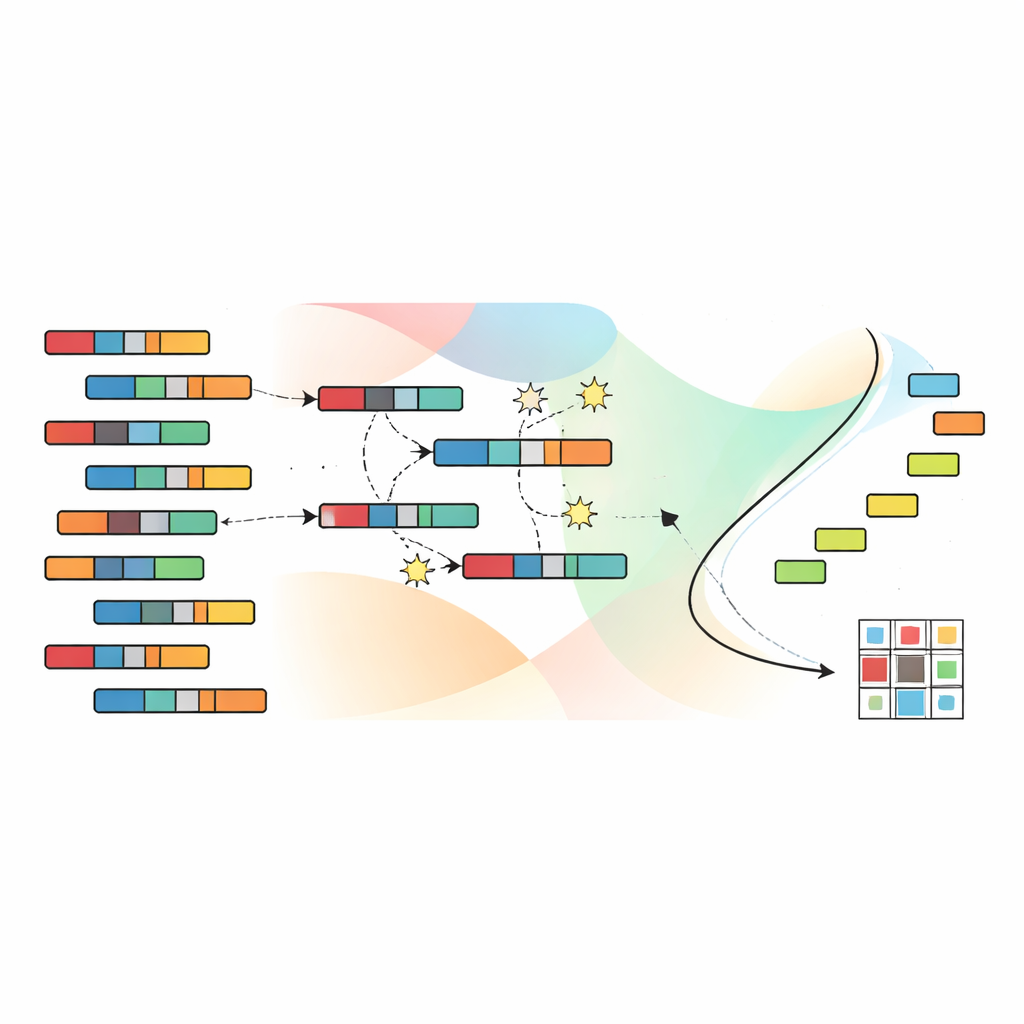
Lasciare che l’evoluzione cerchi raggruppamenti migliori
Per esplorare l’enorme spazio delle possibili aggregazioni, gli autori si affidano a un algoritmo genetico, ispirato alla selezione naturale. Ogni soluzione candidata codifica un’assegnazione completa di campioni e caratteristiche ai cluster. Una popolazione di tali candidati viene evoluta su molte generazioni: le soluzioni promettenti vengono combinate e leggermente perturbate, mentre quelle meno efficaci vengono scartate. Crucialmente, SNSC utilizza una tecnica chiamata non-dominated sorting, che non riduce i quattro obiettivi a un singolo punteggio. Invece, mantiene un insieme di soluzioni “non dominate” in cui nessuna è strettamente peggiore di un’altra rispetto a tutti gli obiettivi. Punti di riferimento nello spazio degli obiettivi aiutano a mantenere una distribuzione diversificata di soluzioni, così che l’algoritmo non rimanga bloccato in una sola stretta regione di possibilità.
Imparare buoni punti di partenza senza etichette
Un’innovazione chiave in SNSC è come inizializza questa ricerca evolutiva. Piuttosto che partire da ipotesi completamente casuali, il modello usa una strategia ibrida. Metà delle soluzioni iniziali sono casuali, fornendo una vasta esplorazione. L’altra metà è creata applicando metodi di clustering standard — come k-means, fuzzy clustering e tecniche correlate — ai dati e alla loro trasposizione. Questi candidati “bootstrap” agiscono come indizi autosupervisionati ricavati dai dati stessi, spesso avviando il processo evolutivo più vicino a pattern utili. Gli esperimenti mostrano che questa miscela di casualità e autosupervisione migliora la robustezza e riduce il rischio di stabilizzarsi in pessimi ottimi locali.
Test su dataset reali e il loro significato
Gli autori valutano SNSC su quattordici dataset reali provenienti da immagini, multimedia e raccolte classiche di machine learning, confrontandolo con diversi metodi di co-clustering noti. Utilizzando misure comunemente accettate di qualità del clustering, come accuratezza e varianti della somma degli errori quadratici, SNSC sovente supera le alternative e mostra guadagni statisticamente significativi su molti dataset. Sebbene non sia il metodo più veloce — la sua ricerca genetica e la costruzione delle similarità sono computazionalmente più onerose — produce risultati costantemente forti e stabili, suggerendo che è particolarmente adatto quando la qualità è più importante della pura velocità.
Schemi più chiari a un prezzo computazionale
In termini semplici, l’articolo mostra che trattare il co-clustering come un problema a molti obiettivi e lasciare che un processo evolutivo cerchi soluzioni bilanciate può rivelare schemi più chiari e più affidabili in complesse tabelle di dati. Le mappe di similarità autosupervisionate aiutano l’algoritmo a sfruttare la struttura già presente nei dati, senza richiedere etichette umane. Il compromesso è il costo computazionale: SNSC richiede più tempo e risorse rispetto a metodi più semplici, soprattutto su dataset molto grandi. I lavori futuri, suggeriscono gli autori, dovrebbero concentrarsi sul rendere l’approccio più scalabile, per esempio accelerando la ricerca genetica o eseguendola in parallelo. Anche così, per applicazioni in cui comprendere relazioni intricate tra due tipi di entità è importante, SNSC offre un modo promettente e sfumato per vedere ordine nel caos apparente.
Citazione: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Parole chiave: co-clustering, ottimizzazione multi-obiettivo, apprendimento autosupervisionato, algoritmi genetici, data mining