Clear Sky Science · he
מודל ממוּיין לא-מוחלט עצמי ללמידת צבירה-משותפת
מציאת קבוצות חבויות בנתונים מורכבים
טבלאות נתונים מודרניות — כמו דירוגי סרטים על־ידי משתמשים, גנים על־ידי מטופלים או מוצרים על־ידי לקוחות — גדולות ומסובכות עד שכמעט לא רואים דפוסים ברורים. מאמר זה מציג שיטה חדשה לחשיפת מבנה חבוי כזה, הנקראת המודל הממוּיין לא-מוחלט עצמי לצבירה-משותפת (SNSC). במקום לקבץ רק את האנשים או רק את הפריטים, SNSC מחפש בו־זמנית קבוצות משמעותיות משל שניהם, ומגלה אילו תתי־קבוצות של שורות ועמודות באמת שייכות זו לזו. לקוראים הסקרנים איך אלגוריתמים חכמים יכולים להפיק תובנות נוספות מתוך נתונים קיימים, עבודה זו מראה כיצד רעיונות מהתפתחות טבעית, למידה עצמי-מונחית ואופטימיזציה מולטימטרית יכולים להשתלב לכלי חזק.
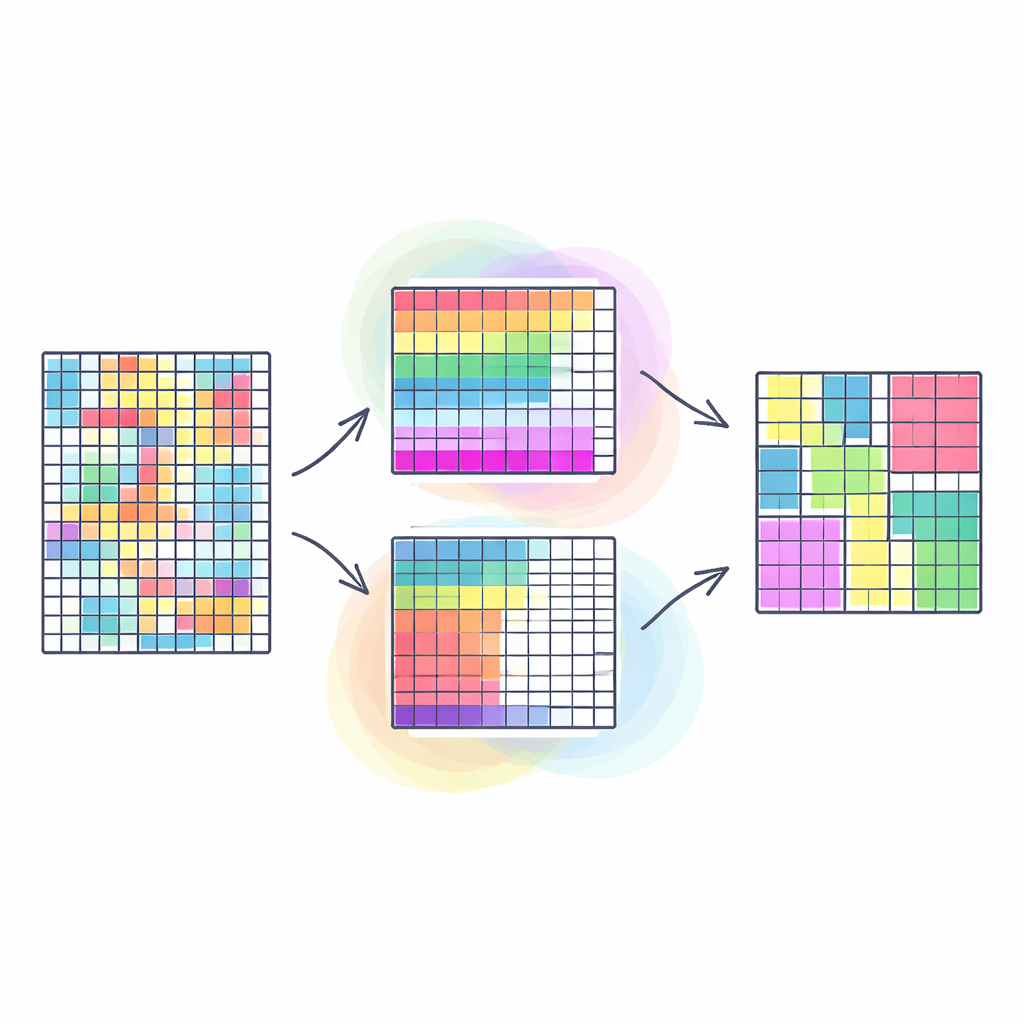
מדוע חשוב לקבץ שורות ועמודות יחד
שיטות צבירה מסורתיות בדרך כלל מקבצות שורות דומות בטבלה — למשל לקוחות עם הרגלי קנייה דומים — כשהן מתייחסות לכל העמודות כאחידות. צבירה-משותפת הולכת צעד קדימה: היא מקבצת בו־זמנית גם שורות וגם עמודות, כך שגורמים בלוקים של נתונים שבהם קבוצה מסוימת של לקוחות מתנהגת באופן דומה על קבוצה מסוימת של מוצרים. סוג זה של "קיבוץ כפול" לעתים חשף דפוסים ברורים ושימושיים יותר, כגון קהילות ברשתות חברתיות או מקטעים בתמונות. עם זאת, רוב הגישות הקיימות מנסות לכפות את הבעיה הרב־ממדית הזו על יעד יחיד, מה שעלול לפשט יתר על המידה את המציאות ולהפוך את איכות התוצאות לרגישה לבחירות משקל אקראיות.
להפוך את הצבירה-משותפת לריבוי מטרות
המחברים מתייחסים לצבירה-משותפת כאל משימה בעלת מטרות רבות באמת. מודל SNSC מאופטימיז את ארבע המטרות במקביל: עד כמה המדגמים מקובצים בצורה דחוסה, עד כמה קבוצות התכונות מופרדות בניקיון, ועד כמה שניהם מסכימים עם מידע הדמיון הנלמד ישירות מהנתונים. במקום להשתמש בתוויות מסופקות על־ידי אדם, SNSC בונה שתי מפת דמיון — אחת למדגמים ואחת לתכונות — המבוססות על קרבתן זו לזו במרחב הנתונים המקורי. מפות אלה משמשות כמין הדרכה פנימית: מדגמים או תכונות שנראות דומות לפי הנתונים הגולמיים מעודדים בעדינות להיכנס לאותו אשכול, מבלי להפוך את השיטה למערכת מפוקחת לחלוטין. על ידי איזון של המבנה הכולל עם רמזים מקומיים אלה, SNSC שואפת למצוא אשכולות שהם גם קומפקטיים וגם נאמנים לגיאומטריה הפנימית של הנתונים.
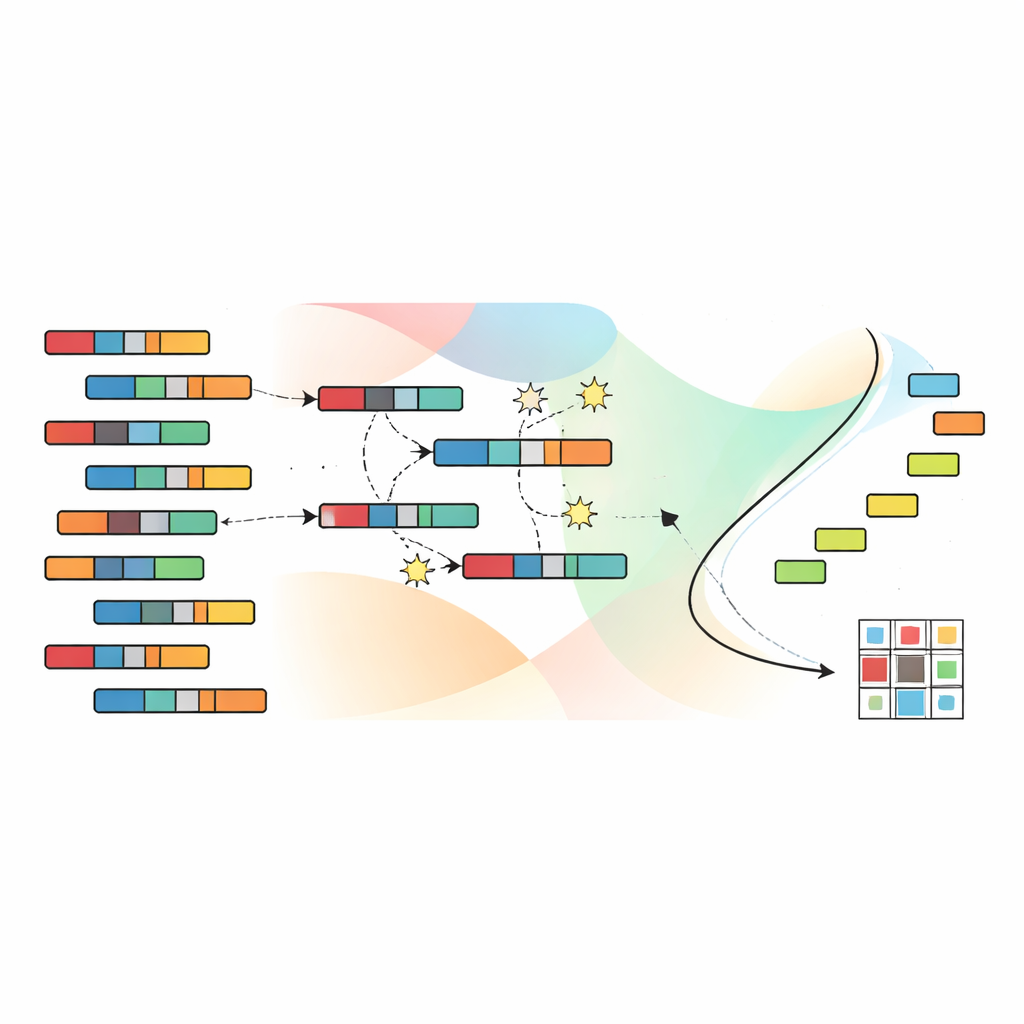
לתת להתפתחות לחפש קיבוצים טובים יותר
כדי לנווט במרחב העצום של הקיבוצים האפשריים, המחברים מסתמכים על אלגוריתם גנטי, בהשראת סלקציה טבעית. כל פתרון מועמד מקודד הקצאה מלאה של מדגמים ותכונות לאשכולות. אוכלוסייה של מועמדים כזו מתפתחת לאורך דורות רבים: פתרונות מבטיחים משולבים ומעט מופרעים, בעוד שפחות יעילים נדחים. באופן קריטי, SNSC משתמש בטכניקה שנקראת מיון לא-מוחלט (non-dominated sorting), שאינה מצמצמת את ארבע המטרות לציון יחיד. במקום זאת, היא שומרת קבוצת פתרונות "לא-מוחלטים" שבה אף פתרון אינו גרוע בהחלטי מאחר בכל המטרות. נקודות ייחוס במרחב המטרות עוזרות לשמור על פיזור מגוון של פתרונות, כך שהאלגוריתם לא ייתקע באזור צר אחד של אפשרויות.
ללמוד נקודות התחלה טובות ללא תוויות
חדשנות מרכזית ב‑SNSC היא האופן שבו היא מאתחלת את חיפוש האבולוציה הזה. במקום להתחיל מניחושים אקראיים גרידא, המודל משתמש באסטרטגיה היברידית. מחצית מהפתרונות ההתחלתיים הם אקראיים, ומספקים חיפוש רחב. המחצית השנייה נוצרת על־ידי יישום שיטות צבירה סטנדרטיות — כגון k‑means, צבירה מטושטשת וטכניקות קשורות — על הנתונים ועל הטרנספוז שלהן. מועמדים "מצוידים" אלה פועלים כרמזים עצמי-מונחים הנגזרים מהנתונים עצמם, ובדרך כלל מתחילים את תהליך האבולוציה קרוב יותר לדפוסים שימושיים. ניסויים מראים ששילוב זה של אקראיות ולמידה עצמי-מונחית משפר גם את העמידות וגם מקטין את הסיכון להיתקע באופטימה מקומית גרועה.
בדיקות על מערכי נתונים אמיתיים ומה המשמעות
המחברים מעריכים את SNSC על ארבעה־עשר מערכי נתונים מהעולם האמיתי מתחומי התמונה, מולטימדיה ואוספי למידת מכונה קלאסיים, ומשווים אותה מול מספר שיטות צבירה-משותפת מוכרות. באמצעות מדדי איכות צבירה מקובלים, כגון דיוק וגרסאות של סכום ריבועי השגיאות, SNSC מרבה להציג ביצועים טובים יותר מהאלטרנטיבות ומראה שיפורים מובהקים סטטיסטית במספר מערכי נתונים. אף שאינה השיטה המהירה ביותר — החיפוש הגנטי ובניית מפות הדמיון צורכים יותר חישובים — היא מספקת תוצאות חזקות ויציבות בעקביות, דבר המצביע על התאמה במיוחד למקרים שבהם איכות חשובה יותר מהירות גולמית.
דפוסים בהירים יותר במחיר חישובי
במונחים פשוטים, המאמר מראה שגישה לצבירה-משותפת כאל בעיית ריבוי מטרות ונתינת תהליך אבולוציוני לחפש פתרונות מאוזנים יכולה לחשוף דפוסים בהירים ואמינים יותר בטבלאות נתונים מורכבות. מפות הדמיון העצמי-מונחות עוזרות לאלגוריתם לנצל את המבנה שכבר קיים בנתונים, בלי להצריך תוויות אנושיות. תמורת זאת יש מחיר חישובי: SNSC דורשת יותר זמן ומשאבים משיטות פשוטות יותר, במיוחד על מערכי נתונים מאוד גדולים. העבודה העתידית, מציעים המחברים, צריכה להתמקד בהגדלת קנה המידה של הגישה, למשל על ידי האצת החיפוש הגנטי או הרצתו במקביל. גם כך, ליישומים שבהם הבנת יחסים מורכבים בין שני סוגי ישויות חשובה, SNSC מציעה דרך מבוססת ומאופקת לראות סדר בתוך כאוס לכאורה.
ציטוט: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
מילות מפתח: צבירה-משותפת, אופטימיזציה מולטימטרית, למידה עצמי-מונחית, אלגוריתמים גנטיים, כריית נתונים