Clear Sky Science · fr
Modèle auto-supervisé non dominé trié pour le co-clustering
Découvrir des groupes cachés dans des données complexes
Les tableaux de données modernes — comme les évaluations de films par des utilisateurs, les gènes par patients, ou les produits par clients — sont si volumineux et emmêlés qu’il est difficile d’y discerner des motifs clairs. Cet article présente une nouvelle méthode pour mettre au jour cette structure cachée, appelée Modèle Auto-supervisé Non-dominé Trié pour le Co-clustering (SNSC). Plutôt que de regrouper uniquement les personnes ou uniquement les objets, SNSC cherche des groupes significatifs des deux simultanément, révélant quels sous-ensembles de lignes et de colonnes appartiennent réellement ensemble. Pour les lecteurs curieux de voir comment des algorithmes plus intelligents peuvent extraire davantage d’informations à partir de données existantes, ce travail montre comment des idées issues de l’évolution, de l’apprentissage auto-supervisé et de l’optimisation multi-objectifs peuvent être combinées en un outil puissant.
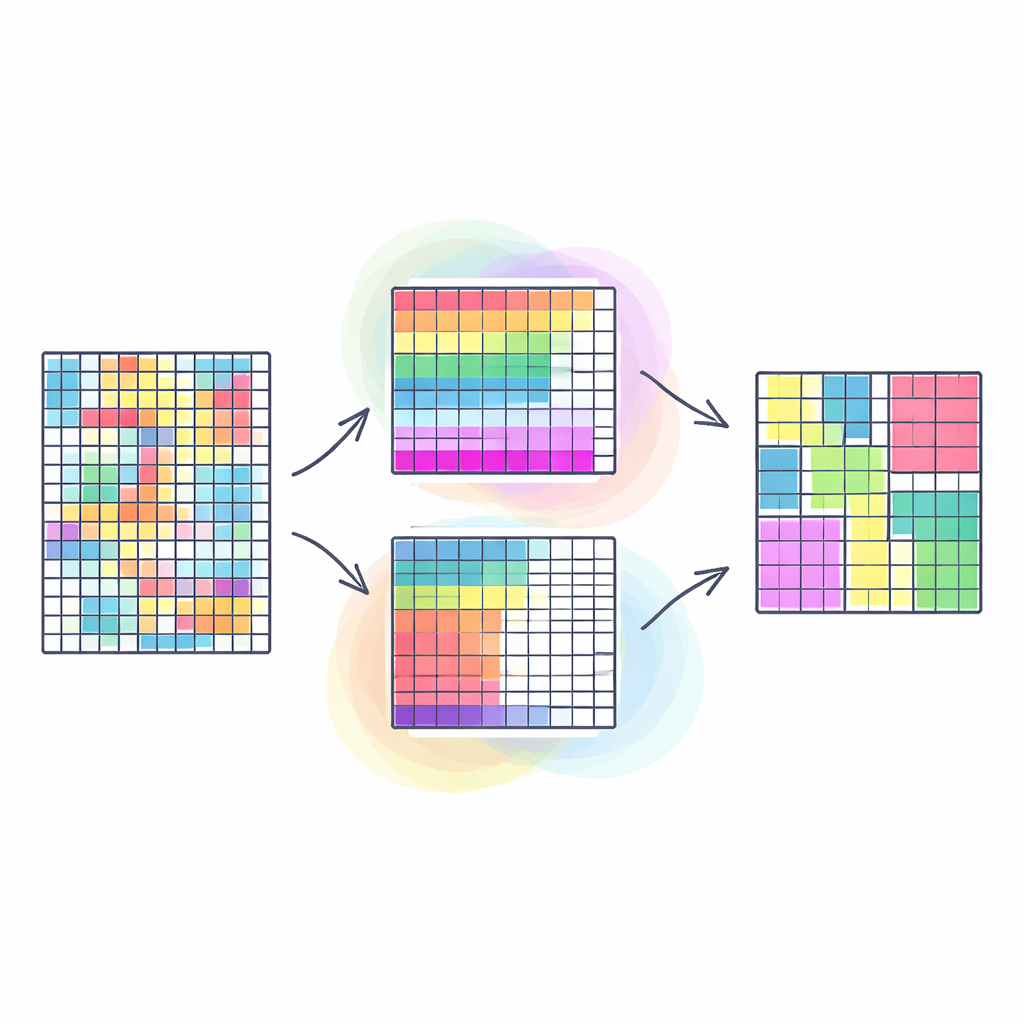
Pourquoi il est important de grouper lignes et colonnes ensemble
Les méthodes de clustering traditionnelles regroupent généralement des lignes similaires d’un tableau — par exemple des clients ayant des habitudes d’achat semblables — en traitant toutes les colonnes comme également importantes. Le co-clustering va plus loin : il regroupe simultanément lignes et colonnes, de sorte que l’on découvre des blocs de données où un sous-ensemble particulier de clients se comporte de façon similaire sur un sous-ensemble particulier de produits. Cette « double partition » met souvent en évidence des motifs plus nets et utiles, tels que des communautés dans des réseaux sociaux ou des segments dans des images. Cependant, la plupart des approches existantes tentent de réduire ce problème naturellement multifacette à un seul objectif, ce qui peut simplifier à l’excès la réalité et rendre la qualité des résultats très sensible à des choix d’arbitrage arbitraires.
Transformer le co-clustering en de nombreux objectifs à la fois
Les auteurs considèrent le co-clustering comme une véritable tâche à objectifs multiples. Leur modèle SNSC optimise quatre objectifs simultanément : la compacité des groupes d’échantillons, la séparation nette des groupes de caractéristiques, et la conformité des deux avec des informations de similarité apprises directement à partir des données. Plutôt que d’utiliser des étiquettes fournies par des humains, SNSC construit deux cartes de similarité — une pour les échantillons et une pour les caractéristiques — basées sur leur proximité dans l’espace de données d’origine. Ces cartes servent de guide interne : les échantillons ou caractéristiques qui se ressemblent selon les données brutes sont doucement encouragés à se retrouver dans le même cluster, sans transformer la méthode en un système entièrement supervisé. En équilibrant la structure globale avec ces indices locaux, SNSC vise à trouver des clusters à la fois compacts et fidèles à la géométrie interne des données.
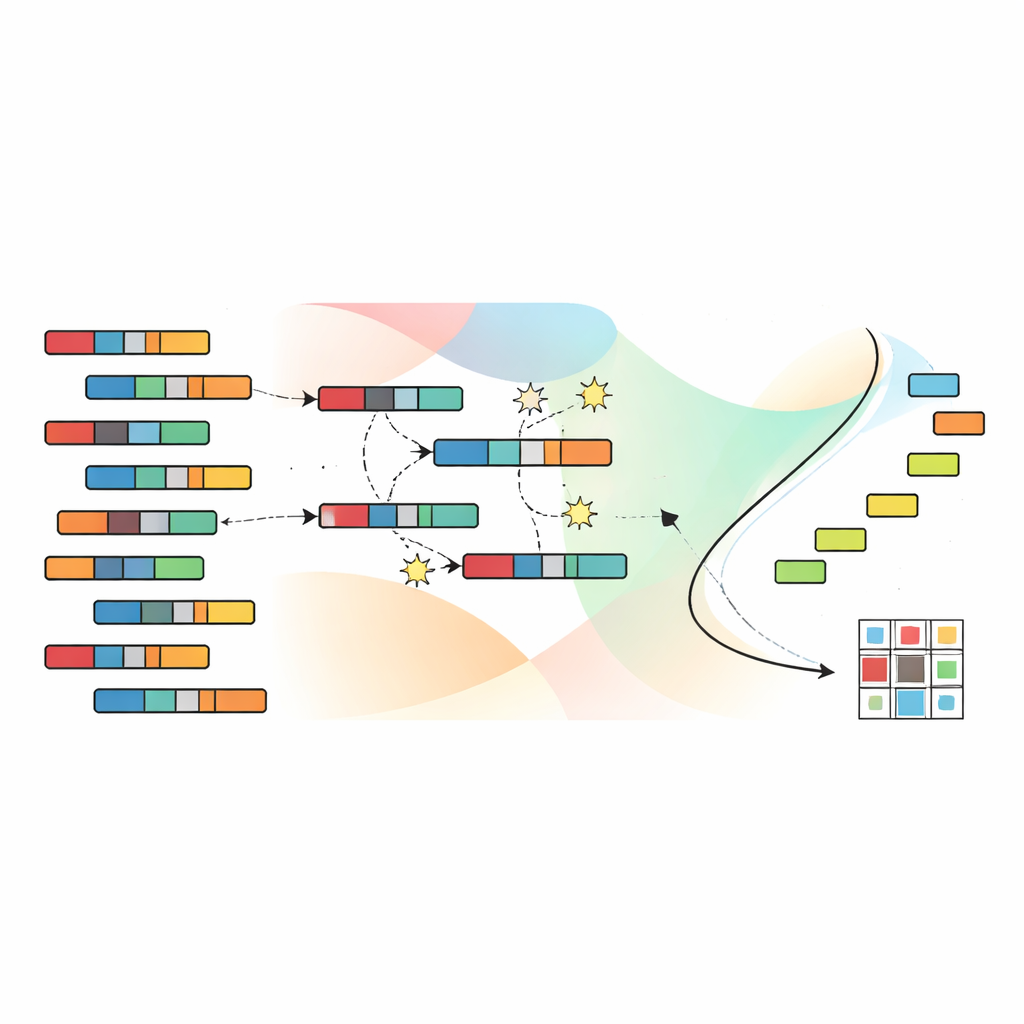
Laisser l’évolution chercher de meilleurs groupements
Pour parcourir l’immense espace des groupements possibles, les auteurs s’appuient sur un algorithme génétique, inspiré de la sélection naturelle. Chaque solution candidate encode une affectation complète des échantillons et des caractéristiques aux clusters. Une population de telles candidates évolue sur de nombreuses générations : les solutions prometteuses sont combinées et légèrement perturbées, tandis que les moins efficaces sont éliminées. De manière cruciale, SNSC utilise une technique appelée tri non-dominé, qui n’agrège pas les quatre objectifs en un seul score. Au lieu de cela, elle conserve un ensemble de solutions « non-dominées » où aucune n’est strictement pire qu’une autre sur l’ensemble des objectifs. Des points de référence dans l’espace des objectifs aident à maintenir une diversité de solutions, afin que l’algorithme ne reste pas bloqué dans une région étroite de possibilités.
Apprendre de bons points de départ sans étiquettes
Une innovation clé de SNSC est la manière d’initialiser cette recherche évolutive. Plutôt que de partir d’hypothèses purement aléatoires, le modèle utilise une stratégie hybride. La moitié des solutions initiales est aléatoire, assurant une exploration large. L’autre moitié est créée en appliquant des méthodes de clustering standard — telles que k-means, le clustering flou et des techniques apparentées — aux données et à leur transposée. Ces candidats « bootstrapés » servent d’indices auto-supervisés dérivés des données elles-mêmes, et commencent souvent le processus d’évolution plus près de motifs utiles. Les expériences montrent que ce mélange d’aléa et d’auto-supervision améliore à la fois la robustesse et réduit le risque de convergence vers de mauvais optima locaux.
Tests sur des jeux de données réels et signification
Les auteurs évaluent SNSC sur quatorze jeux de données réels issus d’ensembles d’images, de multimédia et de collections classiques d’apprentissage automatique, en le comparant à plusieurs méthodes de co-clustering bien connues. En utilisant des mesures communément admises de qualité de clustering, telles que la précision et des variantes de la somme des erreurs quadratiques, SNSC surpasse fréquemment les alternatives et montre des gains statistiquement significatifs sur de nombreux jeux de données. Bien qu’il ne soit pas la méthode la plus rapide — sa recherche génétique et la construction des similarités sont plus coûteuses en calcul — il fournit des résultats constamment solides et stables, ce qui suggère qu’il convient particulièrement lorsque la qualité est plus importante que la vitesse brute.
Des motifs plus clairs à un coût computationnel
En termes simples, l’article montre que traiter le co-clustering comme un problème à objectifs multiples et laisser un processus évolutif chercher des solutions équilibrées peut révéler des motifs plus clairs et plus fiables dans des tableaux de données complexes. Les cartes de similarité auto-supervisées aident l’algorithme à exploiter la structure déjà présente dans les données, sans nécessiter d’étiquettes humaines. Le compromis tient au coût computationnel : SNSC demande plus de temps et de ressources que des méthodes plus simples, en particulier sur des jeux de données très volumineux. Les auteurs suggèrent que des travaux futurs devraient viser à rendre l’approche plus scalable, par exemple en accélérant la recherche génétique ou en l’exécutant en parallèle. Quoi qu’il en soit, pour les applications où comprendre les relations complexes entre deux types d’entités importe, SNSC propose une manière nuancée et prometteuse de faire apparaître de l’ordre dans le chaos apparent.
Citation: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Mots-clés: co-clustering, optimisation multi-objectifs, apprentissage auto-supervisé, algorithmes génétiques, exploration de données