Clear Sky Science · nl
Zelf-gestuurde non-dominated gesorteerde model voor co-clustering
Verborgen groepen vinden in complexe data
Moderne datatabellen — zoals filmbeoordelingen door gebruikers, genexpressie per patiënt of producten per klant — zijn vaak zo groot en verward dat het moeilijk is er duidelijke patronen in te zien. Dit artikel introduceert een nieuwe manier om dergelijke verborgen structuren te ontdekken, het Self-supervised Non-dominated Sorted Model for Co-clustering (SNSC). In plaats van alleen rijen of alleen kolommen te groeperen, zoekt SNSC tegelijk naar betekenisvolle groepen van beide, en legt zo bloot welke deelverzamelingen van rijen en kolommen echt bij elkaar horen. Voor lezers die willen weten hoe slimmere algoritmen meer inzicht uit bestaande data halen, toont dit werk hoe ideeën uit evolutie, zelf-gestuurd leren en multi-objectieve optimalisatie gecombineerd kunnen worden tot een krachtig hulpmiddel.
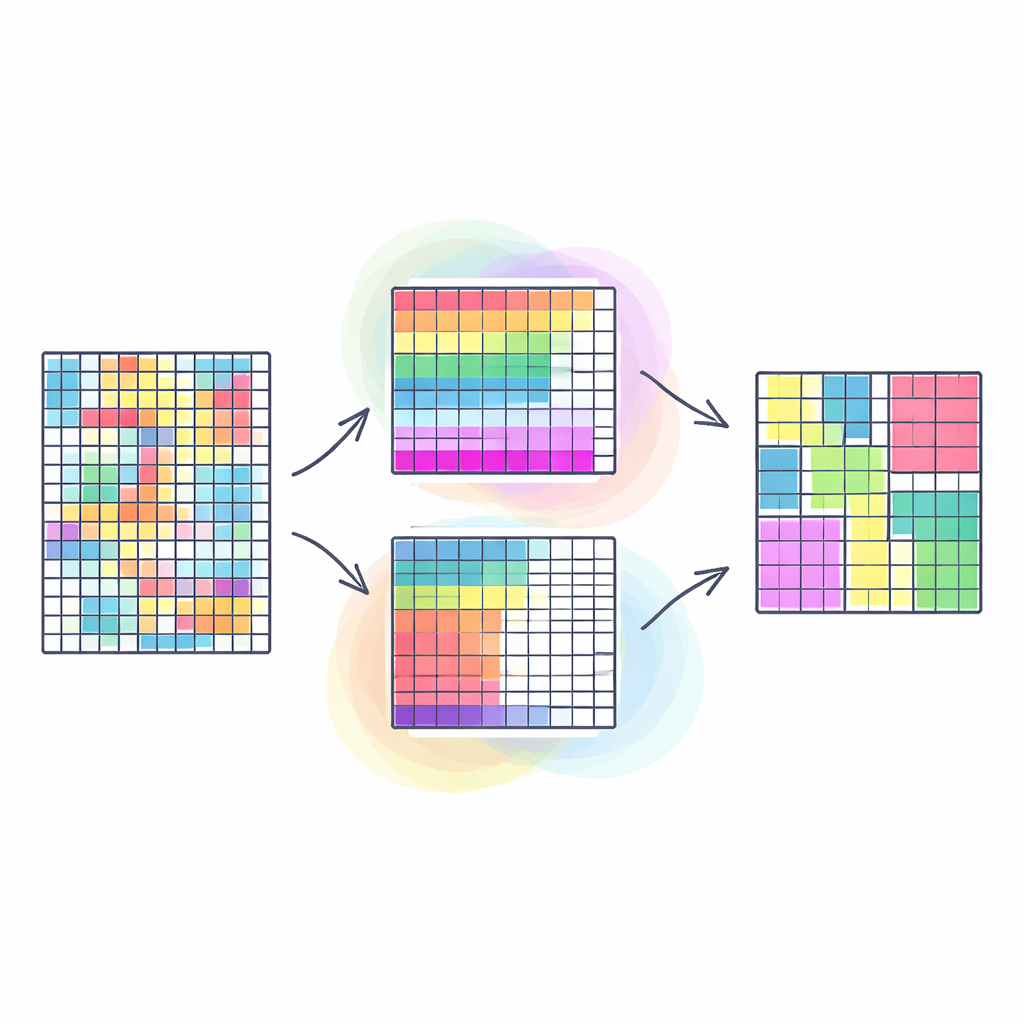
Waarom het samen groeperen van rijen en kolommen ertoe doet
Traditionele clusteringmethoden groeperen meestal vergelijkbare rijen in een tabel — bijvoorbeeld klanten met soortgelijk koopgedrag — en behandelen alle kolommen als even belangrijk. Co-clustering gaat een stap verder: het groepeert gelijktijdig rijen en kolommen, zodat we blokken data ontdekken waarin een specifieke subset klanten zich vergelijkbaar gedraagt op een specifieke subset producten. Dit soort “dubbele groepering” onthult vaak duidelijkere, nuttigere patronen, zoals gemeenschappen in sociale netwerken of segmenten in beelden. De meeste bestaande benaderingen dwingen dit van nature veelzijdige probleem echter in één enkel doel, wat de realiteit kan oversimplificeren en de kwaliteit van de resultaten gevoelig kan maken voor arbitraire wegingskeuzes.
Co-clustering omzetten in vele doelen tegelijk
De auteurs behandelen co-clustering als een echte multi-doelopdracht. Hun SNSC-model optimaliseert vier doelstellingen tegelijk: hoe compact de samples zijn gegroepeerd, hoe goed de feature-groepen gescheiden zijn, en hoe goed beide overeenkomen met gelijkenisinformatie die rechtstreeks uit de data is geleerd. In plaats van gebruik te maken van door mensen aangeleverde labels, bouwt SNSC twee gelijkeniskaarten — één voor samples en één voor features — op basis van hoe dicht ze bij elkaar liggen in de originele dataspace. Deze kaarten dienen als een soort interne begeleiding: samples of features die er volgens de ruwe data op lijken, worden subtiel aangemoedigd om in dezelfde cluster te belanden, zonder de methode volledig supervisie-gedreven te maken. Door de algemene structuur te balanceren met deze lokale aanwijzingen, streeft SNSC ernaar clusters te vinden die zowel compact als trouw aan de innerlijke geometrie van de data zijn.
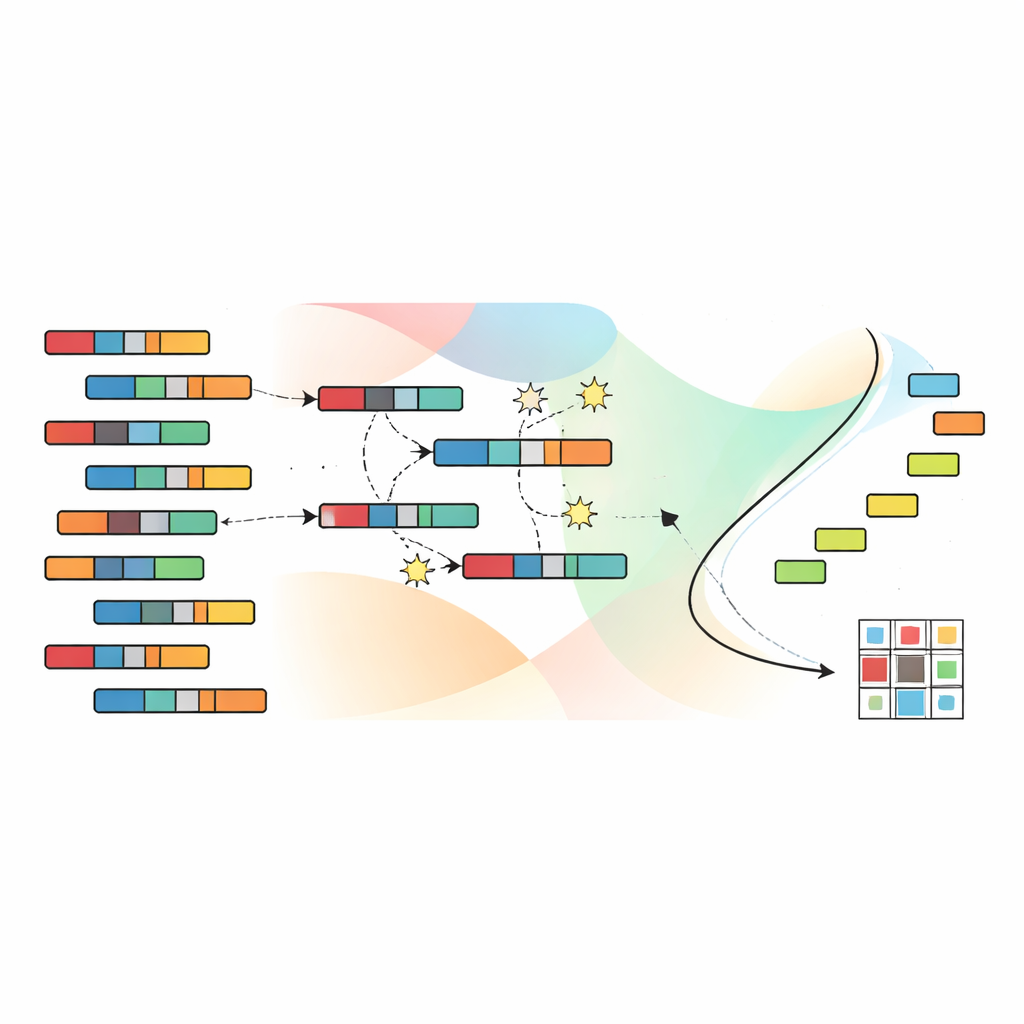
Evolutionair zoeken naar betere groeperingen
Om het enorme zoekveld van mogelijke groeperingen te doorlopen, vertrouwen de auteurs op een genetisch algoritme, geïnspireerd door natuurlijke selectie. Elke kandidaat-oplossing codeert een volledige toewijzing van samples en features aan clusters. Een populatie van zulke kandidaten evolueert over vele generaties: veelbelovende oplossingen worden gecombineerd en licht aangepast, terwijl minder effectieve worden verworpen. Cruciaal is dat SNSC een techniek gebruikt die non-dominated sorting heet, waarbij de vier doelstellingen niet worden samengevoegd tot één enkele score. In plaats daarvan houdt het een verzameling “niet-gedomineerde” oplossingen bij, waarin geen enkele strikt slechter is dan een andere over alle doelen. Referentiepunten in het doelruim helpen een diverse spreiding van oplossingen te behouden, zodat het algoritme niet vastloopt in één smal gebied van mogelijkheden.
Goede startpunten leren zonder labels
Een belangrijke innovatie in SNSC is hoe het deze evolutionaire zoektocht initialiseert. In plaats van puur willekeurige aannames te gebruiken, hanteert het model een hybride strategie. De helft van de initiële oplossingen is willekeurig, wat brede exploratie mogelijk maakt. De andere helft wordt gecreëerd door standaard clusteringmethoden — zoals k-means, fuzzy clustering en verwante technieken — toe te passen op de data en op de getransponeerde data. Deze “bootstrap”-kandidaten fungeren als zelf-gestuurde aanwijzingen afgeleid van de data zelf en plaatsen de evolutie vaak dichter bij nuttige patronen. Experimenten tonen aan dat deze mix van willekeur en zelf-gestuurde initiële oplossingen zowel de robuustheid verbetert als het risico vermindert dat de zoekprocedure in slechte lokale optimums blijft hangen.
Testen op echte datasets en wat het betekent
De auteurs evalueren SNSC op veertien echte datasets uit beeld-, multimedia- en klassieke machine-learningverzamelingen, en vergelijken het met verschillende bekende co-clusteringmethoden. Met gebruik van algemeen geaccepteerde maten voor clusteringkwaliteit, zoals nauwkeurigheid en varianten van de som van gekwadrateerde fouten, presteert SNSC vaak beter dan de alternatieven en toont statistisch significante verbeteringen op veel datasets. Hoewel het niet de snelste methode is — de genetische zoekprocedure en het opbouwen van gelijkeniskaarten zijn computationeel zwaarder — levert het consequent sterke, stabiele resultaten, wat suggereert dat het vooral geschikt is wanneer kwaliteit belangrijker is dan ruwe snelheid.
Duidelijkere patronen tegen een computationele prijs
Kort gezegd laat het artikel zien dat het behandelen van co-clustering als een multi-doelprobleem en het laten zoeken door een evolutionair proces naar gebalanceerde oplossingen duidelijkere, betrouwbaardere patronen kan blootleggen in complexe datatabellen. De zelf-gestuurde gelijkeniskaarten helpen het algoritme de in de data aanwezige structuur te gebruiken, zonder menselijke labels te vereisen. De afweging is computationele kosten: SNSC vraagt meer tijd en middelen dan eenvoudigere methoden, zeker bij zeer grote datasets. Toekomstig werk, zo suggereren de auteurs, zou zich moeten richten op het beter schaalbaar maken van de aanpak, bijvoorbeeld door de genetische zoekprocedure te versnellen of parallel uit te voeren. Desondanks biedt SNSC voor toepassingen waarbij het begrijpen van complexe relaties tussen twee soorten entiteiten belangrijk is een veelbelovende, genuanceerde manier om orde te zien in schijnbare chaos.
Bronvermelding: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Trefwoorden: co-clustering, multi-objectieve optimalisatie, zelf-gestuurd leren, genetische algoritmen, data mining