Clear Sky Science · zh
用于法医科学中深度伪造图像鉴定的基于分数的似然比框架
为什么伪造面孔成为人人关切的问题
如今,外观完全真实的图像和视频可以通过面部替换工具或照片滤镜等消费者应用被制造出来。这些所谓的深度伪造不再只是互联网的奇观——它们可以被用来传播虚假新闻、诈骗他人,或在法庭上对真实证据产生怀疑。本文处理一个对关注数字世界中真相的人都很重要的问题:不仅仅是“这张图片是假的吗?”,而是“证据以何种程度支持这一结论,法官和陪审团能理解的方式有多强?”
从非黑即白的答案到我们有多确定
目前大多数深度伪造检测器表现得像简单的测谎器:输入一张图像,输出标签——真实或伪造,有时还带有置信度分数。对于社交媒体上的日常过滤,这或许足够。但在法庭上,调查人员必须比较两个对立的说法——“该图像被篡改”与“该图像是真实的”——并说明数据以多大程度支持其中一方。作者构建了一个系统,将深度伪造检测器的原始分数转换为“似然比”:一个数值化的表达,说明观测到的证据支持某一说法相对于另一说法的程度,这种表述在指纹和笔迹等其他法医领域已很常用。
构建真实与伪造面孔的严格测试基准
为了使工作基于可靠数据,研究人员依赖于 FaceForensics++,这是一个广泛使用的视频集合,包含真实面孔和由多种流行篡改方法生成的深度伪造。他们在整个视频级别——而不是单帧——上将这些素材划分为五个不同的池,用于训练检测器、微调其设置、选择最佳模型、校准似然比系统和测试。这样的设计避免了“数据泄漏”,即来自同一视频的几乎相同的帧可能意外出现在训练和测试集中,从而让性能数字看起来比实际更好。
将检测器分数转化为证据权重
团队首先比较了几种现代深度伪造检测器,发现基于胶囊网络的模型在不同类型的伪造上提供了最可靠的结果。该模型为每张面部图像输出一个介于零到一之间的分数,数值越高表示对伪造的怀疑越强。作者没有在某个阈值上划出硬性界线,而是对已知真实图像和已知伪造图像的分数分布进行建模。通过平滑技术,他们估计出两条平滑曲线:一条描述真实图像的典型分数,另一条描述伪造图像的典型分数。对于任何新图像,他们询问:这个分数更接近“真实”曲线还是“伪造”曲线?这两种可能性的比值就成为似然比,直接衡量证据强度。
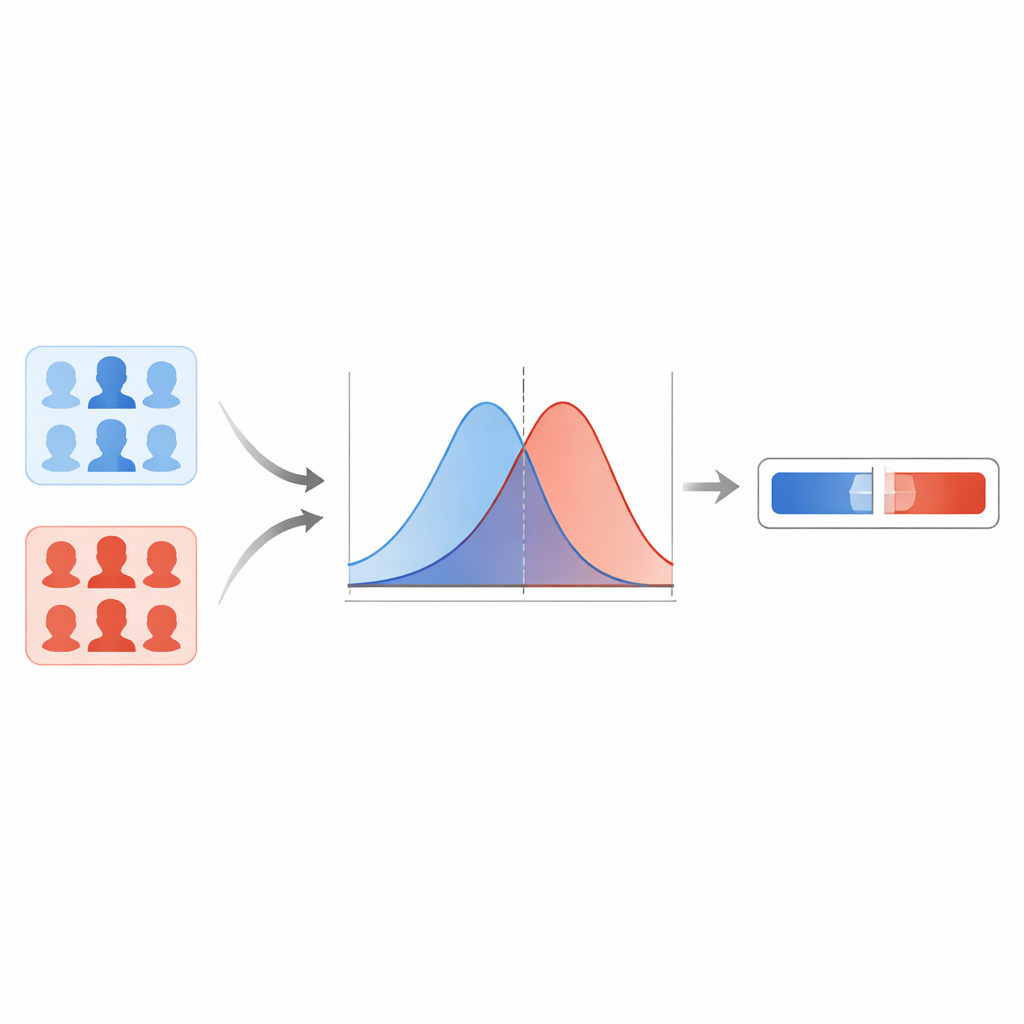
防止过度自信的极端结果
然而,在系统见过很少或没有数据的区域,统计曲线可能表现异常,导致不现实地巨大或微小的似然比。为防止模型给出这种过度自信的结论,研究人员采用了一种称为经验下/上界的方法。实际操作上,他们根据系统在应对“困难”示例时的表现,对允许输出的最极端值进行限制。他们还使用校准步骤来调整原始似然比,使得在大量案例中,报告的证据强度更接近系统实际正确的频率。对 FaceForensics++ 保留部分的测试显示错误率低且指出证据方向错误的情况少,表明在该数据范围内系统表现得比较稳健。
在实验室之外能走多远?
现实世界的案例很少会完美匹配训练数据,因此作者测试了他们的系统在多个独立深度伪造数据集上的表现,这些数据集由不同的演员和生成方法构建。在这些情况下,性能有所下降:系统仍优于随机猜测,但在最具挑战性的数据集上优势并不明显。该系统在新素材与原始 FaceForensics++ 数据相似时表现最好,而在伪造风格发生变化时则表现不佳。这凸显了法医人工智能的一个核心难题:工具不仅需要在方便的基准数据集上验证,还必须在不断变化的深度伪造技术环境中接受更广泛的检验。
这对法院与公众意味着什么
用通俗的话说,这项工作展示了将深度伪造检测器输出转化为一种“证据权重”是可行的,这种表达方式符合法医科学家在处理指纹或 DNA 时的推理方式。在与其训练数据相似的情境中,该系统不仅能给出图像是否为伪造的判断,还能提供经过谨慎校准的关于数据支持该结论强度的说明。与此同时,研究也提醒人们不要过度自信:当方法遇到新类型的深度伪造时,性能可能会减弱。在这些工具被法庭信任之前,需要更广泛的验证并持续更新,以跟上迅速演变的造假手段。
引用: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
关键词: 深度伪造检测, 法医证据, 似然比, 数字图像分析, 法庭技术