Clear Sky Science · ja
法科学におけるディープフェイク画像識別のためのスコアに基づく尤度比フレームワーク
なぜ偽の顔写真は社会全体の問題なのか
顔の入れ替えツールや写真フィルターなど、消費者向けアプリで完璧に本物らしく見える画像や動画を作れるようになりました。いわゆるディープフェイクはもはやインターネットの好奇心の対象にとどまらず、虚偽のニュースを拡散したり、人を詐欺にかけたり、法廷での実際の証拠に疑念を投げかけたりするために使われ得ます。本稿が取り組む問いは、デジタル世界の真実を重視する人なら誰にとっても重要です:「この画像は偽物か?」だけでなく、「裁判官や陪審員が理解できる形で、証拠はどれほど強くそのことを示しているか?」という点です。
はい・いいえから、どれほど確かかへ
現在のディープフェイク検出器の多くは単純な嘘発見器のように振る舞い、画像を読み込み本物か偽物かのラベルを出力し、場合によっては確信度スコアを返します。ソーシャルメディアの一般的なフィルタリングではそれで十分かもしれません。しかし法廷では調査者は二つの対立する主張――「この画像は改ざんされた」対「この画像は本物だ」――を比較し、どちらの主張をどれだけ強く支持するかを説明する必要があります。著者らは、ディープフェイク検出器からの生のスコアを「尤度比」に変換するシステムを構築します。尤度比とは観測された証拠が一方の主張をもう一方よりどれだけ支持するかを数値で表したもので、指紋や筆跡など他の法科学分野ですでに馴染みのある表現です。
実物と偽物の顔による慎重なテストベッドの構築
研究を確かなデータに根ざすために、研究者らは広く使われるデータ集合である FaceForensics++ に依拠します。これは実際の顔と複数の人気のある改変手法で生成されたディープフェイクの両方を含む動画集です。彼らは素材を個々のフレームではなく丸ごとの動画単位で分割し、検出器の学習、パラメータの微調整、モデル選択、尤度比システムの較正、最終テストという五つの異なるプールに振り分けます。この設計により、同じ動画から非常に似たフレームが学習とテストの両方に誤って現れ、性能値が実際より良く見えてしまう「データリーケージ」を避けられます。
検出器スコアを証拠の重みへ変換する
まずチームは複数の最新ディープフェイク検出器を比較し、カプセルベースのネットワークがさまざまな種類の偽物に対して最も安定した結果を出すことを見出します。このモデルは各顔画像に対して0から1のスコアを出力し、値が大きいほど偽造の疑いが強いことを示します。ある閾値で二分する代わりに、著者らは既知の実画像と既知のディープフェイクそれぞれでこれらのスコアがどのように分布するかをモデル化します。平滑化手法を用いて、実画像の典型的なスコアを表す曲線と偽物のスコアを表す曲線の二つの滑らかな関数を推定します。新しい画像に対しては、このスコアが「実物」曲線により典型的か「偽物」曲線により典型的かを問い、その二つの可能性の比が尤度比となり、証拠の強さを直接測る指標になります。
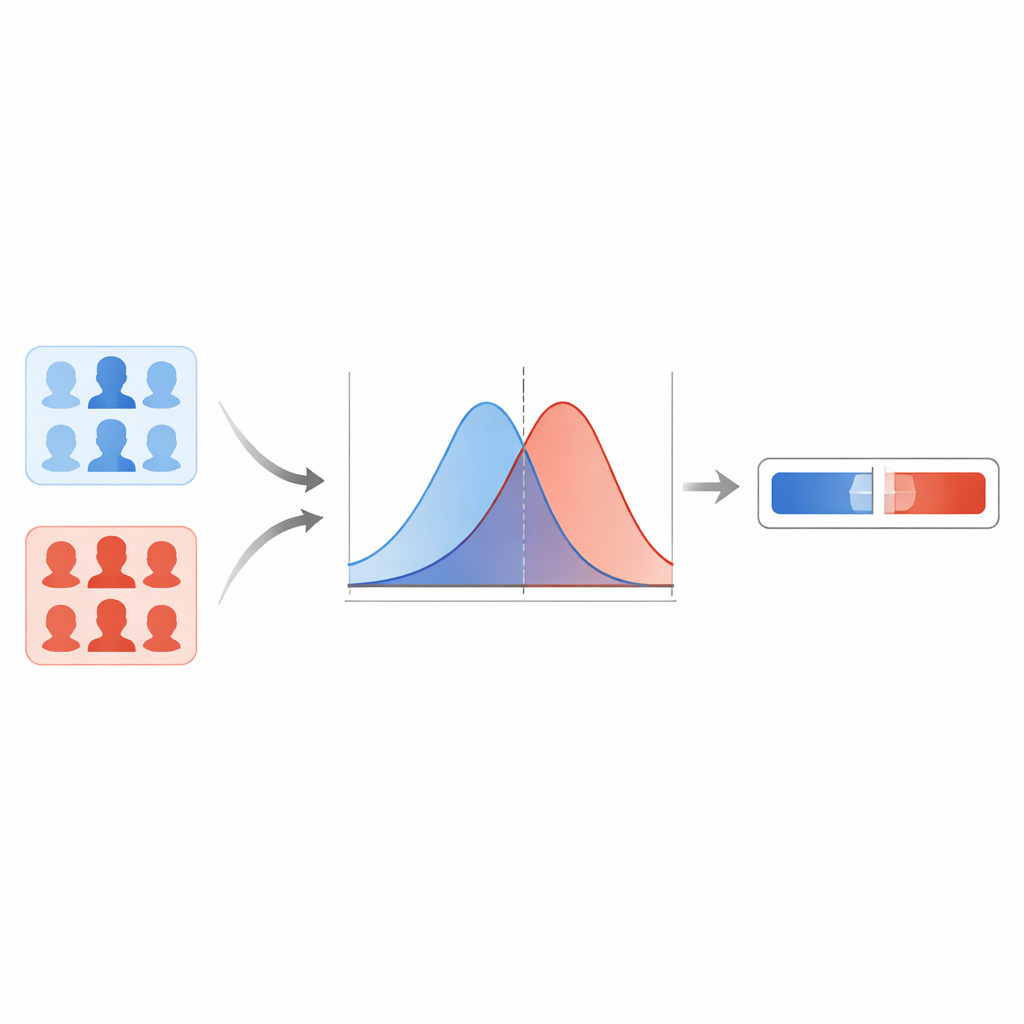
過剰に自信的な極端値への備え
しかし統計的な曲線はデータがほとんどない領域で暴走し、現実離れした巨大または極小の尤度比を生むことがあります。こうした過度に自信的な主張を防ぐために、研究者らは経験的下限・上限という手法を適用します。実務的には、難しい例でシステムを負荷試験したときの振る舞いに基づき、出力できる最も極端な値に上限と下限を設けます。また生の尤度比を調整する較正ステップを用い、多数のケースにおいて報告される証拠の強さが実際に正しい頻度により近づくようにします。FaceForensics++ の保留データに対するテストは低い誤り率と、証拠が誤った方向を示すケースが少ないことを示し、このデータ領域内ではシステムが合理的に振る舞うことを示唆します。
実験室の外でどれほど通用するか?
現実の事例は学習データと完全には一致しないことが多いため、著者らは異なる出演者や生成手法で構築された複数の独立したディープフェイクデータセット上でシステムの性能を検証します。ここでは性能が低下します:ランダムよりは良いものの、最も挑戦的なデータセットでは大きな差を示しません。元の FaceForensics++ データに似た素材ではシステムは最良の性能を示し、偽造のスタイルが変わると苦戦します。これは法科学的人工知能の中心的な困難を浮き彫りにします:ツールは便利なベンチマークデータセットだけでなく、変化し続けるディープフェイク技術の全体像にわたって検証される必要があります。
これが法廷と一般市民に意味すること
日常的な言葉で言えば、本研究はディープフェイク検出器の出力を指紋やDNAの議論に馴染む「証拠の重み」の形式に翻訳することが可能であることを示しています。学習データに類似した状況下では、システムは画像が偽物かどうかの推定だけでなく、その結論を支持するデータの強さを慎重に較正した形で示すことができます。同時に本研究は過信への警告も発しています:新たな種類のディープフェイクに直面すると性能が低下し得ます。こうしたツールが法廷で信頼されるためには、より広範な検証と急速に進化する偽造手法に追随する継続的な更新が必要です。
引用: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
キーワード: ディープフェイク検出, 法科学証拠, 尤度比, デジタル画像解析, 法廷技術