Clear Sky Science · de
Ein auf Scores basierendes Likelihood‑Ratio‑Rahmenwerk zur Identifikation von Deepfake‑Bildern in der forensischen Wissenschaft
Warum gefälschte Gesichter uns alle betreffen
Bilder und Videos, die vollkommen echt aussehen, lassen sich heute mit Konsumenten‑Apps herstellen, von Face‑Swapping‑Tools bis zu Fotofiltern. Diese sogenannten Deepfakes sind nicht länger bloß Internetkuriositäten — sie können genutzt werden, um Falschmeldungen zu verbreiten, Menschen zu betrügen oder echtes Beweismaterial vor Gericht in Zweifel zu ziehen. Dieser Artikel behandelt eine Frage, die für alle wichtig ist, denen Wahrheit in einer digitalen Welt am Herzen liegt: nicht nur „Ist dieses Bild gefälscht?“, sondern „Wie stark sprechen die Beweise dafür, auf eine Weise, die Richter und Jury verstehen können?“
Von Ja‑oder‑Nein‑Antworten zu Wie‑sicher‑sind‑wir‑Aussagen
Die meisten Deepfake‑Detektoren verhalten sich heute wie einfache Lügendetektoren: Sie nehmen ein Bild entgegen und geben ein Etikett aus — echt oder gefälscht — manchmal mit einer Vertrauenszahl. Für die alltägliche Filterung in sozialen Medien mag das genügen. Vor Gericht jedoch müssen Ermittler zwei konkurrierende Hypothesen vergleichen — „dieses Bild ist manipuliert“ versus „dieses Bild ist echt“ — und erklären, wie stark die Daten die eine gegenüber der anderen stützen. Die Autoren entwickeln ein System, das die Rohscores eines Deepfake‑Detektors in eine „Likelihood‑Ratio“ umwandelt: einen numerischen Ausdruck dafür, wie sehr die beobachteten Beweise die eine Geschichte gegenüber der anderen begünstigen, in einer Sprache, die in anderen forensischen Bereichen wie Fingerabdrücken oder Handschriften bereits vertraut ist.
Aufbau eines sorgfältigen Testbestands aus echten und gefälschten Gesichtern
Um ihre Arbeit auf solide Daten zu stützen, nutzen die Forschenden FaceForensics++, eine weit verbreitete Sammlung von Videos mit echten Gesichtern und Deepfakes, die mit mehreren populären Manipulationsverfahren erzeugt wurden. Sie teilen dieses Material auf Ebene kompletter Videos — nicht einzelner Frames — in fünf getrennte Pools für das Training des Detektors, die Feinabstimmung seiner Einstellungen, die Auswahl des besten Modells, die Kalibrierung des Likelihood‑Ratio‑Systems und das Testen. Dieses Design vermeidet „Data Leakage“, also Situationen, in denen nahezu identische Frames desselben Videos versehentlich sowohl im Training als auch im Test auftauchen und die Leistungszahlen besser erscheinen lassen, als sie tatsächlich sind.
Detektor‑Scores in Beweiswürdigung verwandeln
Das Team vergleicht zunächst mehrere moderne Deepfake‑Detektoren und stellt fest, dass ein kapselbasisches Netzwerk über verschiedene Fake‑Typen hinweg die zuverlässigsten Ergebnisse liefert. Dieses Modell gibt für jedes Gesichtsbild einen Score zwischen null und eins aus, wobei höhere Werte stärkeren Verdacht auf Manipulation signalisieren. Anstatt eine harte Grenze bei einem Schwellenwert zu ziehen, modellieren die Autoren, wie sich diese Scores bei bekannten echten Bildern und bekannten Deepfakes verteilen. Mit einer Glättungstechnik schätzen sie zwei glatte Kurven: eine, die typische Scores für echte Bilder beschreibt, und eine für Fakes. Bei einem neuen Bild fragen sie dann: Ist dieser Score eher typisch für die „echt“-Kurve oder für die „gefälscht“-Kurve? Das Verhältnis dieser beiden Möglichkeiten ergibt die Likelihood‑Ratio, ein direktes Maß für die Beweisstärke.
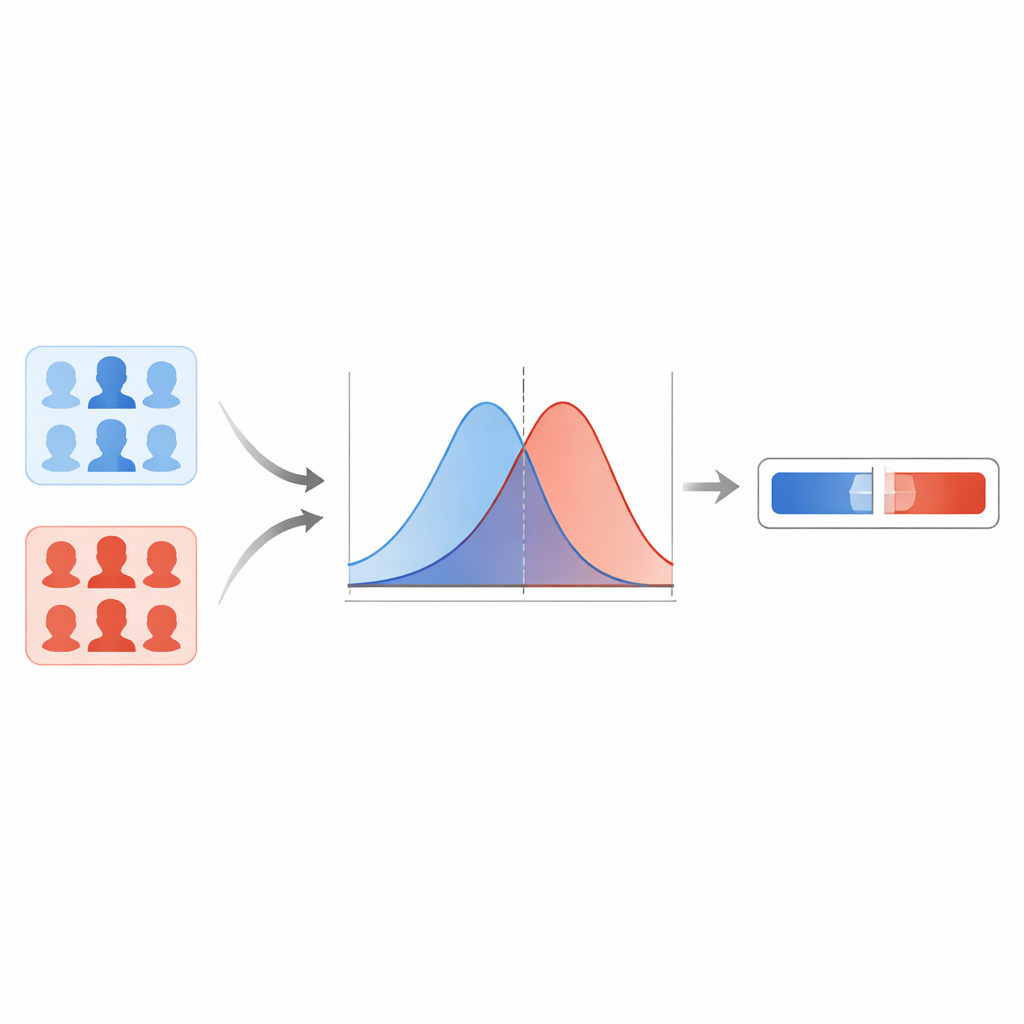
Absicherung gegen übermäßig selbstsichere Extreme
Statistische Kurven können sich jedoch in Bereichen fehlverhalten, in denen das System wenig oder keine Daten gesehen hat, was zu unrealistisch großen oder winzigen Likelihood‑Ratios führen kann. Um zu verhindern, dass das Modell derartige übermäßige Selbstsicherheit behauptet, wenden die Forschenden eine Methode mit empirischen unteren und oberen Grenzen an. Praktisch bedeutet das, dass sie die extremsten Werte, die das System ausgeben darf, anhand seiner Leistung bei „schwierigen“ Beispielen begrenzen. Außerdem nutzen sie einen Kalibrierungsschritt, der die rohen Likelihood‑Ratios so anpasst, dass sich über viele Fälle hinweg die berichtete Beweisstärke eher mit der echten Trefferquote deckt. Tests am zurückgehaltenen Teil von FaceForensics++ zeigen niedrige Fehlerquoten und wenige Fälle, in denen die Beweise in die falsche Richtung deuten, was darauf hindeutet, dass das System sich innerhalb dieses Datenuniversums sinnvoll verhält.
Wie gut funktioniert es außerhalb des Labors?
Reale Fälle werden selten perfekt mit den Trainingsdaten übereinstimmen, daher prüfen die Autoren, wie ihr System auf mehreren unabhängigen Deepfake‑Datensätzen abschneidet, die mit anderen Darstellern und Erzeugungsmethoden erstellt wurden. Hier fällt die Leistung ab: Sie liegt zwar weiterhin über dem Zufallsniveau, aber nicht weit darüber bei den herausforderndsten Datensätzen. Das System arbeitet am besten, wenn das neue Material dem ursprünglichen FaceForensics++‑Datensatz ähnelt, und hat Schwierigkeiten, wenn sich der Stil der Fälschung ändert. Das hebt eine zentrale Schwierigkeit in der forensischen künstlichen Intelligenz hervor: Werkzeuge müssen nicht nur an praktischen Benchmark‑Datensätzen validiert werden, sondern über die sich wandelnde Landschaft der Deepfake‑Technologie hinweg geprüft werden.
Was das für Gerichte und die Öffentlichkeit bedeutet
Einfach ausgedrückt zeigt diese Arbeit, dass es möglich ist, die Ausgabe von Deepfake‑Detektoren in eine Form von „Beweisgewicht“ zu übersetzen, die dem Denken forensischer Wissenschaftler bei Fingerabdrücken oder DNA entspricht. In Umgebungen, die den Trainingsdaten ähneln, kann das System nicht nur eine Einschätzung liefern, ob ein Bild gefälscht ist, sondern auch eine vorsichtig kalibrierte Aussage darüber, wie stark die Daten diese Schlussfolgerung stützen. Gleichzeitig warnt die Studie vor übermäßiger Zuversicht: Die Leistung kann schwächer werden, wenn die Methode auf neue Arten von Deepfakes trifft. Bevor solche Werkzeuge in Gerichtssälen vertrauenswürdig eingesetzt werden, brauchen sie breitere Validierung und ständige Aktualisierung, um mit den sich schnell entwickelnden Methoden der Fälschung Schritt zu halten.
Zitation: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Schlüsselwörter: Deepfake‑Erkennung, forensische Beweise, Likelihood‑Ratio, digitale Bildanalyse, Gerichtstechnik