Clear Sky Science · ru
Рамочная модель отношения правдоподобия на основе оценок для идентификации дипфейков в судебной экспертизе
Почему поддельные лица — проблема для всех
Изображения и видео, выглядящие совершенно реальными, теперь можно создавать с помощью потребительских приложений — от инструментов подмены лица до фотофильтров. Эти так называемые дипфейки перестали быть просто интернет-курьёзами: их используют для распространения фейковых новостей, мошенничества или для посева сомнений в подлинности доказательств в суде. В этой работе рассматривается вопрос, важный для всех, кто заботится о правде в цифровом мире: не только «Это изображение поддельное?», но и «Насколько сильно доказательства указывают на это, в форме, понятной судье и присяжным?»
От ответов «да/нет» к степени уверенности
Большинство современных детекторов дипфейков ведут себя как простые детекторы лжи: они принимают изображение и выдают метку — настоящее или поддельное, иногда с указанием уровня уверенности. Для фильтрации в соцсетях этого может быть достаточно. Но в суде экспертам приходится сравнивать две конкурирующие версии — «это изображение подделано» против «это изображение подлинное» — и объяснять, насколько сильно данные поддерживают одну из них. Авторы предлагают систему, которая переводит сырые оценки детектора дипфейков в «отношение правдоподобия»: численное выражение того, насколько наблюдаемое доказательство скорее соответствует одной версии, чем другой — язык, уже знакомый экспертам по отпечаткам пальцев или почерку.
Создание аккуратной тестовой базы реальных и поддельных лиц
Чтобы опираться на надёжные данные, исследователи используют FaceForensics++, широко распространённую коллекцию видеозаписей с настоящими лицами и дипфейками, сгенерированными несколькими популярными методами манипуляции. Они разделяют материалы на уровне целых видео — а не отдельных кадров — на пять отдельных пулов для обучения детектора, тонкой настройки параметров, выбора лучшей модели, калибровки системы отношений правдоподобия и тестирования. Такая схема предотвращает «утечку данных», когда почти идентичные кадры из одного и того же видео случайно попадают и в обучение, и в тестирование, что искажает оценку производительности.
Преобразование оценок детектора в вес доказательства
Команда сначала сравнивает несколько современных детекторов дипфейков и обнаруживает, что капсульная сеть даёт наиболее надёжные результаты на разных типах подделок. Эта модель выдаёт оценку от нуля до единицы для каждого изображения лица, при этом большие значения сигнализируют о большей подозрительности в подделке. Вместо жёсткого порога авторы моделируют распределение этих оценок для известных реальных изображений и известных дипфейков. С применением метода сглаживания они оценивают две плавные кривые: одну, описывающую типичные оценки для реальных изображений, другую — для подделок. Для любого нового изображения они спрашивают: более ли характерна эта оценка для «реальной» кривой или для «поддельной»? Отношение между этими двумя вероятностями становится отношением правдоподобия — прямой мерой силы доказательства.
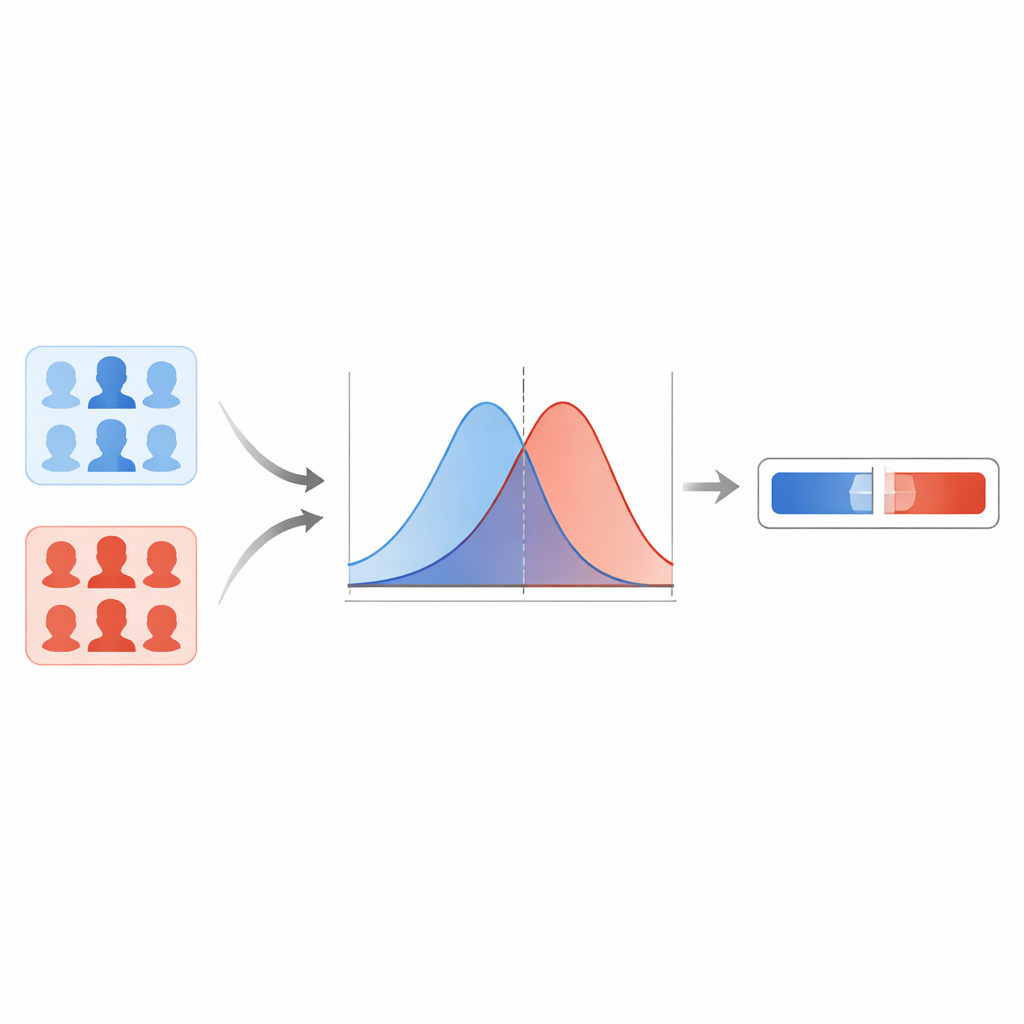
Защита от чрезмерно уверенных экстремумов
Однако статистические кривые могут вести себя ненадёжно в областях, где система видела мало или совсем не видела данных, что приводит к нереалистично огромным или крошечным значениям отношения правдоподобия. Чтобы предотвратить такие чрезмерно уверенные утверждения, исследователи применяют метод эмпирических нижних и верхних границ. На практике они ограничивают самые экстремальные значения, которые система может выдавать, исходя из её поведения при стресс-тестах на «трудных» примерах. Также используется этап калибровки, который корректирует сырые отношения правдоподобия так, чтобы в среднем по множеству случаев заявляемая сила доказательства лучше соответствовала тому, как часто система действительно оказывается права. Испытания на отложенной части FaceForensics++ показывают низкие показатели ошибок и мало случаев, когда доказательства указывают в неверном направлении, что говорит о разумном поведении системы в пределах этой выборки данных.
Насколько это работает за пределами лаборатории?
Реальные случаи редко полностью совпадают с данными обучения, поэтому авторы проверяют, как их система ведёт себя на нескольких независимых наборах дипфейков, созданных с другими актёрами и методами генерации. Здесь её производительность снижается: она по-прежнему лучше случайного угадывания, но не с большим отрывом на самых сложных наборах. Система работает лучше, когда новый материал похож на исходные данные FaceForensics++, и испытывает трудности, когда стиль подделки меняется. Это подчёркивает ключевую проблему судебного ИИ: инструменты нужно валидировать не только на удобных эталонных наборах, но и в условиях постоянно меняющегося ландшафта технологий дипфейков.
Что это означает для судов и общества
В практическом плане эта работа показывает, что можно перевести вывод детектора дипфейков в форму «веса доказательства», близкую к тому, как судебные эксперты уже оценивают отпечатки или ДНК. В условиях, похожих на данные обучения, система может дать не только предположение о том, является ли изображение поддельным, но и осторожно откалиброванное утверждение о том, насколько сильно данные поддерживают этот вывод. В то же время исследование предупреждает об излишней уверенности: при встрече с новыми видами дипфейков производительность может ослабевать. Прежде чем такие инструменты начнут использоваться в залах суда, их нужно будет шире валидировать и постоянно обновлять, чтобы поспевать за быстро меняющимися способами подделки реальности.
Цитирование: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Ключевые слова: обнаружение дипфейков, судебные доказательства, отношение правдоподобия, анализ цифровых изображений, технологии для зала суда