Clear Sky Science · en
A score based likelihood ratio framework for deepfake image identification in forensic science
Why Fake Faces Are Everyone’s Problem
Images and videos that look perfectly real can now be fabricated with consumer apps, from face-swapping tools to photo filters. These so‑called deepfakes are no longer just internet curiosities—they can be used to spread false news, defraud people, or cast doubt on real evidence in court. This paper tackles a question that matters to anyone who cares about truth in a digital world: not just "Is this picture fake?" but "How strongly does the evidence say so, in a way a judge and jury can understand?"
From Yes-or-No Answers to How-Sure-Are-We
Most deepfake detectors today behave like simple lie‑detectors: they take in an image and spit out a label, real or fake, sometimes with a confidence score. For everyday filtering on social media, that might be enough. But in a courtroom, investigators must compare two competing stories—"this image is forged" vs. "this image is genuine"—and explain how strongly the data support one over the other. The authors build a system that converts the raw scores from a deepfake detector into a "likelihood ratio": a numerical expression of how much more the observed evidence favors one story than the other, a language already familiar in other forensic areas such as fingerprints and handwriting.
Building a Careful Test Bed of Real and Fake Faces
To ground their work in solid data, the researchers rely on FaceForensics++, a widely used collection of videos showing both real faces and deepfakes generated by several popular manipulation methods. They split this material at the level of entire videos—rather than individual frames—into five distinct pools for training the detector, fine‑tuning its settings, choosing the best model, calibrating the likelihood‑ratio system, and testing it. This design avoids "data leakage," where nearly identical frames from the same video could accidentally appear in both training and testing, making performance numbers look better than they truly are.
Turning Detector Scores into Weight-of-Evidence
The team first compares several modern deepfake detectors and finds that a capsule‑based network provides the most reliable results across different types of fakes. This model outputs a score between zero and one for each face image, with higher values signaling a stronger suspicion of fakery. Instead of drawing a hard line at some threshold, the authors model how these scores are distributed for known real images and known deepfakes. Using a smoothing technique, they estimate two smooth curves: one describing typical scores for real images, the other for fakes. For any new image, they then ask: is this score more typical of the "real" curve or the "fake" curve? The ratio between those two possibilities becomes the likelihood ratio, a direct measure of evidential strength.
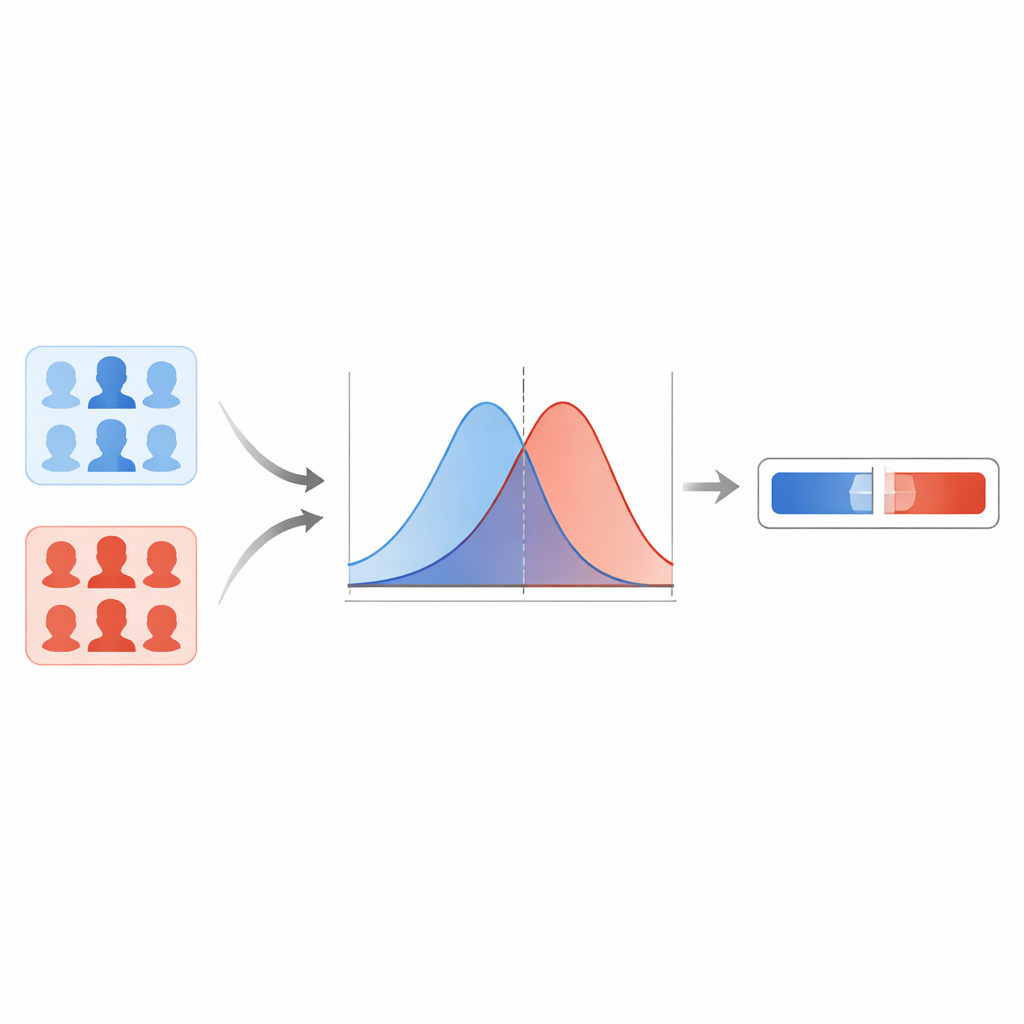
Guarding Against Overconfident Extremes
However, statistical curves can misbehave in regions where the system has seen little or no data, leading to unrealistically huge or tiny likelihood ratios. To prevent the model from making such overconfident claims, the researchers apply a method called empirical lower and upper bounds. In practical terms, they cap the most extreme values the system is allowed to output based on how it performs when stressed with "difficult" examples. They also use a calibration step that adjusts the raw likelihood ratios so that, over many cases, the reported strength of evidence more closely matches how often the system is actually right. Tests on the held‑out part of FaceForensics++ show low error rates and few cases where the evidence points in the wrong direction, suggesting that the system behaves sensibly within that data universe.
How Well Does It Travel Beyond the Lab?
Real‑world cases will rarely match the training data perfectly, so the authors probe how their system fares on several independent deepfake datasets built with different actors and generation methods. Here, its performance drops: it still does better than random guessing, but not by a wide margin on the most challenging sets. The system works best when the new material resembles the original FaceForensics++ data and struggles when the style of fakery changes. This highlights a central difficulty in forensic artificial intelligence: tools must be validated not only on convenient benchmark datasets but also across the shifting landscape of deepfake technology.
What This Means for Courts and the Public
In everyday terms, this work shows it is possible to translate deepfake detector output into a form of "weight of evidence" that fits how forensic scientists already reason about fingerprints or DNA. Within settings similar to its training data, the system can provide not only a guess about whether an image is fake, but also a cautiously calibrated statement of how strongly the data support that conclusion. At the same time, the study warns against overconfidence: performance can weaken when the method meets new kinds of deepfakes. Before such tools are trusted in courtrooms, they will need broader validation and continual updating to keep pace with rapidly evolving ways of faking reality.
Citation: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Keywords: deepfake detection, forensic evidence, likelihood ratio, digital image analysis, courtroom technology