Clear Sky Science · tr
Adli bilimde deepfake görüntü tanımlaması için skor tabanlı bir olasılık oranı çerçevesi
Sahte Yüzler Neden Herkesin Sorunu?
Yüz değiştirme araçlarından fotoğraf filtrelerine kadar tüketici uygulamalarıyla artık kusursuz gerçekçi görünen görüntüler ve videolar üretilebiliyor. Sözde deepfake’ler artık sadece internet merakı değil—yanlış haber yaymak, insanları dolandırmak veya mahkemede gerçek delillere gölge düşürmek için kullanılabiliyorlar. Bu makale, dijital bir dünyada gerçeğe önem veren herkes için anlamı olan bir soruya odaklanıyor: yalnızca “Bu fotoğraf sahte mi?” değil, aynı zamanda “Deliller bunu ne kadar güçlü bir biçimde söylüyor; bir hâkim ve jüri anlayacak şekilde nasıl ifade edilir?”
Evet‑Hayır Yanıtlarından Ne Kadar Eminiz’e
Günümüzde çoğu deepfake algılama aracı basit bir yalancılık test cihazı gibi davranıyor: bir görüntü alıyor ve gerçek ya da sahte etiketini, bazen bir güven skoru ile birlikte çıktılıyor. Sosyal medyada günlük filtreleme için bu yeterli olabilir. Ancak bir mahkemede, soruşturmacıların iki rakip hikâyeyi—“bu görüntü sahte” vs. “bu görüntü gerçek”—karşılaştırması ve verilerin birini diğerine ne kadar desteklediğini açıklaması gerekir. Yazarlar, bir deepfake algılayıcının ham skorlarını bir "olasılık oranı"na dönüştüren bir sistem inşa ediyor: gözlenen delilin bir hikâyeyi diğerine göre ne kadar daha çok desteklediğini sayısal olarak ifade eden ve parmak izi veya el yazısı gibi adli alanlarda zaten tanıdık olan bir dil.
Gerçek ve Sahte Yüzlerden Oluşan Titiz Bir Test Yatağı Kurmak
Çalışmalarını sağlam verilere dayandırmak için araştırmacılar, hem gerçek yüzleri hem de birkaç popüler manipülasyon yöntemiyle üretilmiş deepfake’leri içeren yaygın kullanılan FaceForensics++ koleksiyonuna güveniyorlar. Bu materyali, tek tek kareler yerine tüm videolar düzeyinde beş ayrı havuza ayırıyorlar: algılayıcıyı eğitme, ayarlarını ince ayarlama, en iyi modeli seçme, olasılık oranı sistemini kalibre etme ve testi yapma. Bu tasarım, aynı videodan neredeyse özdeş karelerin kazara hem eğitim hem testte yer alabileceği ve böylece performans sayılarını olduğundan daha iyi gösterme riskini önlüyor.
Algılayıcı Skorlarını Delil Ağırlığına Çevirmek
Ekip önce birkaç modern deepfake algılayıcısını karşılaştırıyor ve kapsül tabanlı bir ağın farklı sahte türlerinde en güvenilir sonuçları verdiğini tespit ediyor. Bu model her yüz görüntüsü için sıfır ile bir arasında bir skor üretiyor; daha yüksek değerler sahte olma şüphesinin daha güçlü olduğunu işaret ediyor. Bir eşik değerinde sert bir çizgi çekmek yerine, yazarlar bu skorların bilinen gerçek görüntüler ve bilinen deepfake’ler için nasıl dağıldığını modelliyor. Bir düzleştirme tekniği kullanarak iki düzgün eğri tahmin ediyorlar: biri gerçek görüntüler için tipik skorları, diğeri sahte görüntüler için tipik skorları tanımlıyor. Her yeni görüntü için soruyorlar: bu skor "gerçek" eğrisine mi yoksa "sahte" eğrisine mi daha tipik? Bu iki olasılık arasındaki oran olasılık oranı oluyor; delilin gücünün doğrudan bir ölçüsü.
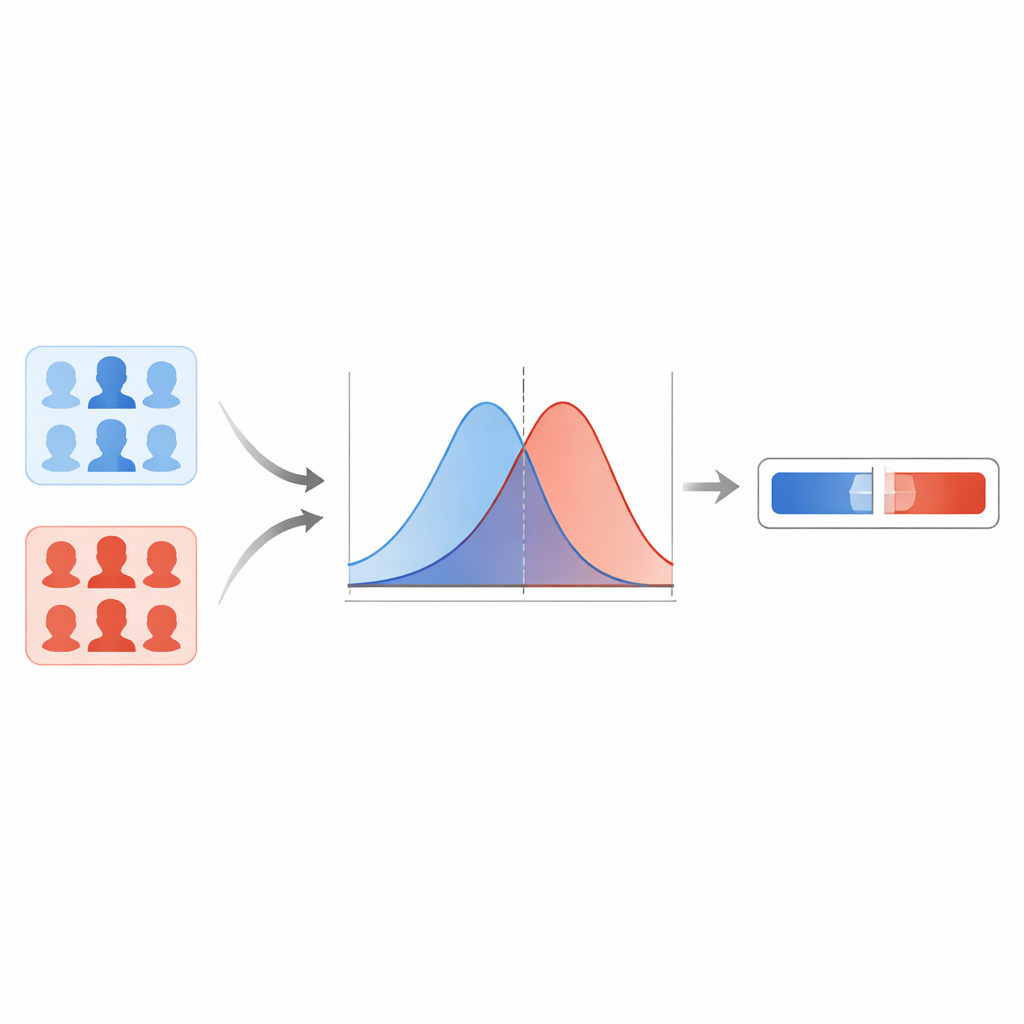
Aşırı Kendinden Eminliklere Karşı Koruma
Ancak, sistemin az veya hiç veri görmediği bölgelerde istatistiksel eğriler yanlış davranabilir ve gerçekçi olmayan derecede büyük veya küçük olasılık oranlarına yol açabilir. Modelin böyle aşırı kendinden emin iddialar yapmasını önlemek için araştırmacılar ampirik alt ve üst sınırlar adı verilen bir yöntem uyguluyorlar. Pratikte, sistemin üretebileceği en uç değerleri, "zor" örneklerle zorlandığında nasıl performans gösterdiğine göre sınırlandırıyorlar. Ayrıca ham olasılık oranlarını, birçok vaka üzerinden rapor edilen delil gücünün sistemin gerçekte ne sıklıkla doğru olduğuna daha yakın olması için ayarlayan bir kalibrasyon adımı kullanıyorlar. FaceForensics++’ın ayrılmış bölümünde yapılan testler düşük hata oranları ve yanlış yönlendiren delil vakalarının az olduğunu gösteriyor; bu da sistemin o veri evreni içinde makul davrandığını gösteriyor.
Pardaki Laboratuvarın Dışına Ne Kadar Uygulanabilir?
Gerçek dünya vakaları nadiren eğitim verileriyle tam olarak örtüşür, bu yüzden yazarlar sistemlerini farklı aktörler ve üretim yöntemleriyle oluşturulmuş çeşitli bağımsız deepfake veri setlerinde sınamışlar. Burada performans düşüyor: rastgele tahminden hâlâ daha iyi sonuç verse de en zorlu setlerde geniş bir farkla değil. Sistem, yeni materyal orijinal FaceForensics++ verisine benzediğinde en iyi şekilde çalışıyor ve sahteliğin tarzı değiştiğinde zorlanıyor. Bu, adli yapay zekâdaki temel bir zorluğu vurguluyor: araçların yalnızca uygun kıyas veri setlerinde değil, aynı zamanda deepfake teknolojisinin değişen manzarasında da doğrulanması gerekiyor.
Bu Mahkemeler ve Kamu İçin Ne Anlama Geliyor?
Günlük ifadeyle, bu çalışma deepfake algılayıcı çıktısını parmak izi veya DNA konusunda adli bilimcilerin zaten kullandığı türde bir "delil ağırlığı" biçimine çevirmenin mümkün olduğunu gösteriyor. Eğitim verilerine benzer ortamlarda sistem, bir görüntünün sahte olup olmadığına dair bir tahmin sağlamanın yanı sıra verilerin bu sonuca ne kadar güçlü destek verdiğine dair temkinli bir şekilde kalibre edilmiş bir açıklama da sunabilir. Aynı zamanda çalışma aşırı güvene karşı uyarıyor: yöntem yeni tür deepfake’lerle karşılaştığında performans zayıflayabiliyor. Bu tür araçlar mahkemelerde güvenilir kabul edilmeden önce daha geniş doğrulamalardan geçirilmeli ve gerçeği sahtelemenin hızla evrilen yollarına ayak uydurmak için sürekli güncellenmelidir.
Atıf: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Anahtar kelimeler: deepfake tespiti, adli delil, olasılık oranı, dijital görüntü analizi, mahkeme teknolojisi