Clear Sky Science · it
Un quadro basato su rapporti di verosimiglianza per l'identificazione di immagini deepfake nella scienza forense
Perché i volti falsi riguardano tutti
Immagini e video che sembrano perfettamente reali possono ora essere fabbricati con app di uso comune, da strumenti di scambio dei volti a filtri fotografici. Questi cosiddetti deepfake non sono più semplici curiosità di internet: possono essere usati per diffondere notizie false, frodare persone o mettere in dubbio prove reali in tribunale. Questo articolo affronta una domanda che interessa chiunque tenga alla verità nel mondo digitale: non solo «Questa foto è falsa?», ma «Quanto fortemente le prove indicano ciò, in un modo che un giudice e una giuria possano comprendere?»
Dalle risposte sì/no a quanto ne siamo sicuri
La maggior parte dei rilevatori di deepfake oggi si comporta come semplici rilevatori di menzogne: ricevono un'immagine e restituiscono un'etichetta, reale o falsa, talvolta con un punteggio di confidenza. Per il filtraggio quotidiano sui social media questo può bastare. Ma in aula gli investigatori devono confrontare due storie concorrenti—«questa immagine è contraffatta» vs. «questa immagine è genuina»—e spiegare quanto i dati favoriscono l'una rispetto all'altra. Gli autori realizzano un sistema che converte i punteggi grezzi di un rilevatore di deepfake in un "rapporto di verosimiglianza": un'espressione numerica di quanto l'evidenza osservata favorisca un'ipotesi rispetto all'altra, un linguaggio già familiare in altri ambiti forensi come le impronte digitali e la grafologia.
Costruire un banco di prova accurato di volti reali e falsi
Per radicare il proprio lavoro in dati solidi, i ricercatori si basano su FaceForensics++, una raccolta ampiamente utilizzata di video che mostra sia volti reali sia deepfake generati con diversi metodi di manipolazione popolari. Suddividono questo materiale a livello di video interi—piuttosto che di singoli fotogrammi—in cinque pool distinti per addestrare il rilevatore, perfezionarne i parametri, scegliere il modello migliore, calibrare il sistema di rapporti di verosimiglianza e testarlo. Questa progettazione evita la "perdita di dati", in cui fotogrammi quasi identici dello stesso video potrebbero apparire per errore sia nell'addestramento sia nei test, facendo apparire le prestazioni migliori di quanto siano realmente.
Trasformare i punteggi del rilevatore in peso della prova
Il team confronta prima diversi rilevatori moderni di deepfake e trova che una rete basata su capsule fornisce i risultati più affidabili attraverso diversi tipi di falsificazioni. Questo modello fornisce un punteggio compreso tra zero e uno per ogni immagine del volto, con valori più elevati che indicano una maggiore sospetta falsità. Invece di tracciare una linea netta su una soglia, gli autori modellano come questi punteggi si distribuiscono per immagini note reali e per deepfake noti. Utilizzando una tecnica di lisciamento, stimano due curve fluide: una che descrive i punteggi tipici per le immagini reali e l'altra per i falsi. Per una nuova immagine, si chiede quindi: questo punteggio è più tipico della curva "reale" o della curva "falsa"? Il rapporto tra queste due possibilità diventa il rapporto di verosimiglianza, una misura diretta della forza probatoria.
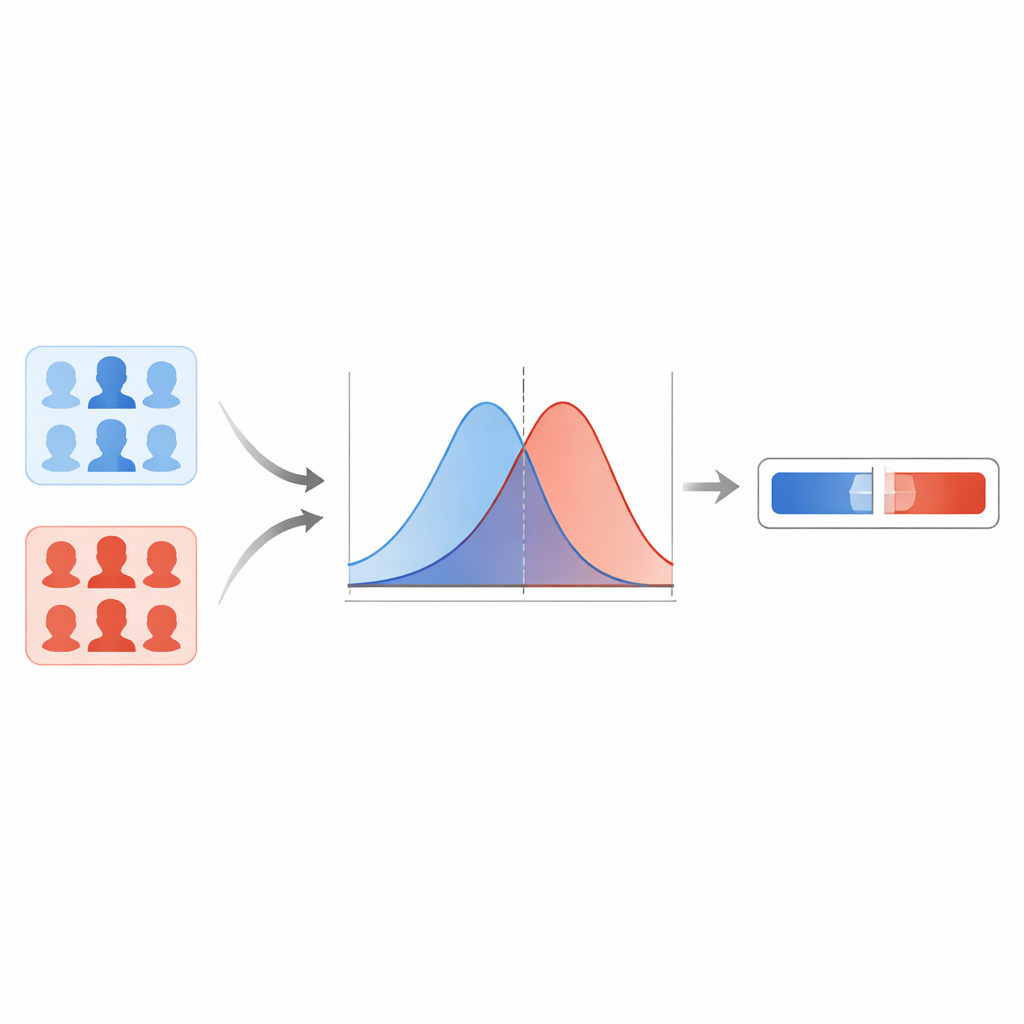
Proteggersi dagli estremi troppo sicuri
Tuttavia, le curve statistiche possono comportarsi male nelle regioni dove il sistema ha visto pochi o nessun dato, portando a rapporti di verosimiglianza irrealisticamente grandi o piccoli. Per impedire al modello di fare affermazioni troppo sicure, i ricercatori applicano un metodo chiamato limiti empirici inferiori e superiori. In termini pratici, pongono un tetto ai valori più estremi che il sistema può restituire basandosi su come si comporta quando è stressato con esempi "difficili". Usano anche un passaggio di calibrazione che aggiusta i rapporti di verosimiglianza grezzi affinché, su molti casi, la forza di prova riportata corrisponda più da vicino a quanto spesso il sistema risulta effettivamente corretto. I test sulla parte tenuta fuori di FaceForensics++ mostrano tassi di errore bassi e pochi casi in cui le prove puntano nella direzione sbagliata, suggerendo che il sistema si comporta in modo sensato entro quell'universo di dati.
Quanto bene si comporta fuori dal laboratorio?
I casi del mondo reale raramente corrispondono perfettamente ai dati di addestramento, quindi gli autori indagano come il loro sistema si comporta su diversi dataset indipendenti di deepfake costruiti con attori e metodi di generazione differenti. Qui, le prestazioni calano: il sistema fa comunque meglio di un'ipotesi casuale, ma non con un margine ampio sui set più impegnativi. Il sistema funziona meglio quando il nuovo materiale somiglia ai dati originali di FaceForensics++ e fatica quando lo stile della falsificazione cambia. Questo mette in luce una difficoltà centrale nell'intelligenza artificiale forense: gli strumenti devono essere convalidati non solo su dataset di riferimento comodi, ma anche attraverso il paesaggio in continuo mutamento della tecnologia deepfake.
Cosa significa per i tribunali e per il pubblico
In termini pratici, questo lavoro mostra che è possibile tradurre l'output di un rilevatore di deepfake in una forma di "peso della prova" che si adatta al modo in cui gli scienziati forensi già ragionano su impronte digitali o DNA. In contesti simili ai dati di addestramento, il sistema può fornire non solo un'ipotesi sul fatto che un'immagine sia falsa, ma anche una dichiarazione cautamente calibrata di quanto i dati supportino quella conclusione. Allo stesso tempo, lo studio mette in guardia contro l'eccessiva fiducia: le prestazioni possono indebolirsi quando il metodo incontra nuovi tipi di deepfake. Prima che tali strumenti vengano ritenuti affidabili in aula, saranno necessarie convalide più ampie e aggiornamenti continui per tenere il passo con i modi in rapida evoluzione di falsificare la realtà.
Citazione: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Parole chiave: rilevamento deepfake, prove forensi, rapporto di verosimiglianza, analisi di immagini digitali, tecnologia in aula