Clear Sky Science · nl
Een op scores gebaseerde likelihood-ratio-kader voor deepfake-beeldidentificatie in de forensische wetenschap
Waarom valse gezichten ieders probleem zijn
Beelden en video's die er volkomen echt uitzien kunnen nu met consumententoepassingen worden gefabriceerd, van gezichtsswitch‑tools tot fotofilters. Deze zogenaamde deepfakes zijn niet langer slechts internetcuriositeiten—ze kunnen worden gebruikt om valse nieuwsberichten te verspreiden, mensen te bedriegen of twijfel te zaaien over echt bewijs in de rechtszaal. Dit artikel pakt een vraag aan die van belang is voor iedereen die om de waarheid in een digitale wereld geeft: niet alleen "Is deze afbeelding nep?" maar "Hoe sterk spreken de aanwijzingen daarvoor, op een manier die een rechter en jury kunnen begrijpen?"
Van ja‑of‑nee-antwoorden naar hoe zeker zijn we
De meeste deepfake-detectoren van vandaag functioneren als eenvoudige leugendetectoren: ze nemen een afbeelding en geven een label terug, echt of nep, soms met een vertrouwensscore. Voor alledaagse filtering op sociale media is dat misschien voldoende. Maar in een rechtszaak moeten onderzoekers twee concurrerende verhalen vergelijken—"deze afbeelding is vervalst" versus "deze afbeelding is echt"—en uitleggen hoe sterk de gegevens het ene verhaal boven het andere ondersteunen. De auteurs bouwen een systeem dat de ruwe scores van een deepfake-detector omzet in een "likelihood-ratio": een numerieke uitdrukking van hoeveel de waargenomen aanwijzingen het ene verhaal meer ondersteunen dan het andere, een taal die al vertrouwd is in andere forensische gebieden zoals vingerafdrukken en handschriftonderzoek.
Het opzetten van een zorgvuldig testplatform van echte en valse gezichten
Om hun werk op degelijke data te baseren, vertrouwen de onderzoekers op FaceForensics++, een veelgebruikte verzameling video's die zowel echte gezichten als deepfakes bevat die door verschillende populaire manipulatiemethoden zijn gegenereerd. Zij splitsen dit materiaal op het niveau van volledige video's—niet individuele frames—in vijf aparte verzamelingen voor het trainen van de detector, het fijnregelen van instellingen, het kiezen van het beste model, het kalibreren van het likelihood-ratio-systeem en het testen ervan. Dit ontwerp voorkomt "data leakage", waarbij vrijwel identieke frames uit dezelfde video per ongeluk zowel in training als in test kunnen voorkomen, waardoor de prestatiecijfers er beter uitzien dan ze in werkelijkheid zijn.
Detector-scores omzetten in bewijskracht
Het team vergelijkt eerst meerdere moderne deepfake-detectoren en vindt dat een capsule-gebaseerd netwerk de meest betrouwbare resultaten levert over verschillende typen vervalsingen heen. Dit model geeft voor elke gezichtsafbeelding een score tussen nul en één, waarbij hogere waarden een sterkere verdenking van vervalsing aangeven. In plaats van een harde grens bij een drempel te trekken, modelleren de auteurs hoe deze scores verdeeld zijn voor bekende echte afbeeldingen en bekende deepfakes. Met een gladstrijktechniek schatten ze twee vloeiende krommen: één die typische scores voor echte afbeeldingen beschrijft en één voor fakes. Voor een nieuwe afbeelding vragen ze vervolgens: is deze score meer typisch voor de "echte" kromme of voor de "nep"-kromme? De verhouding tussen die twee mogelijkheden wordt de likelihood-ratio, een directe maat voor de bewijskracht.
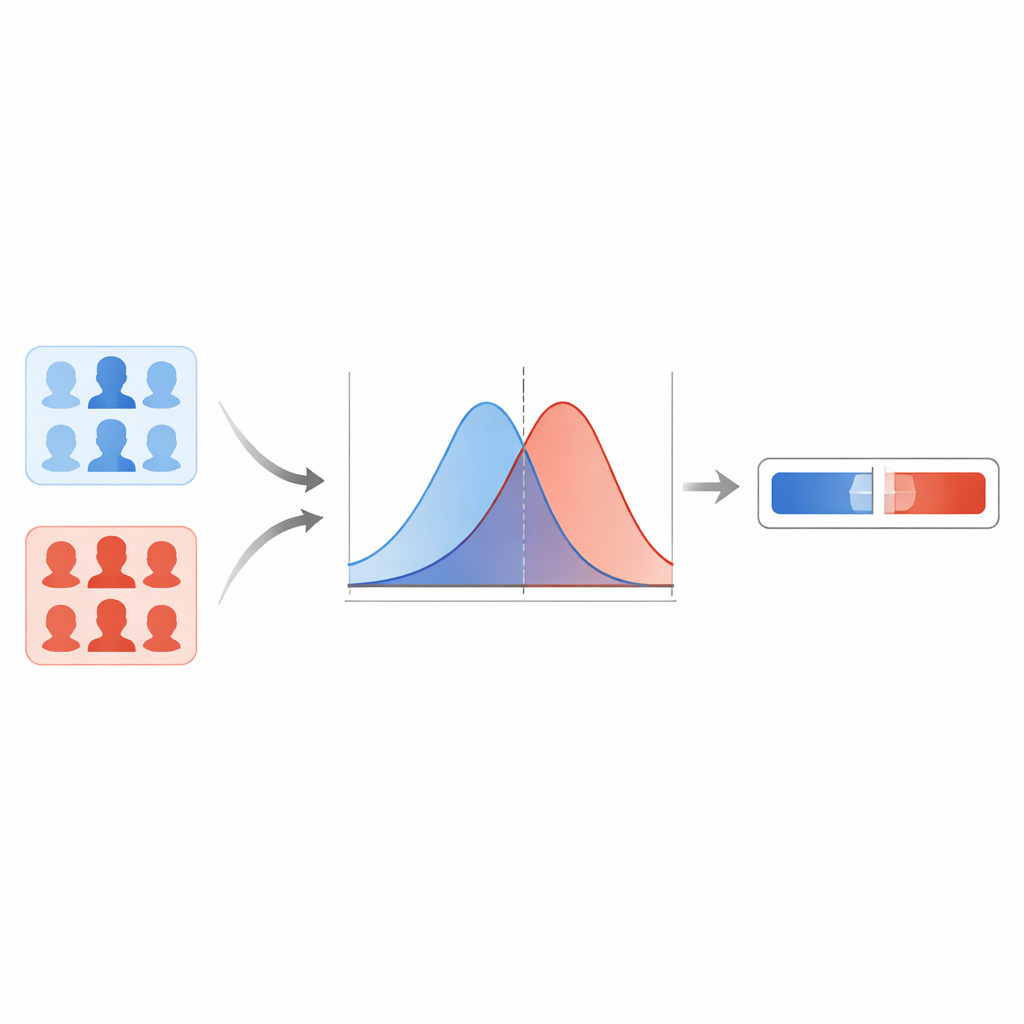
Bescherming tegen overmatig zelfverzekerde extremen
Statistische krommen kunnen echter verkeerde waarden geven in gebieden waar het systeem weinig of geen data heeft gezien, wat leidt tot onrealistisch grote of kleine likelihood-ratio's. Om te voorkomen dat het model zulke overmoedige uitspraken doet, passen de onderzoekers een methode toe die empirische onder- en bovengrenzen gebruikt. Praktisch gezien begrenzen ze de meest extreme waarden die het systeem mag uitgeven op basis van hoe het presteert wanneer het wordt belast met "moeilijke" voorbeelden. Ze gebruiken ook een kalibratiestap die de ruwe likelihood-ratio's aanpast zodat, over veel gevallen, de gerapporteerde bewijskracht beter overeenkomt met hoe vaak het systeem in werkelijkheid gelijk heeft. Tests op het achtergehouden deel van FaceForensics++ tonen lage foutpercentages en weinig gevallen waar het bewijs de verkeerde richting aanwijst, wat erop wijst dat het systeem zich redelijk gedraagt binnen dat data-universum.
Hoe goed werkt het buiten het lab?
In de echte wereld zullen gevallen zelden precies op de trainingsdata lijken, dus onderzoeken de auteurs hoe hun systeem presteert op meerdere onafhankelijke deepfake-datasets die met andere acteurs en generatie-methoden zijn opgebouwd. Daar daalt de prestatie: het presteert nog steeds beter dan willekeurig raden, maar niet met grote marge op de meest uitdagende sets. Het systeem werkt het beste wanneer het nieuwe materiaal lijkt op de oorspronkelijke FaceForensics++-data en heeft moeite als de stijl van vervalsing verandert. Dit onderstreept een centraal probleem in forensische kunstmatige intelligentie: hulpmiddelen moeten niet alleen worden gevalideerd op handige benchmarkdatasets, maar ook over het veranderende landschap van deepfake-technologie heen.
Wat dit betekent voor rechtbanken en het publiek
In gewone bewoordingen toont dit werk aan dat het mogelijk is om output van deepfake-detectoren te vertalen naar een vorm van "bewijskracht" die past bij hoe forensische wetenschappers al redeneren over vingerafdrukken of DNA. Binnen omgevingen die vergelijkbaar zijn met de trainingsdata kan het systeem niet alleen een inschatting geven of een afbeelding nep is, maar ook een voorzichtig gekalibreerde verklaring over hoe sterk de gegevens die conclusie ondersteunen. Tegelijk waarschuwt de studie voor overmoedigheid: de prestaties kunnen verzwakken wanneer de methode met nieuwe soorten deepfakes wordt geconfronteerd. Voordat zulke hulpmiddelen in rechtszalen worden vertrouwd, hebben ze bredere validatie en voortdurende updates nodig om gelijke pas te houden met snel ontwikkelende manieren om de werkelijkheid te vervalsen.
Bronvermelding: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Trefwoorden: detectie van deepfakes, forensisch bewijs, likelihood-ratio, digitale beeldanalyse, rechtzaaltechnologie