Clear Sky Science · fr
Un cadre de rapport de vraisemblance basé sur des scores pour l’identification d’images deepfake en science médico-légale
Pourquoi les visages falsifiés nous concernent tous
Des images et des vidéos qui paraissent parfaitement réelles peuvent désormais être fabriquées avec des applications grand public, des outils d’échange de visages aux filtres photo. Ces soi‑disant deepfakes ne sont plus de simples curiosités d’internet — ils peuvent servir à diffuser de fausses informations, à escroquer des personnes ou à semer le doute sur des preuves réelles en justice. Cet article traite d’une question importante pour quiconque se soucie de la vérité dans un monde numérique : pas seulement « cette image est‑elle fausse ? », mais « à quel point les preuves l’affirment, de manière compréhensible pour un juge et un jury ? »
De la réponse oui/non à « à quel point en sommes‑nous sûrs »
La plupart des détecteurs de deepfake actuels fonctionnent comme des détecteurs de mensonge simplifiés : ils prennent une image et renvoient une étiquette, réelle ou falsifiée, parfois accompagnée d’un score de confiance. Pour le filtrage quotidien sur les réseaux sociaux, cela peut suffire. Mais devant un tribunal, les enquêteurs doivent comparer deux récits concurrents — « cette image est falsifiée » contre « cette image est authentique » — et expliquer dans quelle mesure les données soutiennent l’un plutôt que l’autre. Les auteurs construisent un système qui convertit les scores bruts d’un détecteur de deepfake en un « rapport de vraisemblance » : une expression numérique de combien les preuves observées favorisent un récit par rapport à l’autre, un langage déjà familier dans d’autres domaines médico‑légaux comme les empreintes digitales ou l’analyse de l’écriture.
Construire un banc d’essai rigoureux d’images réelles et falsifiées
Pour ancrer leur travail dans des données solides, les chercheurs s’appuient sur FaceForensics++, une collection largement utilisée de vidéos montrant à la fois des visages réels et des deepfakes générés par plusieurs méthodes de manipulation populaires. Ils divisent ce corpus au niveau des vidéos entières — plutôt que des images individuelles — en cinq ensembles distincts pour entraîner le détecteur, affiner ses paramètres, choisir le meilleur modèle, calibrer le système de rapport de vraisemblance et le tester. Cette conception évite les « fuites de données », où des images presque identiques extraites d’une même vidéo pourraient apparaître à la fois dans l’entraînement et dans les tests, ce qui donnerait une estimation trop optimiste des performances.
Transformer les scores du détecteur en poids de la preuve
L’équipe compare d’abord plusieurs détecteurs modernes de deepfake et constate qu’un réseau basé sur des capsules fournit les résultats les plus fiables sur différents types de falsifications. Ce modèle produit un score entre zéro et un pour chaque image de visage, des valeurs plus élevées signalant une suspicion plus forte de falsification. Plutôt que de tracer une ligne nette à un seuil arbitraire, les auteurs modélisent la distribution de ces scores pour des images réelles connues et pour des deepfakes connus. À l’aide d’une technique de lissage, ils estiment deux courbes continues : l’une décrivant les scores typiques pour les images réelles, l’autre pour les falsifications. Pour chaque nouvelle image, ils se demandent alors : ce score est‑il plus typique de la courbe « réelle » ou de la courbe « falsifiée » ? Le rapport entre ces deux possibilités devient le rapport de vraisemblance, une mesure directe de la force de la preuve.
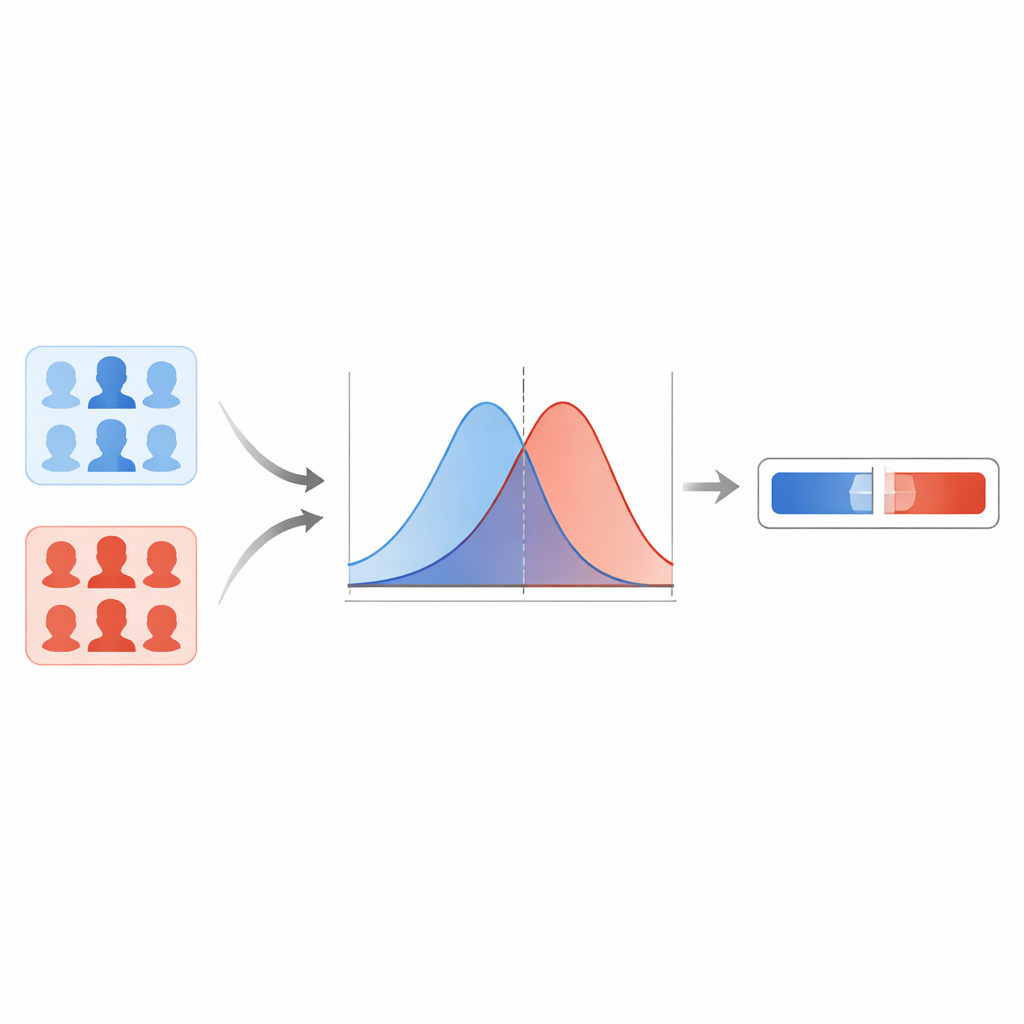
Se prémunir contre des extrêmes trop confiants
Cependant, les courbes statistiques peuvent mal se comporter dans des régions où le système a vu peu ou pas de données, conduisant à des rapports de vraisemblance irréalistes, très grands ou très petits. Pour empêcher le modèle de formuler de telles affirmations trop confiantes, les chercheurs appliquent une méthode dite de bornes inférieure et supérieure empiriques. Concrètement, ils plafonnent les valeurs les plus extrêmes que le système est autorisé à produire en se basant sur ses performances face à des exemples « difficiles ». Ils utilisent aussi une étape de calibration qui ajuste les rapports de vraisemblance bruts afin que, sur un grand nombre de cas, la force de la preuve rapportée corresponde mieux à la fréquence réelle de justesse du système. Des tests sur la portion mise de côté de FaceForensics++ montrent des taux d’erreur faibles et peu de cas où les preuves pointent dans la mauvaise direction, ce qui suggère que le système se comporte de manière raisonnable dans cet univers de données.
Jusqu’où cela fonctionne‑t‑il hors du laboratoire ?
Les cas du monde réel correspondront rarement parfaitement aux données d’entraînement, aussi les auteurs testent‑ils leur système sur plusieurs jeux de deepfakes indépendants construits avec d’autres acteurs et d’autres méthodes de génération. Là, ses performances déclinent : il fait encore mieux qu’un hasard pur, mais sans marge importante sur les jeux les plus difficiles. Le système fonctionne mieux quand le nouveau matériel ressemble aux données d’origine de FaceForensics++ et peine lorsque le style de falsification change. Cela met en lumière une difficulté centrale de l’intelligence artificielle médico‑légale : les outils doivent être validés non seulement sur des jeux de référence pratiques, mais aussi à travers le paysage mouvant des technologies de deepfake.
Ce que cela signifie pour les tribunaux et le public
En termes simples, ce travail montre qu’il est possible de traduire la sortie d’un détecteur de deepfake en une forme de « poids de la preuve » qui s’insère dans la façon dont les experts médico‑légaux raisonnent déjà à propos des empreintes ou de l’ADN. Dans des contextes similaires aux données d’entraînement, le système peut fournir non seulement une estimation de la probabilité qu’une image soit falsifiée, mais aussi une déclaration prudemment calibrée de la force avec laquelle les données soutiennent cette conclusion. En parallèle, l’étude met en garde contre l’excès de confiance : les performances peuvent se dégrader face à de nouveaux types de deepfakes. Avant que de tels outils ne soient approuvés pour une utilisation en salle d’audience, ils devront faire l’objet d’une validation plus large et d’une mise à jour continue pour suivre l’évolution rapide des méthodes de falsification de la réalité.
Citation: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Mots-clés: détection de deepfake, preuves médico-légales, rapport de vraisemblance, analyse d’image numérique, technologie en salle d’audience