Clear Sky Science · es
Un marco de razón de verosimilitud basado en puntuaciones para la identificación de imágenes deepfake en ciencia forense
Por qué las caras falsas son un problema de todos
Imágenes y vídeos que parecen perfectamente reales pueden ahora fabricarse con aplicaciones de consumo, desde herramientas de intercambio de rostros hasta filtros fotográficos. Estos llamados deepfakes ya no son solo rarezas de internet: pueden usarse para difundir noticias falsas, estafar a personas o sembrar dudas sobre pruebas reales en un tribunal. Este artículo aborda una cuestión que importa a cualquiera que se preocupe por la verdad en un mundo digital: no solo «¿esta imagen es falsa?», sino «¿con qué fuerza indican los datos que lo es, de un modo que juez y jurado puedan entender?»
De respuestas sí/no a cuánto de seguros estamos
La mayoría de los detectores de deepfakes actuales funcionan como simples detectores de mentiras: reciben una imagen y devuelven una etiqueta, real o falsa, a veces con una puntuación de confianza. Para el filtrado cotidiano en redes sociales eso puede ser suficiente. Pero en un tribunal, los investigadores deben comparar dos relatos contrapuestos —«esta imagen está falsificada» frente a «esta imagen es genuina»— y explicar con qué fuerza los datos respaldan uno u otro. Los autores construyen un sistema que convierte las puntuaciones brutas de un detector de deepfakes en una «razón de verosimilitud»: una expresión numérica de cuánto más favorece la evidencia observada a un relato que al otro, un lenguaje ya familiar en otras áreas forenses como las huellas dactilares o la grafología.
Construir un banco de pruebas cuidadoso de caras reales y falsas
Para fundamentar su trabajo en datos sólidos, los investigadores se apoyan en FaceForensics++, una colección ampliamente utilizada de vídeos que muestran tanto rostros reales como deepfakes generados por varios métodos populares de manipulación. Dividen este material a nivel de vídeos completos —en lugar de fotogramas individuales— en cinco conjuntos distintos para entrenar el detector, ajustar sus parámetros, elegir el mejor modelo, calibrar el sistema de razón de verosimilitud y probarlo. Este diseño evita la «fuga de datos», donde fotogramas casi idénticos del mismo vídeo podrían aparecer accidentalmente tanto en el entrenamiento como en la prueba, haciendo que las cifras de rendimiento parezcan mejores de lo que realmente son.
Convertir las puntuaciones del detector en peso de la evidencia
El equipo compara primero varios detectores modernos de deepfakes y encuentra que una red basada en cápsulas ofrece los resultados más fiables a través de distintos tipos de falsificaciones. Este modelo produce una puntuación entre cero y uno para cada imagen de rostro, con valores más altos que señalan una sospecha mayor de falsedad. En lugar de trazar una línea rígida en algún umbral, los autores modelan cómo se distribuyen estas puntuaciones para imágenes reales conocidas y para deepfakes conocidos. Usando una técnica de suavizado, estiman dos curvas continuas: una que describe las puntuaciones típicas de imágenes reales y otra para las falsas. Para cualquier imagen nueva, luego preguntan: ¿esta puntuación es más típica de la curva «real» o de la «falsa»? La razón entre esas dos posibilidades se convierte en la razón de verosimilitud, una medida directa de la fuerza de la evidencia.
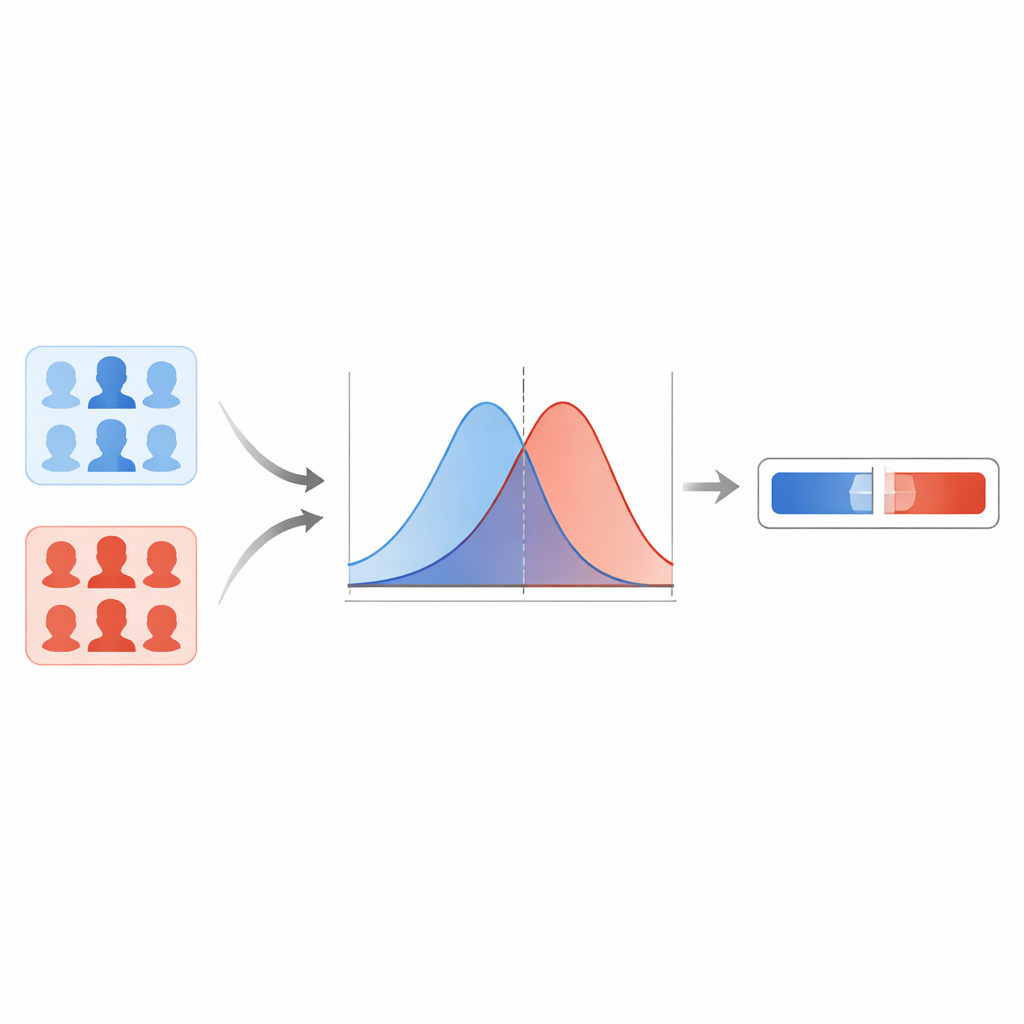
Protegerse contra extremos con exceso de confianza
Sin embargo, las curvas estadísticas pueden comportarse mal en regiones donde el sistema ha visto pocos o ningún dato, lo que conduce a razones de verosimilitud irrealmente enormes o diminutas. Para evitar que el modelo haga afirmaciones tan excesivamente confiadas, los investigadores aplican un método llamado cotas empíricas inferior y superior. En términos prácticos, limitan los valores más extremos que el sistema puede devolver en función de cómo se desempeña cuando se le somete a ejemplos «difíciles». También emplean un paso de calibración que ajusta las razones de verosimilitud crudas de modo que, en muchos casos, la fuerza de la evidencia informada se corresponda mejor con la frecuencia real de aciertos del sistema. Pruebas en la parte reservada de FaceForensics++ muestran bajas tasas de error y pocos casos en los que la evidencia apunta en la dirección equivocada, lo que sugiere que el sistema se comporta de forma sensata dentro de ese universo de datos.
¿Qué tan bien funciona fuera del laboratorio?
Los casos del mundo real rara vez coincidirán perfectamente con los datos de entrenamiento, por lo que los autores exploran cómo se comporta su sistema en varios conjuntos de deepfakes independientes elaborados con distintos actores y métodos de generación. Allí, su rendimiento cae: sigue siendo mejor que adivinar al azar, pero no por un margen amplio en los conjuntos más difíciles. El sistema funciona mejor cuando el material nuevo se parece a los datos originales de FaceForensics++ y tiene dificultades cuando cambia el estilo de la falsificación. Esto subraya una dificultad central en la inteligencia artificial forense: las herramientas deben validarse no solo en conjuntos de referencia cómodos, sino también a lo largo del paisaje cambiante de la tecnología deepfake.
Qué significa esto para los tribunales y el público
En términos prácticos, este trabajo muestra que es posible traducir la salida de un detector de deepfakes a una forma de «peso de la evidencia» que encaja con la manera en que los científicos forenses ya razonan sobre huellas dactilares o ADN. En entornos similares a sus datos de entrenamiento, el sistema puede ofrecer no solo una estimación de si una imagen es falsa, sino también una declaración calibrada con cautela sobre cuánto respaldan los datos esa conclusión. Al mismo tiempo, el estudio advierte contra el exceso de confianza: el rendimiento puede debilitarse cuando el método se enfrenta a nuevos tipos de deepfakes. Antes de que tales herramientas sean confiadas en salas de justicia, necesitarán una validación más amplia y actualizaciones continuas para seguir el ritmo de las formas rápidamente cambiantes de falsear la realidad.
Cita: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Palabras clave: detección de deepfakes, evidencia forense, razón de verosimilitud, análisis de imágenes digitales, tecnología en la sala del tribunal