Clear Sky Science · pl
System oparty na ilorazie wiarygodności oparty na wynikach do identyfikacji obrazów deepfake w naukach sądowych
Dlaczego sfałszowane twarze są problemem nas wszystkich
Obrazy i wideo, które wyglądają całkowicie realistycznie, można dziś tworzyć za pomocą aplikacji konsumenckich — od narzędzi do zamiany twarzy po filtry fotograficzne. Tak zwane deepfake’i przestały być jedynie internetowymi ciekawostkami — można je wykorzystywać do szerzenia fałszywych informacji, oszustw lub podważania prawdziwych dowodów w sądzie. Artykuł porusza pytanie istotne dla każdego, komu zależy na prawdzie w cyfrowym świecie: nie tylko „czy to zdjęcie jest fałszywe?”, lecz także „jak mocno dowody to potwierdzają, w sposób zrozumiały dla sędziego i ławy przysięgłych?”
Od odpowiedzi tak‑lub‑nie do pytania — jak bardzo jesteśmy pewni
Większość współczesnych detektorów deepfake działa jak proste wykrywacze kłamstw: przyjmują obraz i wydają etykietę — prawdziwy lub fałszywy — czasem z wartością ufności. Do codziennej filtracji w mediach społecznościowych to może wystarczyć. W sali sądowej śledczy muszą jednak porównać dwie konkurujące tezy — „ten obraz jest sfałszowany” vs. „ten obraz jest autentyczny” — i wytłumaczyć, na ile dane wspierają jedną z nich. Autorzy zbudowali system, który przekształca surowe wyniki detektora deepfake w „iloraz wiarygodności”: liczbowe wyrażenie tego, o ile bardziej obserwowany dowód przemawia za jedną hipotezą niż za drugą, w języku już używanym w innych obszarach kryminalistyki, takich jak odciski palców czy analiza pisma.
Budowanie starannego zestawu testowego z prawdziwymi i fałszywymi twarzami
Aby oprzeć pracę na solidnych danych, badacze korzystają z FaceForensics++, szeroko używanego zbioru wideo zawierającego zarówno prawdziwe twarze, jak i deepfake’i generowane różnymi popularnymi metodami manipulacji. Materiał podzielili na poziomie całych wideo — a nie pojedynczych klatek — na pięć odrębnych pul do trenowania detektora, dopracowywania ustawień, wyboru najlepszego modelu, kalibracji systemu ilorazu wiarygodności oraz testowania. Takie rozdzielenie zapobiega „wyciekowi danych”, gdy niemal identyczne klatki z tego samego wideo mogłyby przypadkowo pojawić się i w treningu, i w teście, co sztucznie zawyżałoby wyniki.
Przekształcanie wyników detektora w miarę siły dowodu
Zespół najpierw porównuje kilka nowoczesnych detektorów deepfake i stwierdza, że sieć typu capsule daje najbardziej wiarygodne rezultaty przy różnych rodzajach fałszerstw. Model ten zwraca dla każdego obrazu twarzy wynik od zera do jednego, gdzie wyższe wartości wskazują silniejsze podejrzenie fałszerstwa. Zamiast stosować twardy próg, autorzy modelują, jak te wyniki rozkładają się dla znanych prawdziwych obrazów i znanych deepfake’ów. Przy użyciu techniki wygładzania estymują dwie gładkie krzywe: jedną opisującą typowe wyniki dla obrazów prawdziwych, drugą dla fałszywych. Dla nowego obrazu pytają następnie: czy ten wynik jest bardziej typowy dla krzywej „prawdziwe” czy „fałszywe”? Stosunek tych dwóch prawdopodobieństw staje się ilorazem wiarygodności — bezpośrednią miarą siły dowodu.
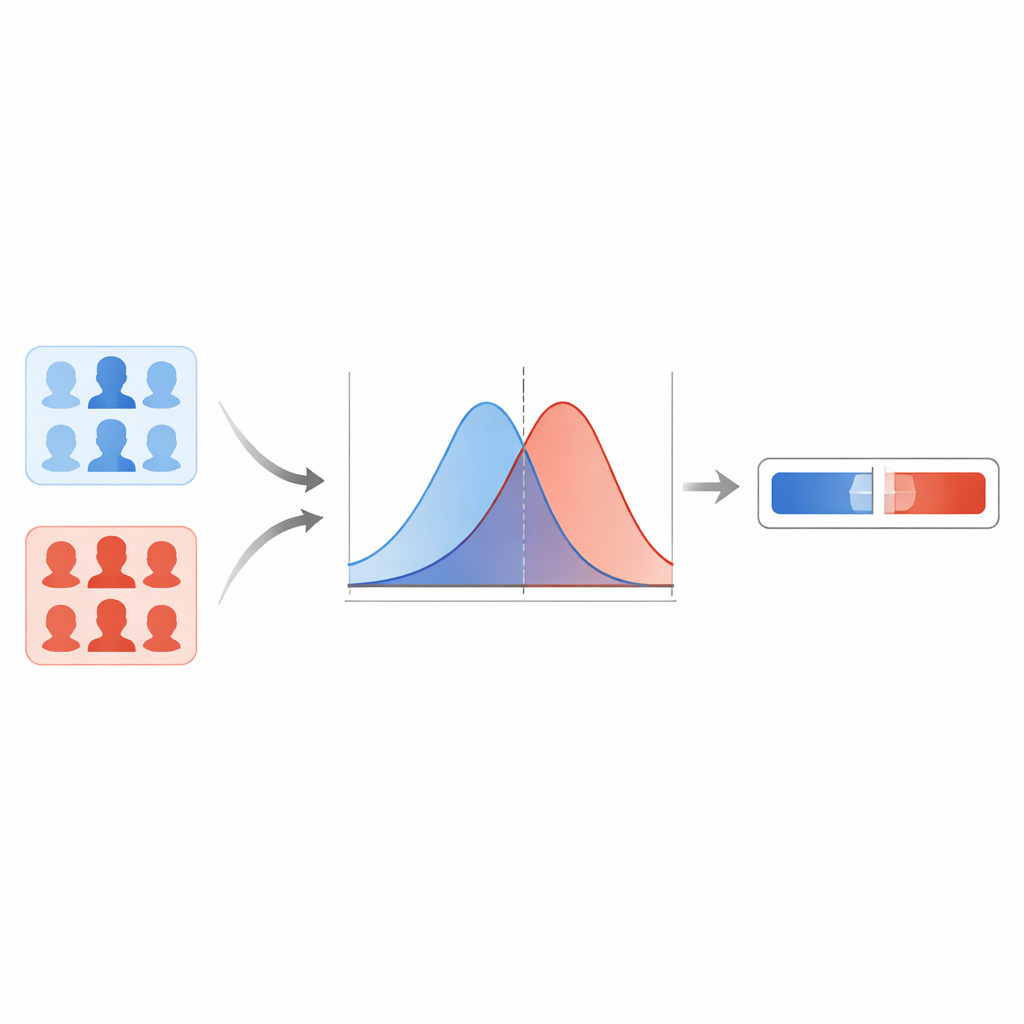
Ochrona przed nadmiernie pewnymi ekstremami
Jednak krzywe statystyczne mogą zachowywać się niestabilnie w obszarach, gdzie system widział niewiele lub nie widział wcale danych, prowadząc do nierealistycznie ogromnych lub znikomo małych ilorazów wiarygodności. Aby zapobiec takim nadmiernie pewnym twierdzeniom, badacze stosują metodę empirycznych dolnych i górnych ograniczeń. W praktyce ograniczają najbardziej ekstremalne wartości, które system może wygenerować, na podstawie jego zachowania przy „trudnych” przykładach. Używają także kroku kalibracji, który dostosowuje surowe ilorazy wiarygodności tak, by w dłuższej perspektywie zgłaszana siła dowodu lepiej odpowiadała temu, jak często system rzeczywiście ma rację. Testy na wydzielonej części FaceForensics++ wykazują niskie wskaźniki błędów i niewiele przypadków, w których dowód wskazuje w złym kierunku, co sugeruje, że system zachowuje się rozsądnie w ramach tego zbioru danych.
Jak dobrze działa poza laboratorium?
Rzeczywiste sprawy rzadko dokładnie odpowiadają danym treningowym, więc autorzy sprawdzają, jak ich system radzi sobie na kilku niezależnych zbiorach deepfake’ów z innymi aktorami i metodami generacji. W tych warunkach jego wydajność spada: wciąż działa lepiej niż losowe zgadywanie, ale nie znacznie na najtrudniejszych zestawach. System sprawdza się najlepiej, gdy nowy materiał przypomina oryginalne dane FaceForensics++, i ma trudności, gdy zmienia się styl fałszerstwa. To uwydatnia podstawową trudność w kryminalistycznej sztucznej inteligencji: narzędzia trzeba walidować nie tylko na wygodnych zestawach benchmarkowych, lecz także w zmieniającym się krajobrazie technologii deepfake.
Co to oznacza dla sądów i społeczeństwa
W praktycznych słowach praca pokazuje, że możliwe jest przetłumaczenie wyników detektora deepfake na formę „wagi dowodu”, która odpowiada sposobowi rozumowania kryminalistów przy odciskach palców czy DNA. W warunkach podobnych do danych treningowych system może dostarczyć nie tylko przypuszczenia, czy obraz jest fałszywy, lecz też ostrożnie skalibrowane stwierdzenie, jak mocno dane przemawiają za taką konkluzją. Jednocześnie badanie ostrzega przed nadmierną pewnością: wydajność może osłabnąć, gdy metoda napotyka nowe rodzaje deepfake’ów. Zanim takie narzędzia będą zaufane w salach sądowych, wymagają szerszej walidacji i ciągłej aktualizacji, by nadążać za szybko ewoluującymi sposobami fałszowania rzeczywistości.
Cytowanie: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Słowa kluczowe: detekcja deepfake, dowód sądowy, iloraz wiarygodności, analiza obrazu cyfrowego, technologia w sądzie