Clear Sky Science · sv
En poängbaserad likelihoodkvot‑ram för identifiering av deepfake‑bilder inom rättsmedicin
Varför falska ansikten är allas problem
Bilder och videor som ser helt verkliga ut kan nu fabrikeras med konsumentappar, från ansiktsbytesverktyg till fotoeffekter. Dessa så kallade deepfakes är inte längre bara internetcuriositeter—de kan användas för att sprida falska nyheter, bedra människor eller väcka tvivel om verkliga bevis i domstol. Denna artikel tar sig an en fråga som berör alla som bryr sig om sanningen i en digital värld: inte bara "Är den här bilden fejk?" utan "Hur starkt talar bevisen för det, på ett sätt en domare och jury kan förstå?"
Från ja‑eller‑nej‑svar till hur säkra är vi
De flesta deepfake‑detektorer i dag fungerar som enkla lögndetektorer: de tar emot en bild och ger ut en etikett, äkta eller fejk, ibland med en konfidenspoäng. För vardaglig filtrering i sociala medier kan det räcka. Men i en rättssal måste utredare jämföra två konkurrerande berättelser—"denna bild är förfalskad" vs. "denna bild är äkta"—och förklara hur starkt datan stödjer den ena framför den andra. Författarna bygger ett system som omvandlar de råa poängen från en deepfake‑detektor till en "likelihoodkvot": ett numeriskt uttryck för hur mycket mer det observerade beviset talar för den ena berättelsen än den andra, ett språk som redan är bekant inom andra rättsmedicinska områden som fingeravtryck och handstil.
Att bygga en noggrann testmiljö av verkliga och falska ansikten
För att förankra sitt arbete i pålitliga data använder forskarna FaceForensics++, en mycket använd samling videor som visar både verkliga ansikten och deepfakes skapade med flera populära manipuleringsmetoder. De delar upp detta material på nivån av hela videor—istället för enskilda bildrutor—i fem skilda pooler för att träna detektorn, finjustera inställningar, välja bästa modell, kalibrera likelihoodkvots‑systemet och testa det. Denna utformning undviker "dataläckage", där nästan identiska bildrutor från samma video oavsiktligt kan dyka upp i både träning och testning och få prestationssiffrorna att se bättre ut än de egentligen är.
Att förvandla detektorpoäng till bevisvärde
Teamet jämför först flera moderna deepfake‑detektorer och finner att ett kapselbaserat nätverk ger de mest tillförlitliga resultaten över olika typer av fejk. Denna modell ger en poäng mellan noll och ett för varje ansiktsbild, där högre värden signalerar en starkare misstanke om förfalskning. Istället för att dra en hård gräns vid någon tröskel modellerar författarna hur dessa poäng fördelar sig för kända verkliga bilder respektive kända deepfakes. Med en utjämningsteknik uppskattar de två släta kurvor: en som beskriver typiska poäng för äkta bilder och en annan för fejk. För en ny bild frågar de sedan: är denna poäng mer typisk för "äkta"‑kurvan eller för "fejk"‑kurvan? Kvoten mellan dessa två möjligheter blir likelihoodkvoten, ett direkt mått på bevisstyrka.
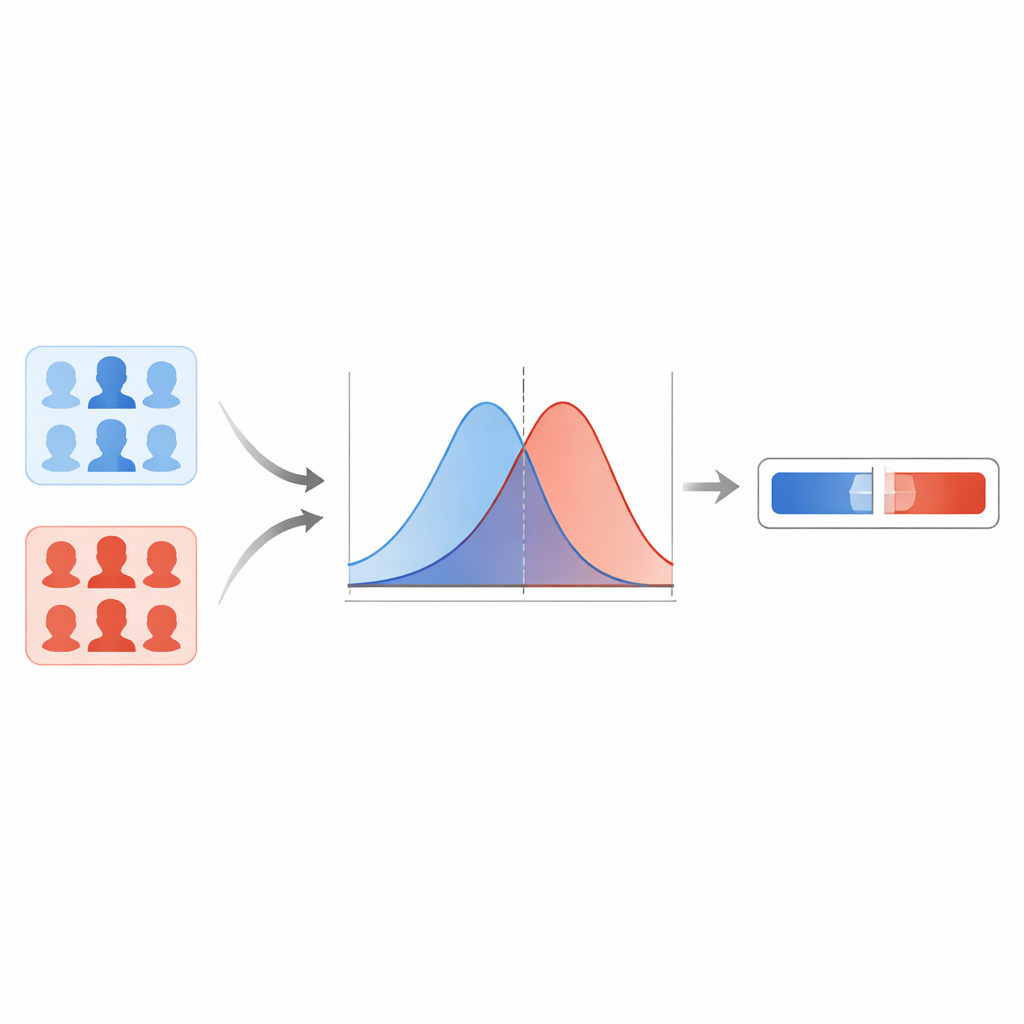
Skydd mot överdrivet självsäkra ytterligheter
Statistiska kurvor kan dock uppföra sig illa i områden där systemet sett lite eller inga data, vilket kan leda till orimligt enorma eller minimala likelihoodkvoter. För att förhindra att modellen gör sådana överdrivet självsäkra påståenden använder forskarna en metod som kallas empiriska undre och övre gränser. I praktiska termer sätter de lock på de mest extrema värden systemet får lämna ut baserat på hur det presterar när det pressas med "svåra" exempel. De använder också ett kalibreringssteg som justerar de råa likelihoodkvoterna så att, över många fall, den rapporterade bevisstyrkan bättre stämmer överens med hur ofta systemet faktiskt har rätt. Tester på den reserverade delen av FaceForensics++ visar låga felnivåer och få fall där bevisen pekar i fel riktning, vilket tyder på att systemet beter sig rimligt inom det datauniversumet.
Hur väl fungerar det utanför laboratoriet?
Verkliga fall kommer sällan att matcha träningsdata perfekt, så författarna undersöker hur deras system klarar flera oberoende deepfake‑dataset byggda med andra skådespelare och genereringsmetoder. Här faller prestandan: det gör fortfarande bättre än random gissning, men inte med stor marginal på de mest utmanande datamängderna. Systemet fungerar bäst när det nya materialet liknar originalet i FaceForensics++ och kämpar när stilen på förfalskningen förändras. Detta belyser en central svårighet i rättsmedicinsk artificiell intelligens: verktyg måste valideras inte bara på bekväma benchmark‑dataset utan också över det snabbrörliga landskapet av deepfake‑teknik.
Vad detta betyder för domstolar och allmänheten
I vardagliga termer visar detta arbete att det är möjligt att översätta deepfake‑detektorers utdata till en form av "bevisvärde" som passar in i hur rättsmedicinska experter redan resonerar kring fingeravtryck eller DNA. Inom miljöer som liknar dess träningsdata kan systemet ge inte bara en gissning om bilden är fejk, utan också ett försiktigt kalibrerat uttalande om hur starkt datan stödjer det. Samtidigt varnar studien för överdriven självsäkerhet: prestandan kan försvagas när metoden möter nya typer av deepfakes. Innan sådana verktyg får förtroende i rättssalar krävs bredare validering och kontinuerlig uppdatering för att hålla jämna steg med de snabbt utvecklande sätten att förfalska verkligheten.
Citering: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Nyckelord: detektion av deepfakes, rättsmedicinsk bevisning, likelihoodkvot, digital bildanalys, rättegångsteknik