Clear Sky Science · pt
Uma estrutura de razão de verossimilhança baseada em pontuação para identificação de imagens deepfake na ciência forense
Por que rostos falsos são problema de todo mundo
Imagens e vídeos que parecem perfeitamente reais agora podem ser fabricados com aplicativos de consumo, de ferramentas de troca de rosto a filtros de foto. Esses chamados deepfakes não são mais apenas curiosidades da internet — podem ser usados para espalhar notícias falsas, fraudar pessoas ou lançar dúvidas sobre evidências reais em tribunal. Este artigo aborda uma questão relevante para quem se importa com a verdade no mundo digital: não apenas "Esta imagem é falsa?", mas "Com que força as evidências indicam isso, de forma que um juiz e um júri possam entender?"
De respostas sim-ou-não para quão confiantes estamos
A maioria dos detectores de deepfake hoje age como detectores simples de mentira: recebem uma imagem e devolvem um rótulo, real ou falso, às vezes com uma pontuação de confiança. Para filtragem diária em redes sociais, isso pode ser suficiente. Mas em um tribunal, os investigadores precisam comparar duas narrativas concorrentes — "esta imagem foi forjada" vs. "esta imagem é genuína" — e explicar com que intensidade os dados sustentam uma em relação à outra. Os autores constroem um sistema que converte as pontuações brutas de um detector de deepfake em uma "razão de verossimilhança": uma expressão numérica de quanto mais a evidência observada favorece uma hipótese em relação à outra, uma linguagem já familiar em outras áreas forenses como impressões digitais e caligrafia.
Construindo um conjunto de teste cuidadoso de rostos reais e falsos
Para fundamentar o trabalho em dados sólidos, os pesquisadores usam o FaceForensics++, uma coleção amplamente utilizada de vídeos mostrando rostos reais e deepfakes gerados por vários métodos populares de manipulação. Eles dividem esse material ao nível de vídeos inteiros — em vez de quadros individuais — em cinco conjuntos distintos para treinar o detector, ajustar parâmetros, escolher o melhor modelo, calibrar o sistema de razão de verossimilhança e testá‑lo. Esse desenho evita o "vazamento de dados", onde quadros quase idênticos do mesmo vídeo poderiam aparecer por engano tanto no treinamento quanto nos testes, fazendo com que os números de desempenho pareçam melhores do que realmente são.
Transformando pontuações do detector em peso da evidência
A equipe primeiro compara vários detectores modernos de deepfake e constata que uma rede baseada em cápsulas fornece os resultados mais confiáveis em diferentes tipos de falsificações. Esse modelo produz uma pontuação entre zero e um para cada imagem de rosto, com valores mais altos indicando uma suspeita maior de fraude. Em vez de traçar uma linha rígida em algum limiar, os autores modelam como essas pontuações se distribuem para imagens conhecidas como reais e para deepfakes conhecidos. Usando uma técnica de suavização, eles estimam duas curvas suaves: uma descrevendo as pontuações típicas para imagens reais e outra para as falsas. Para qualquer nova imagem, então perguntam: essa pontuação é mais típica da curva "real" ou da curva "falsa"? A razão entre essas duas possibilidades torna‑se a razão de verossimilhança, uma medida direta da força da evidência.
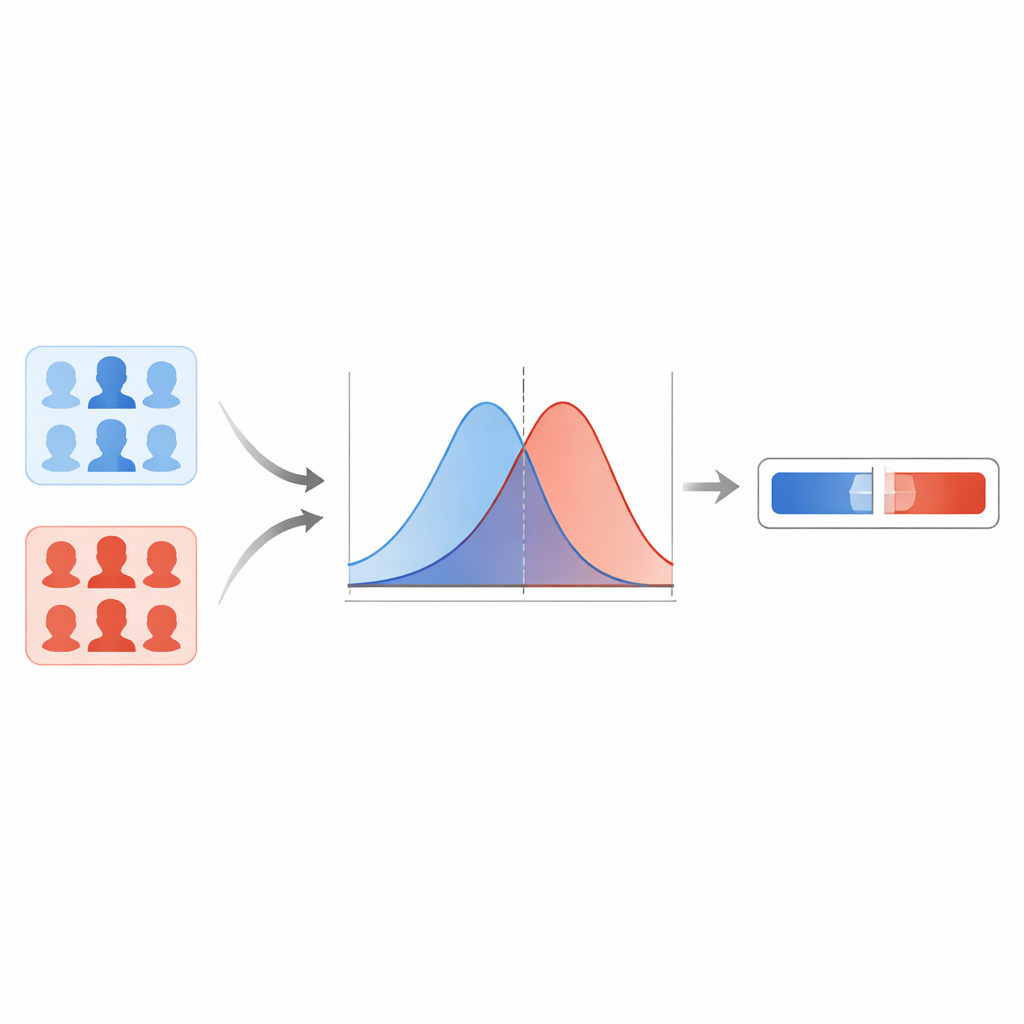
Protegendo contra extremos excessivamente confiantes
No entanto, curvas estatísticas podem se comportar mal em regiões onde o sistema viu poucos ou nenhum dado, levando a razões de verossimilhança irrealisticamente enormes ou minúsculas. Para impedir que o modelo faça tais afirmações excessivamente confiantes, os pesquisadores aplicam um método chamado limites empíricos inferiores e superiores. Em termos práticos, eles limitam os valores mais extremos que o sistema pode emitir com base em como ele se comporta quando submetido a exemplos "difíceis". Também usam uma etapa de calibração que ajusta as razões de verossimilhança brutas para que, ao longo de muitos casos, a força da evidência reportada se aproxime mais de quão frequentemente o sistema realmente está correto. Testes na parte reservada do FaceForensics++ mostram taxas de erro baixas e poucos casos em que a evidência aponta na direção errada, sugerindo que o sistema se comporta de forma sensata dentro desse universo de dados.
Quão bem isso funciona fora do laboratório?
Casos do mundo real raramente coincidirão perfeitamente com os dados de treinamento, então os autores investigam como o sistema se sai em vários conjuntos independentes de deepfakes construídos com atores e métodos de geração diferentes. Aqui, o desempenho cai: ainda é melhor que um palpite aleatório, mas não por uma margem grande nos conjuntos mais desafiadores. O sistema funciona melhor quando o novo material se assemelha aos dados originais do FaceForensics++ e tem dificuldades quando o estilo de falsificação muda. Isso destaca uma dificuldade central na inteligência artificial forense: as ferramentas devem ser validadas não apenas em conjuntos de referência convenientes, mas também através do cenário em constante mudança da tecnologia de deepfakes.
O que isso significa para tribunais e o público
Em termos práticos, este trabalho mostra que é possível traduzir a saída de detectores de deepfake para uma forma de "peso da evidência" que se encaixa na maneira como cientistas forenses já raciocinam sobre impressões digitais ou DNA. Em contextos semelhantes aos dos dados de treinamento, o sistema pode fornecer não apenas um palpite sobre se uma imagem é falsa, mas também uma declaração calibrada e cautelosa sobre com que intensidade os dados sustentam essa conclusão. Ao mesmo tempo, o estudo alerta contra excesso de confiança: o desempenho pode enfraquecer quando o método encontra novos tipos de deepfakes. Antes que tais ferramentas sejam confiadas em tribunais, elas precisarão de validação mais ampla e de atualização contínua para acompanhar as maneiras rapidamente evolutivas de falsificar a realidade.
Citação: Guo, T., Li, J. & Tang, Y. A score based likelihood ratio framework for deepfake image identification in forensic science. Sci Rep 16, 12149 (2026). https://doi.org/10.1038/s41598-026-42176-w
Palavras-chave: detecção de deepfake, prova forense, razão de verossimilhança, análise de imagem digital, tecnologia em tribunal