Clear Sky Science · zh
SV-TransFusion:用于 LiDAR 三维目标检测的稀疏体素—查询交互方法
以三维视角看清道路
自动驾驶汽车必须在各种天气与交通情况下识别并跟踪周围的一切——从卡车和公交车到骑行者与行人。许多系统依赖 LiDAR(一种基于激光的传感器)来构建世界的三维图像。但当前大多数算法把这种丰富的三维信息压扁为一个平面的俯视图,这样虽然简化了计算,却丢弃了关于高度的重要细节。本文提出了 SV-TransFusion,一种让计算机保留并利用这些丢失三维结构的新方法,从而实现更安全、更可靠的道路目标检测。
将三维数据扁平化的风险
目前领先的 LiDAR 检测器通常把点云——散布在空间中的百万级测距点——转换为鸟瞰图。在这个平面图中,每个像素汇总其上方的所有信息,把高度差异大的物体合并在一起。站在高杆旁的行人,或靠近卡车的低矮施工护栏,在仅有俯视图的情况下可能看起来几乎相同。这种捷径加快了处理速度,但也会引入混淆,尤其是在场景拥挤或高矮物体在地面投影上重合时。
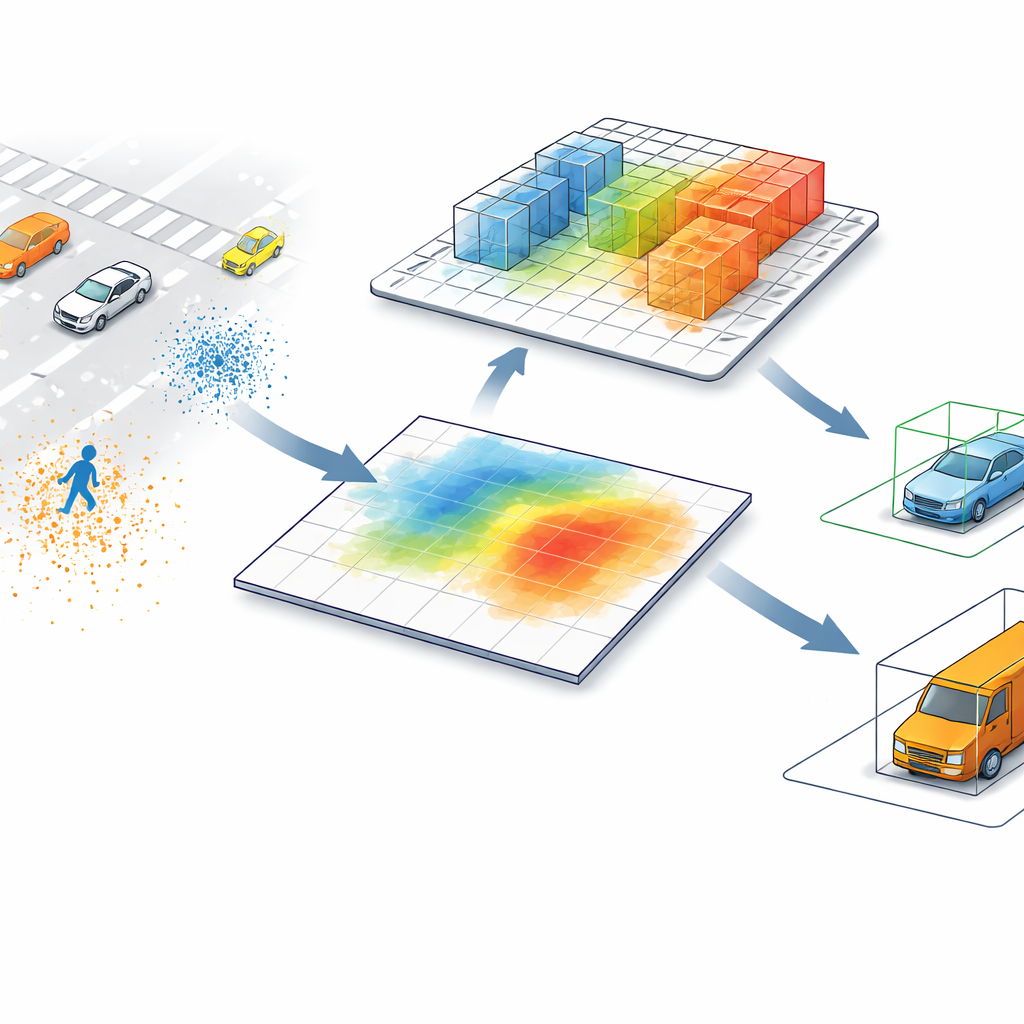
让计算机重新“回望”三维
SV-TransFusion 通过为检测算法重新打开指向原始三维结构的直接通路来解决这个问题。系统不再只让内部的“对象查询”看到被压扁的地图,而是允许它们有选择地访问附近保留高度与形状信息的三维体素(voxels)。一个专门模块——稀疏体素—查询交互(Sparse Voxel-Query Interaction)——在每个候选对象位置周围搜索,并仅聚合该邻域内非空的体素。通过把注意力集中在实际测得的点而非空白空间上,模型恢复了原本会丢失的细微垂直线索。
通过嘈杂样本加速、更清晰的学习
变换器(Transformers)是许多现代视觉与语言系统背后的神经网络,功能强大,但在检测任务的训练中常常速度慢且不稳定。作者提出了一种名为基于查询的对比去噪(Query-based Contrastive Denoising)的训练方案来应对这一问题。训练期间,他们故意对理想的对象提示加入噪声——略微移动或缩放标注车辆、行人或自行车的框——然后要求模型纠正这些带噪的猜测。同时,他们鼓励同一类别对象的内部特征聚类在一起,而把不同类别拉开。这样的组合帮助系统快速学会区分例如公交车与卡车或背景杂物的关键特征,即使在被压扁的视图中它们看起来相似。
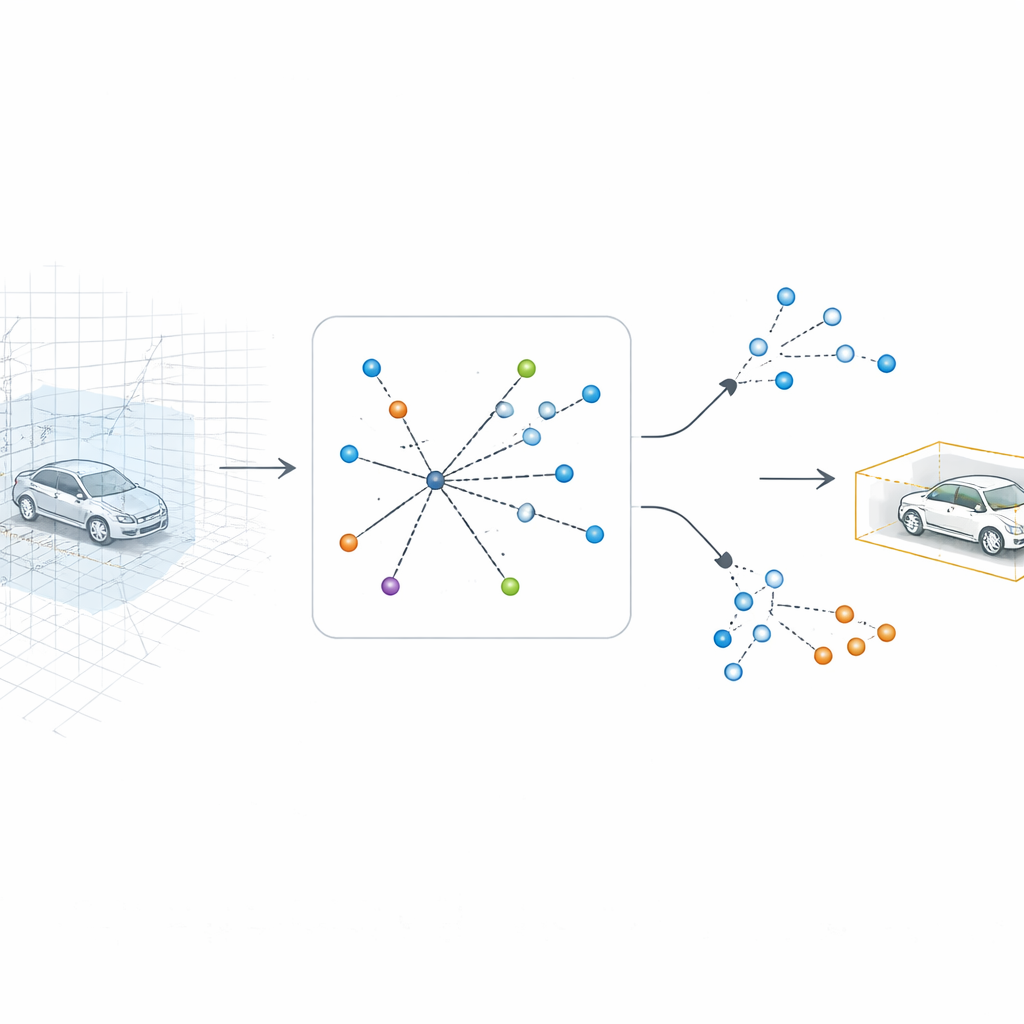
在真实街道数据上的验证
团队在 nuScenes(一套广泛使用的复杂城市交通自动驾驶数据集)上测试了 SV-TransFusion。与包括流行的 TransFusion 模型在内的强基线方法相比,SV-TransFusion 在目标检测的准确性、朝向和运动估计的可靠性上表现更佳,且计算开销仅有适度增加。对低矮且对高度敏感的类别(如行人和自行车),以及距离较远或部分遮挡的物体,这些提升尤其明显——正是那些失去垂直细节时最容易出问题的情况。该方法还提升了多种不同 LiDAR 主干网络的表现,表明它可以接入许多现有系统。
对更安全自动驾驶的意义
简单来说,SV-TransFusion 让自动驾驶汽车重新以三维方式“思考”,且不牺牲速度。通过允许检测模块回溯到原始三维测量并采用带噪、对比的训练样本,该方法带来了更清晰、更可靠的道路场景理解。这意味着对弱势道路使用者的识别更好、对外观相似车辆的区分更清楚、对运动的跟踪更有信心——这些都是实现实时、安全自动驾驶的关键要素。
引用: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
关键词: LiDAR 三维目标检测, 自动驾驶, 变换器模型, 稀疏体素, 鸟瞰图感知