Clear Sky Science · fr
SV-TransFusion pour la détection d’objets 3D LiDAR avec interaction voxel–requête éparse
Voir la route en trois dimensions
Les voitures autonomes doivent repérer et suivre tout ce qui les entoure — des camions et bus aux cyclistes et piétons — quelles que soient les conditions météorologiques et le trafic. De nombreux systèmes s’appuient sur le LiDAR, un capteur laser qui construit une image 3D du monde. Mais la plupart des algorithmes actuels compressent ces riches informations 3D en une vue plate en plongée, ce qui simplifie les calculs mais fait perdre d’importants détails de hauteur. Cet article présente SV-TransFusion, une nouvelle approche permettant aux ordinateurs de conserver et d’exploiter cette structure 3D manquante, améliorant ainsi la détection sûre et fiable des objets sur la route.
Pourquoi aplatir les données 3D peut être risqué
Les détecteurs LiDAR de pointe convertissent généralement les nuages de points — des millions de mesures de distance réparties dans l’espace — en une image en vue aérienne. Sur cette carte plate, chaque pixel résume tout ce qui se trouve au-dessus, fusionnant des objets qui peuvent différer fortement en hauteur. Un piéton à côté d’un poteau haut, ou une barrière de chantier basse près d’un camion, peuvent paraître presque identiques vus uniquement de dessus. Ce raccourci accélère le traitement, mais introduit aussi des confusions, en particulier dans les scènes encombrées ou quand des objets petits et hauts partagent la même empreinte au sol.
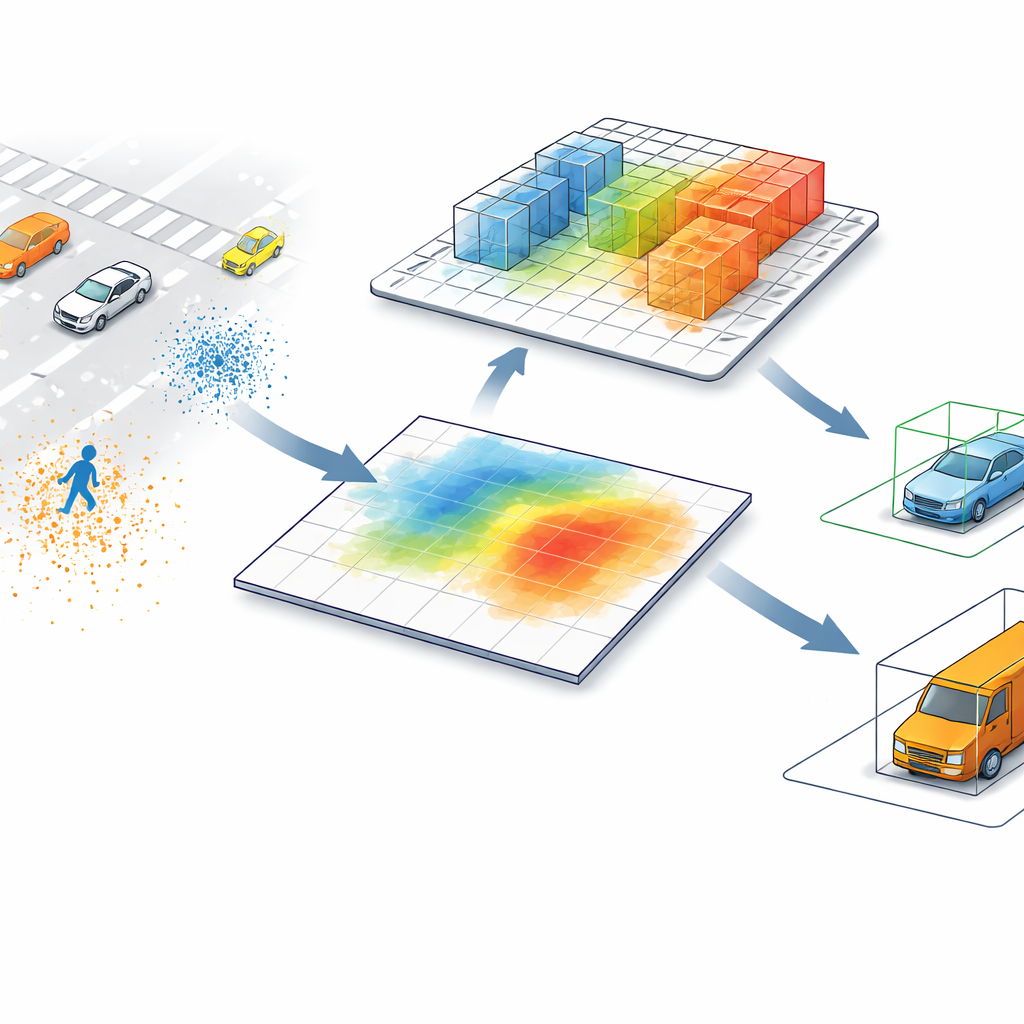
Permettre à l’ordinateur de regarder de nouveau en 3D
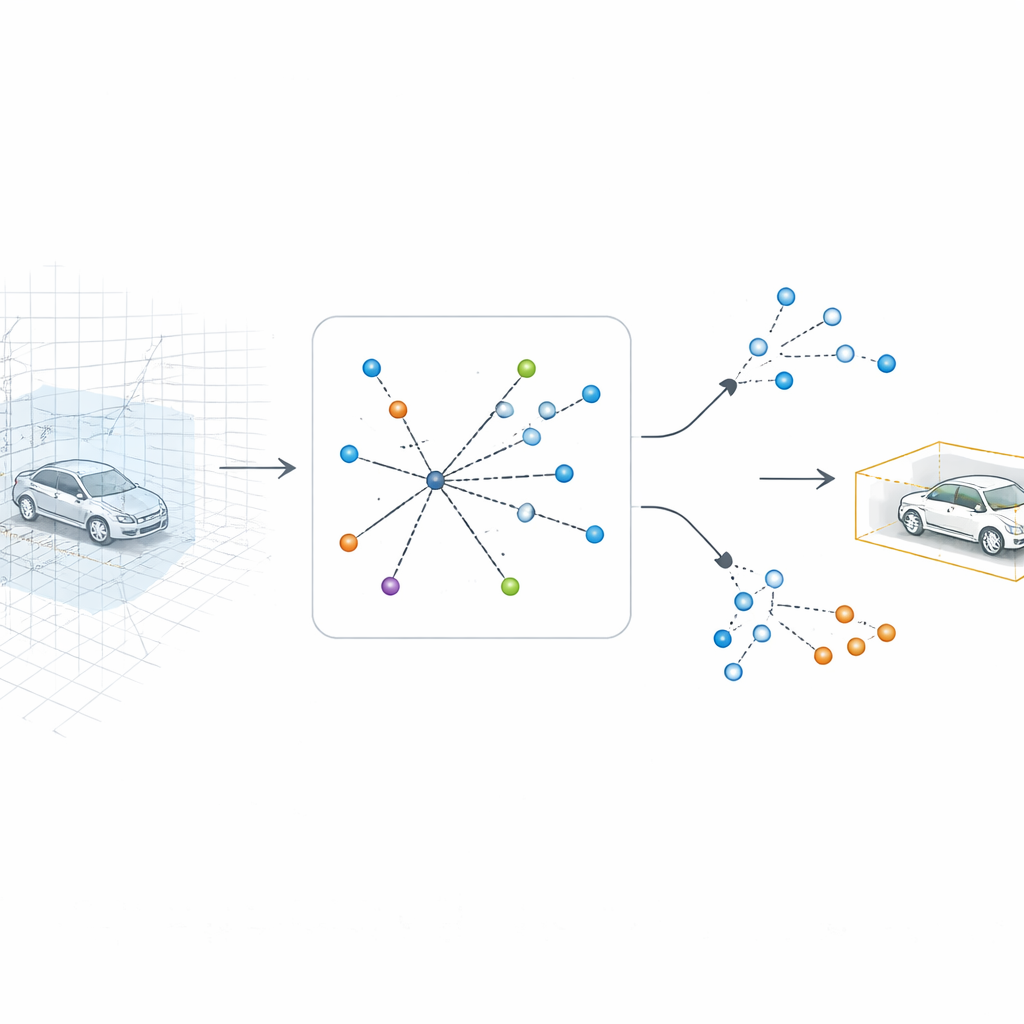
SV-TransFusion s’attaque à ce problème en rouvrant une ligne directe du détecteur vers la structure 3D d’origine. Plutôt que de limiter ses « requêtes d’objet » internes à la carte aplatie, le système leur permet d’atteindre sélectivement des cellules volumétriques 3D proches, ou voxels, qui conservent des informations fines de hauteur et de forme. Un module spécialisé, appelé Sparse Voxel-Query Interaction, recherche autour de chaque position d’objet potentielle et rassemble uniquement les voxels non vides dans ce voisinage. En concentrant l’attention sur les points réellement mesurés, plutôt que sur l’espace vide, le modèle récupère des indices verticaux subtils qui seraient autrement perdus.
Apprentissage plus rapide et plus clair grâce à des exemples bruités
Les transformers, les réseaux neuronaux derrière de nombreux systèmes modernes de vision et de langage, sont puissants mais souvent lents et instables à entraîner pour les tâches de détection. Les auteurs introduisent un schéma d’entraînement appelé Query-based Contrastive Denoising pour remédier à cela. Pendant l’entraînement, ils ajoutent délibérément du bruit aux indications d’objet idéales — en décalant et redimensionnant légèrement les boîtes qui marquent voitures, piétons ou vélos — puis demandent au modèle de corriger ces estimations bruitées. En parallèle, ils encouragent les caractéristiques internes du même type d’objet à se regrouper entre elles tout en écartant les types différents. Cette combinaison aide le système à apprendre rapidement ce qui distingue, par exemple, un bus d’un camion ou d’un bruit de fond, même lorsqu’ils apparaissent similaires dans la vue aplatie.
Preuves des bénéfices sur des données réelles de rue
L’équipe a testé SV-TransFusion sur nuScenes, un jeu de données largement utilisé pour la conduite autonome en milieu urbain complexe. Comparé à des méthodes existantes solides, y compris le populaire modèle TransFusion, SV-TransFusion a détecté les objets plus précisément et estimé leur orientation et leur mouvement de manière plus fiable, le tout avec seulement une augmentation modeste du coût de calcul. Les gains étaient particulièrement nets pour les catégories sensibles à la hauteur comme les piétons et les bicyclettes, et pour les objets éloignés ou partiellement cachés — précisément les cas où la perte de détail vertical est la plus dommageable. L’approche a également amélioré diverses architectures LiDAR, montrant qu’elle peut être intégrée à de nombreux systèmes existants.
Ce que cela signifie pour une autonomie plus sûre
En termes simples, SV-TransFusion permet aux voitures autonomes de « penser » à nouveau en 3D, sans sacrifier la vitesse. En laissant les modules de détection puiser dans les mesures 3D brutes et en les entraînant avec des exemples bruités et contrastifs, la méthode offre une compréhension de la scène routière plus nette et plus fiable. Cela se traduit par une meilleure reconnaissance des usagers vulnérables, une séparation plus claire des véhicules d’apparence similaire et un suivi des mouvements plus confiant — autant d’ingrédients cruciaux pour une conduite autonome sûre et en temps réel.
Citation: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Mots-clés: Détection d’objets 3D LiDAR, conduite autonome, modèles transformer, voxels épars, perception en vue aérienne