Clear Sky Science · de
SV-TransFusion für LiDAR-3D-Objekterkennung mit Sparse Voxel–Query Interaction
Die Straße in drei Dimensionen sehen
Autonome Fahrzeuge müssen alles um sich herum erkennen und verfolgen – von Lkw und Bussen bis zu Radfahrern und Fußgängern – bei allen Wetter- und Verkehrssituationen. Viele Systeme stützen sich auf LiDAR, einen laserbasierten Sensor, der ein 3D-Bild der Umgebung erzeugt. Die meisten aktuellen Algorithmen drücken diese reichhaltigen 3D-Informationen jedoch in eine flache Draufsicht, was die Berechnungen vereinfacht, aber wichtige Höheninformationen verwischt. Dieses Paper stellt SV-TransFusion vor, einen neuen Ansatz, mit dem Computer die verlorene 3D-Struktur bewahren und nutzen können, was zu einer sichereren und zuverlässigeren Objekterkennung auf der Straße führt.
Warum das Abflachen von 3D-Daten riskant sein kann
Die führenden LiDAR-Detektoren wandeln Punktwolken – Millionen von Entfernungsmessungen im Raum – typischerweise in ein Vogelperspektiven-Bild um. In dieser flachen Karte fasst jedes Pixel alles darüber Zusammen und verschmilzt Objekte, die sich stark in der Höhe unterscheiden können. Ein Fußgänger neben einer hohen Laterne oder eine niedrige Baustellenbarriere neben einem Lkw können aus der Draufsicht fast identisch wirken. Diese Abkürzung beschleunigt die Verarbeitung, führt aber auch zu Verwechslungen, besonders in unordentlichen Szenen oder wenn kleine und hohe Objekte dieselbe Bodenfläche teilen.
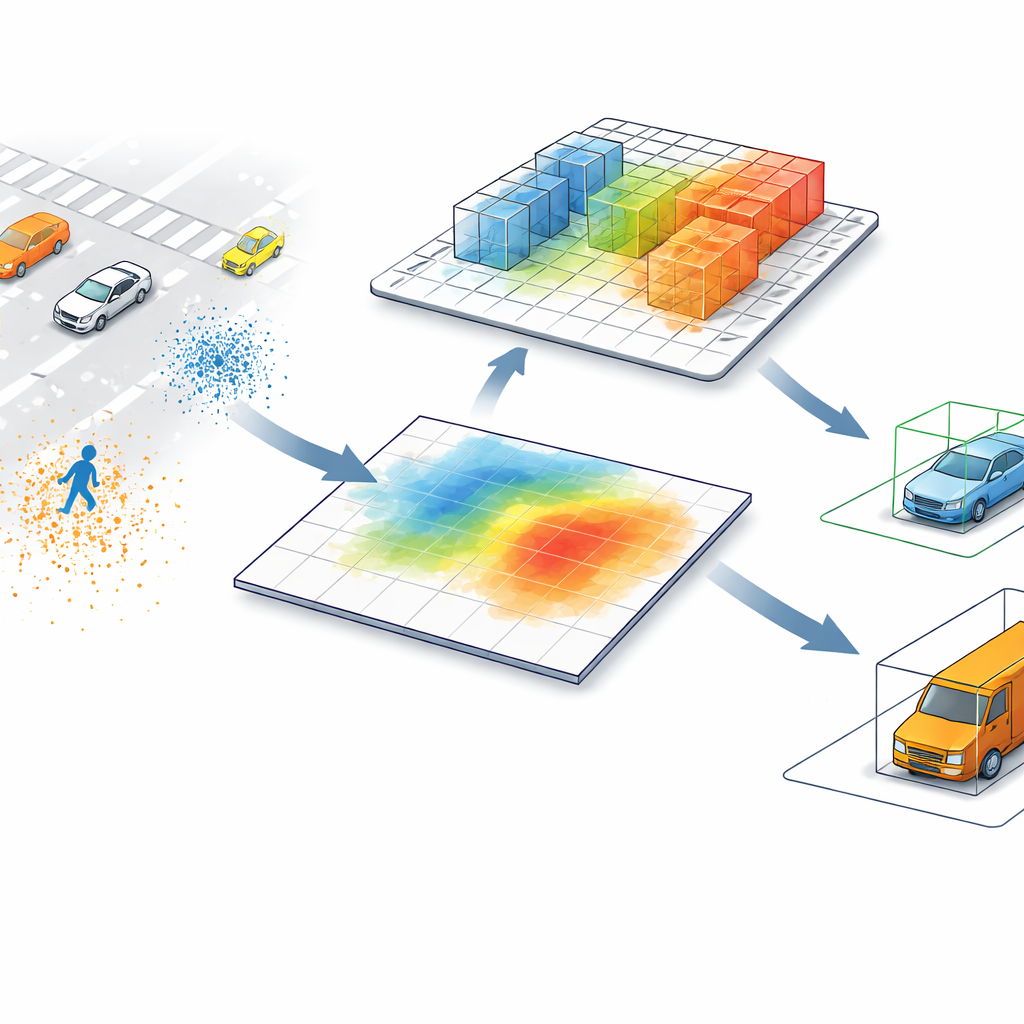
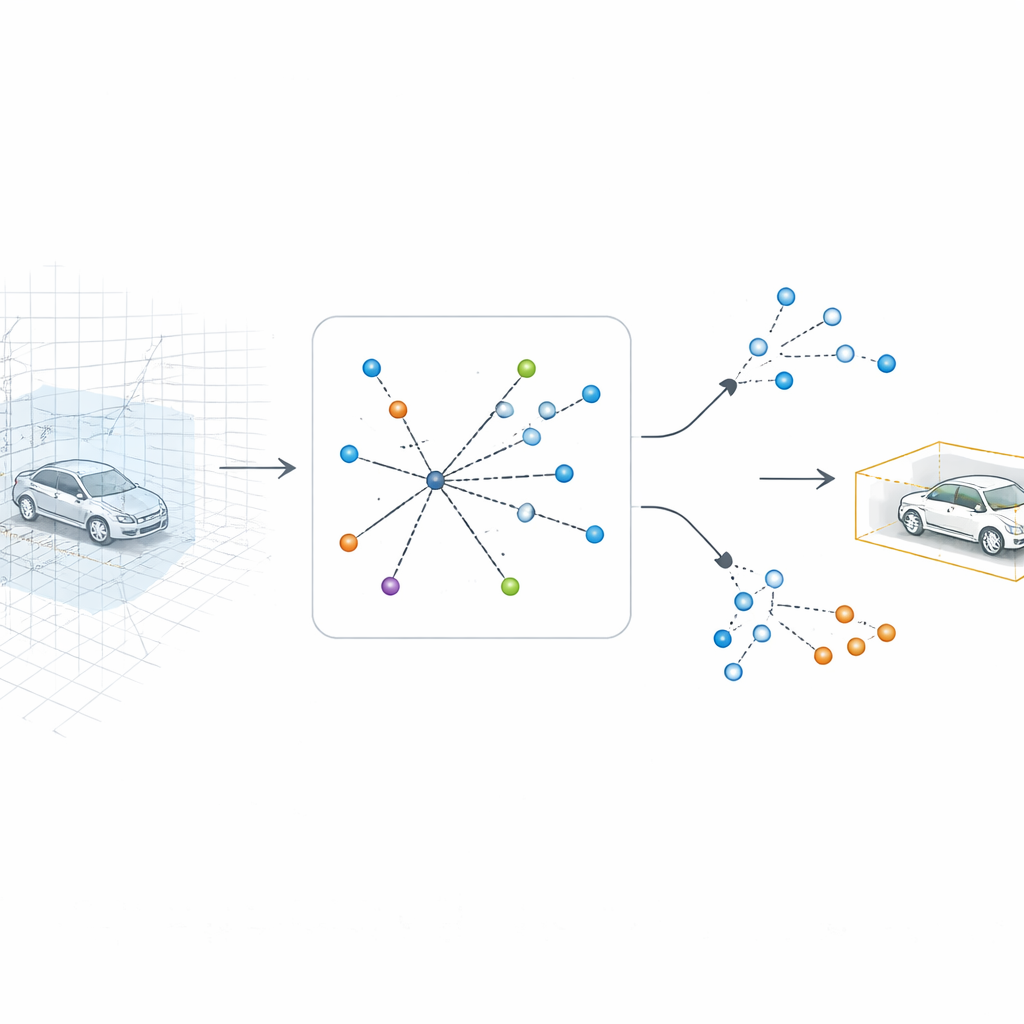
Dem Computer erlauben, wieder in 3D zu schauen
SV-TransFusion geht dieses Problem an, indem es eine direkte Verbindung von der Erkennungsarchitektur zurück zur ursprünglichen 3D-Struktur wiederherstellt. Anstatt die internen „Object Queries“ nur die geflachte Karte sehen zu lassen, erlaubt das System ihnen, selektiv in nahe gelegene 3D-Volumenzellen, sogenannte Voxels, zu greifen, die noch feine Höhen- und Forminformationen enthalten. Ein spezialisiertes Modul, Sparse Voxel-Query Interaction, durchsucht die Umgebung jeder vorläufigen Objektposition und sammelt nur die nicht-leeren Voxels in dieser Nachbarschaft. Indem die Aufmerksamkeit auf tatsächlich gemessene Punkte und nicht auf leeren Raum gelenkt wird, gewinnt das Modell subtile vertikale Hinweise zurück, die sonst verloren gingen.
Schnelleres, klareres Lernen durch verrauschte Beispiele
Transformer, die neuronalen Netze hinter vielen modernen Vision- und Sprachsystemen, sind leistungsfähig, jedoch oft langsam und instabil beim Training für Erkennungsaufgaben. Die Autoren führen ein Trainingsschema namens Query-based Contrastive Denoising ein, um dem entgegenzuwirken. Während des Trainings fügen sie absichtlich Rauschen zu idealen Objektvorgaben hinzu – verschieben und skalieren leicht die Boxen, die Autos, Fußgänger oder Fahrräder markieren – und fordern das Modell auf, diese verrauschten Schätzungen zu korrigieren. Gleichzeitig werden interne Merkmale desselben Objekttyps zusammengeführt und Merkmale unterschiedlicher Typen auseinandergehalten. Diese Kombination hilft dem System schnell zu lernen, was beispielsweise einen Bus von einem Lkw oder von Hintergrundstörung unterscheidet, selbst wenn sie in der Draufsicht ähnlich erscheinen.
Nachweis der Vorteile an realen Straßendaten
Das Team testete SV-TransFusion auf nuScenes, einem häufig verwendeten Datensatz für autonomes Fahren mit komplexem Stadtverkehr. Im Vergleich zu starken bestehenden Methoden, einschließlich des beliebten TransFusion-Modells, erkannte SV-TransFusion Objekte genauer und schätzte deren Orientierung und Bewegung zuverlässiger ein – und das bei nur moderat erhöhtem Rechenaufwand. Die Verbesserungen waren besonders deutlich bei kleinen, höhenempfindlichen Kategorien wie Fußgängern und Fahrrädern sowie bei weit entfernten oder teilweise verdeckten Objekten – genau den Fällen, in denen der Verlust vertikaler Details am schädlichsten ist. Der Ansatz verbesserte zudem verschiedene LiDAR-Backbones, was zeigt, dass er in viele bestehende Systeme integrierbar ist.
Was das für sicherere Autonomie bedeutet
Einfach gesagt erlaubt SV-TransFusion autonomen Fahrzeugen, wieder in 3D „zu denken“, ohne Geschwindigkeit zu opfern. Indem Erkennungsmodule auf die rohen 3D-Messungen zurückgreifen können und durch Training mit verrauschten, kontrastiven Beispielen, liefert die Methode eine schärfere, verlässlichere Interpretation der Straßenszene. Das bedeutet bessere Erkennung schutzbedürftiger Verkehrsteilnehmer, klarere Trennung ähnlich aussehender Fahrzeuge und sicherere Verfolgung von Bewegungen – alles entscheidende Bausteine für sicheres, Echtzeit-fähiges autonomes Fahren.
Zitation: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Schlüsselwörter: LiDAR 3D-Objekterkennung, autonomes Fahren, Transformer-Modelle, spärliche Voxels, Vogelperspektiven-Wahrnehmung