Clear Sky Science · en
SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction
Seeing the Road in Three Dimensions
Self-driving cars must spot and track everything around them—from trucks and buses to cyclists and pedestrians—in all kinds of weather and traffic. Many systems rely on LiDAR, a laser-based sensor that builds a 3D picture of the world. But most current algorithms squeeze this rich 3D information into a flat top-down view, which makes the math easier yet throws away important details about height. This paper introduces SV-TransFusion, a new way for computers to keep and use that missing 3D structure, leading to safer and more reliable detection of objects on the road.
Why Flattening 3D Data Can Be Risky
Today’s leading LiDAR detectors typically convert point clouds—millions of distance measurements scattered in space—into a bird’s-eye-view image. In that flat map, each pixel summarizes everything above it, merging objects that may differ greatly in height. A pedestrian beside a tall pole, or a low construction barrier near a truck, can look almost identical when viewed only from above. This shortcut speeds up processing, but it also introduces confusion, especially in cluttered scenes or when small and tall objects share the same footprint on the road.
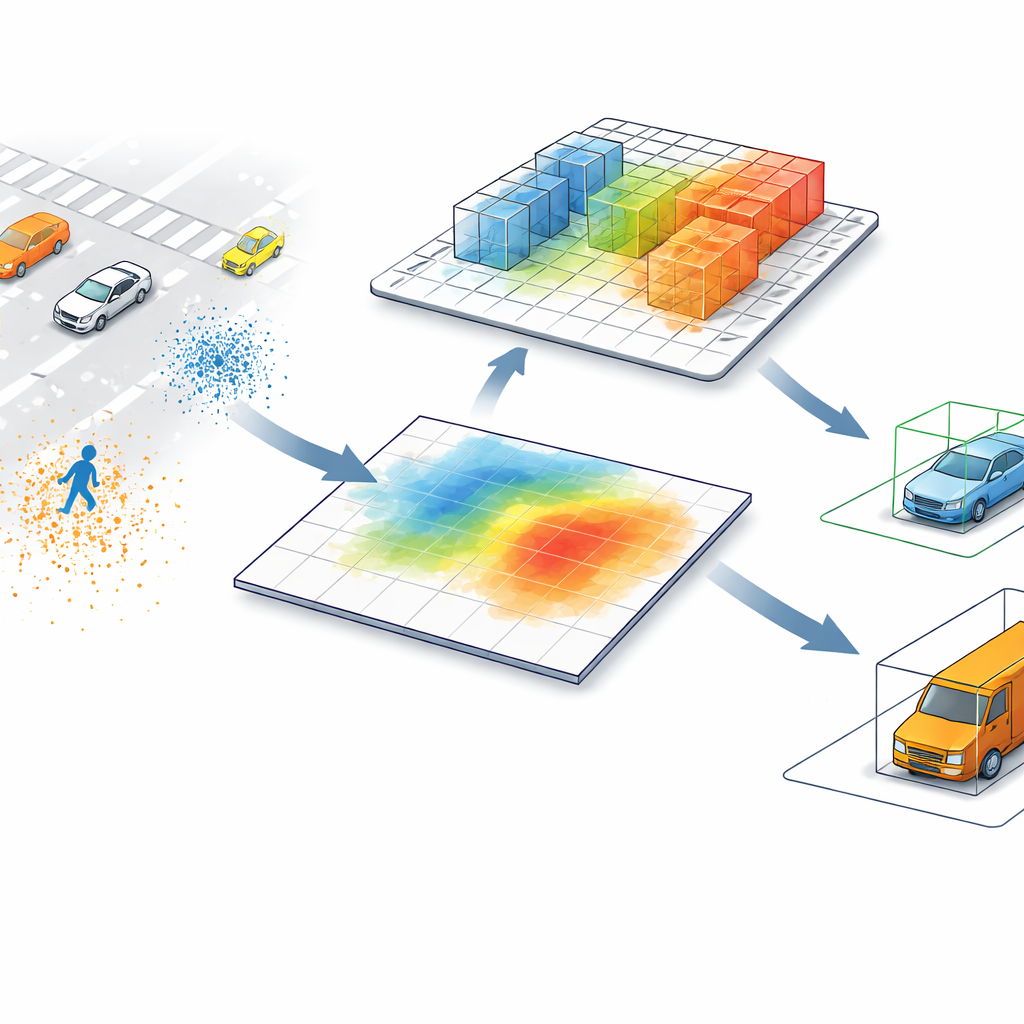
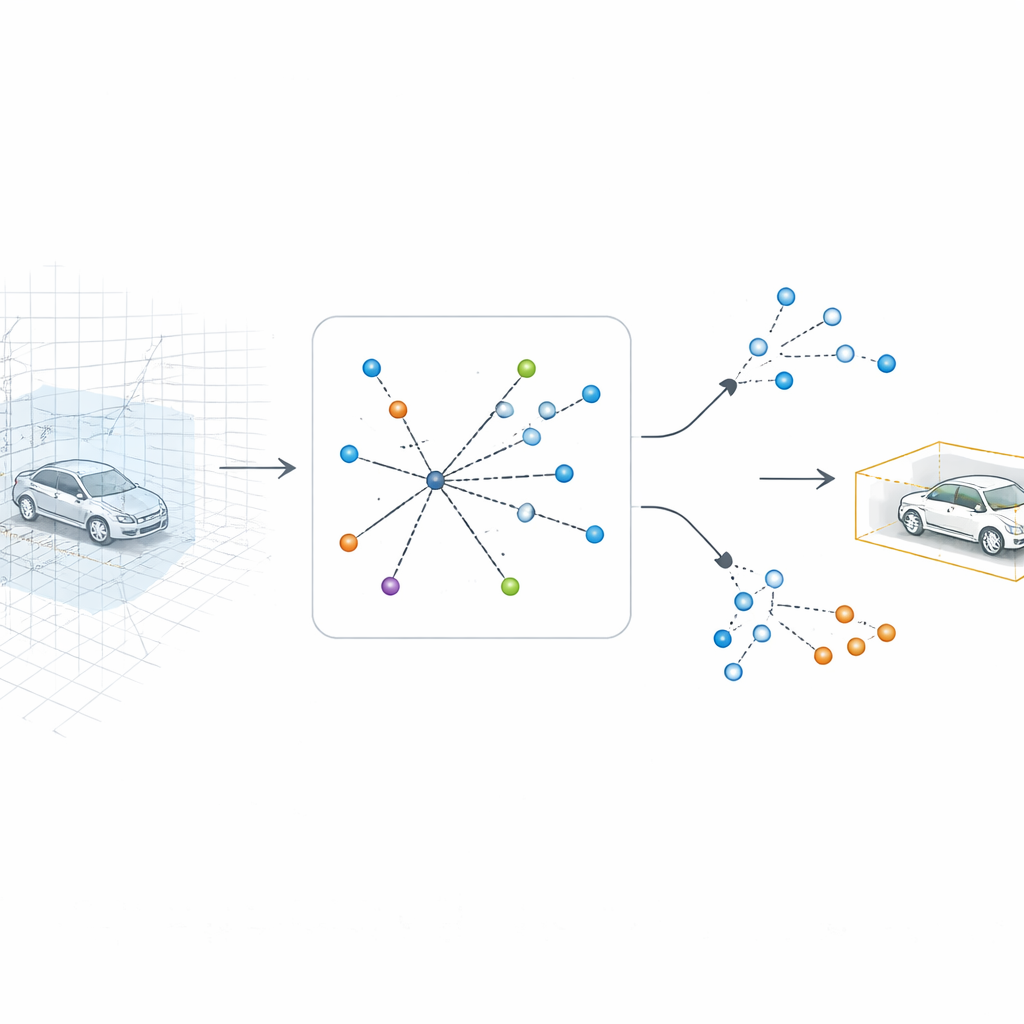
Letting the Computer Look Back into 3D
SV-TransFusion tackles this problem by re-opening a direct line from the detection algorithm back to the original 3D structure. Instead of allowing its internal "object queries" to see only the flattened map, the system lets them selectively reach into nearby 3D volume cells, or voxels, that still hold fine height and shape information. A specialized module, called Sparse Voxel-Query Interaction, searches around each tentative object location and gathers only the non-empty voxels in that neighborhood. By focusing attention on the actual measured points, rather than empty space, the model recovers subtle vertical cues that would otherwise be lost.
Faster, Clearer Learning through Noisy Examples
Transformers, the neural networks behind many modern vision and language systems, are powerful but often slow and unstable to train for detection tasks. The authors introduce a training scheme called Query-based Contrastive Denoising to address this. During training, they deliberately add noise to ideal object hints—slightly shifting and resizing the boxes that mark cars, pedestrians, or bikes—then ask the model to correct these noisy guesses. At the same time, they encourage the internal features for the same type of object to cluster together, while pushing different types apart. This combination helps the system quickly learn what makes, say, a bus different from a truck or background clutter, even when they appear similar in the flattened view.
Proving the Benefits on Real Street Data
The team tested SV-TransFusion on nuScenes, a widely used autonomous-driving dataset with complex urban traffic. Compared with strong existing methods, including the popular TransFusion model, SV-TransFusion detected objects more accurately and estimated their orientation and motion more reliably, all with only a modest increase in computation. The gains were especially clear for small, height-sensitive categories such as pedestrians and bicycles, and for objects that are far away or partially hidden—exactly the cases where losing vertical detail is most harmful. The approach also improved a range of different LiDAR backbones, showing that it can be plugged into many existing systems.
What This Means for Safer Autonomy
In plain terms, SV-TransFusion lets self-driving cars "think" in 3D again, without sacrificing speed. By allowing detection modules to reach back into the raw 3D measurements and by training them with noisy, contrastive examples, the method delivers sharper, more reliable understanding of the road scene. That means better recognition of vulnerable road users, clearer separation of similar-looking vehicles, and more confident tracking of motion—all crucial ingredients for safe, real-time autonomous driving.
Citation: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Keywords: LiDAR 3D object detection, autonomous driving, transformer models, sparse voxels, bird’s-eye-view perception