Clear Sky Science · nl
SV-TransFusion voor LiDAR 3D-objectdetectie met Sparse Voxel–Query Interaction
De weg in drie dimensies zien
Zelfrijdende auto’s moeten alles om hen heen herkennen en volgen—van vrachtauto’s en bussen tot fietsers en voetgangers—in allerlei weersomstandigheden en verkeerssituaties. Veel systemen vertrouwen op LiDAR, een lasergestuurde sensor die een 3D-beeld van de omgeving opbouwt. Maar de meeste huidige algoritmen persen deze rijke 3D-informatie in een plat bovenaanzicht, wat de berekeningen vereenvoudigt maar belangrijke hoogte-informatie weggooit. Dit artikel introduceert SV-TransFusion, een nieuwe methode waarmee computers die ontbrekende 3D-structuur behouden en gebruiken, wat leidt tot veiliger en betrouwbaarder detecteren van objecten op de weg.
Waarom 3D-data plat slaan riskant kan zijn
De huidige toonaangevende LiDAR-detectoren zetten puntwolken—miljoenen afstandsmetingen verspreid in de ruimte—meestal om in een bird’s-eye-view-afbeelding. In die platte kaart vat elke pixel alles samen wat erboven ligt, waardoor objecten die sterk in hoogte verschillen samengevoegd worden. Een voetganger naast een hoge paal, of een lage bouwafzetting naast een vrachtwagen, kan er van bovenaf vrijwel identiek uitzien. Deze truc versnelt de verwerking, maar zorgt ook voor verwarring, vooral in drukke scènes of wanneer kleine en hoge objecten hetzelfde grondoppervlak delen.
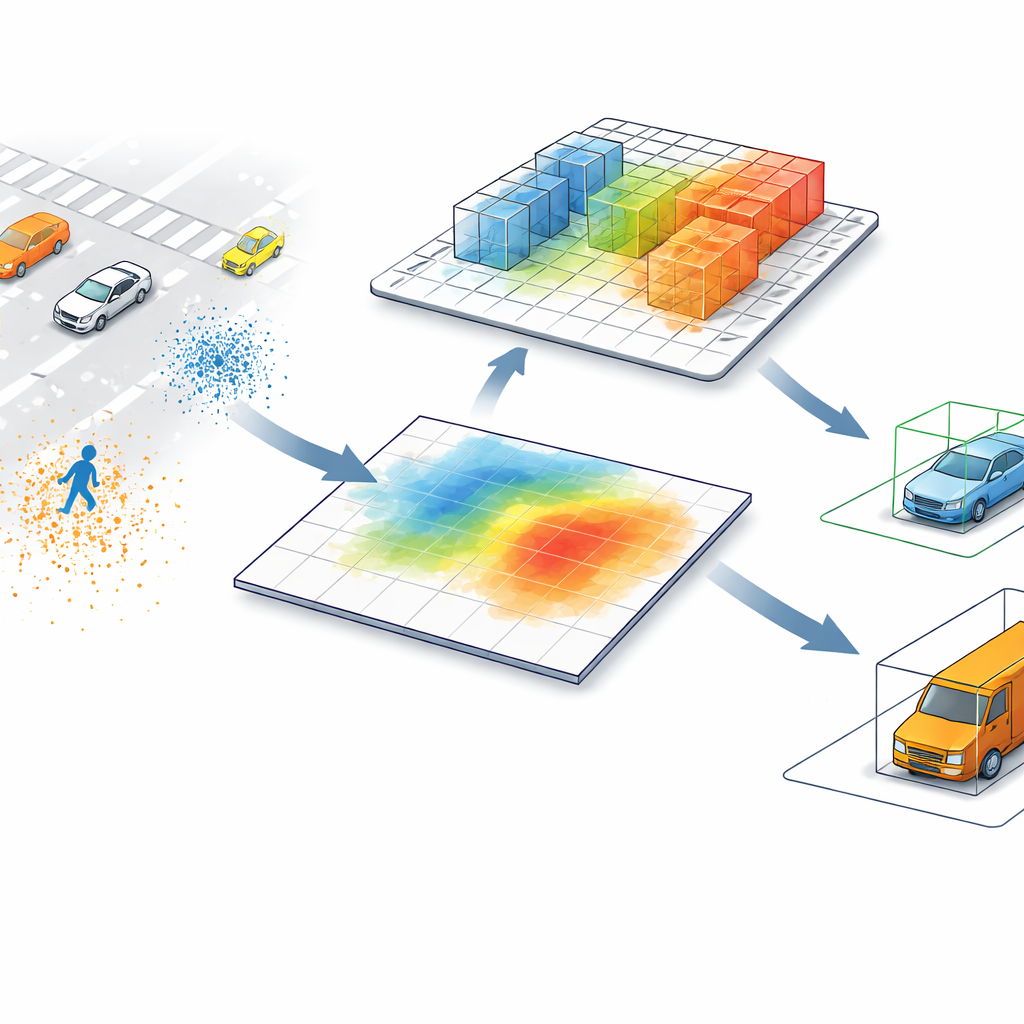
De computer weer in 3D laten kijken
SV-TransFusion pakt dit probleem aan door een directe lijn van het detectie-algoritme terug naar de oorspronkelijke 3D-structuur te herstellen. In plaats van interne “object queries” alleen het afgeplatte kaartbeeld te laten zien, kunnen ze selectief in nabijgelegen 3D-volumecellen, of voxels, reiken die nog steeds gedetailleerde hoogte- en vorminformatie bevatten. Een gespecialiseerd module, Sparse Voxel-Query Interaction genoemd, zoekt rond elke voorlopige objectlocatie en verzamelt alleen de niet-lege voxels in die buurt. Door de aandacht te richten op de daadwerkelijk gemeten punten in plaats van op lege ruimte, herwint het model subtiele verticale aanwijzingen die anders verloren zouden gaan.
Sneller en duidelijker leren met ruisachtige voorbeelden
Transformers, de neurale netwerken achter veel moderne visie- en taalsystemen, zijn krachtig maar vaak traag en instabiel om te trainen voor detectietaken. De auteurs introduceren een trainingsschema genaamd Query-based Contrastive Denoising om dit te verhelpen. Tijdens training voegen ze doelbewust ruis toe aan ideale objectaanwijzingen—door de vakjes die auto’s, voetgangers of fietsen markeren licht te verschuiven en van grootte te veranderen—en vragen het model deze vervuilde schattingen te corrigeren. Tegelijkertijd stimuleren ze dat interne kenmerken van hetzelfde type object naar elkaar clusteren, terwijl verschillende types uit elkaar worden gehouden. Deze combinatie helpt het systeem snel te leren wat bijvoorbeeld een bus onderscheidt van een vrachtwagen of achtergrondruis, zelfs als ze in het afgeplatte beeld vergelijkbaar lijken.
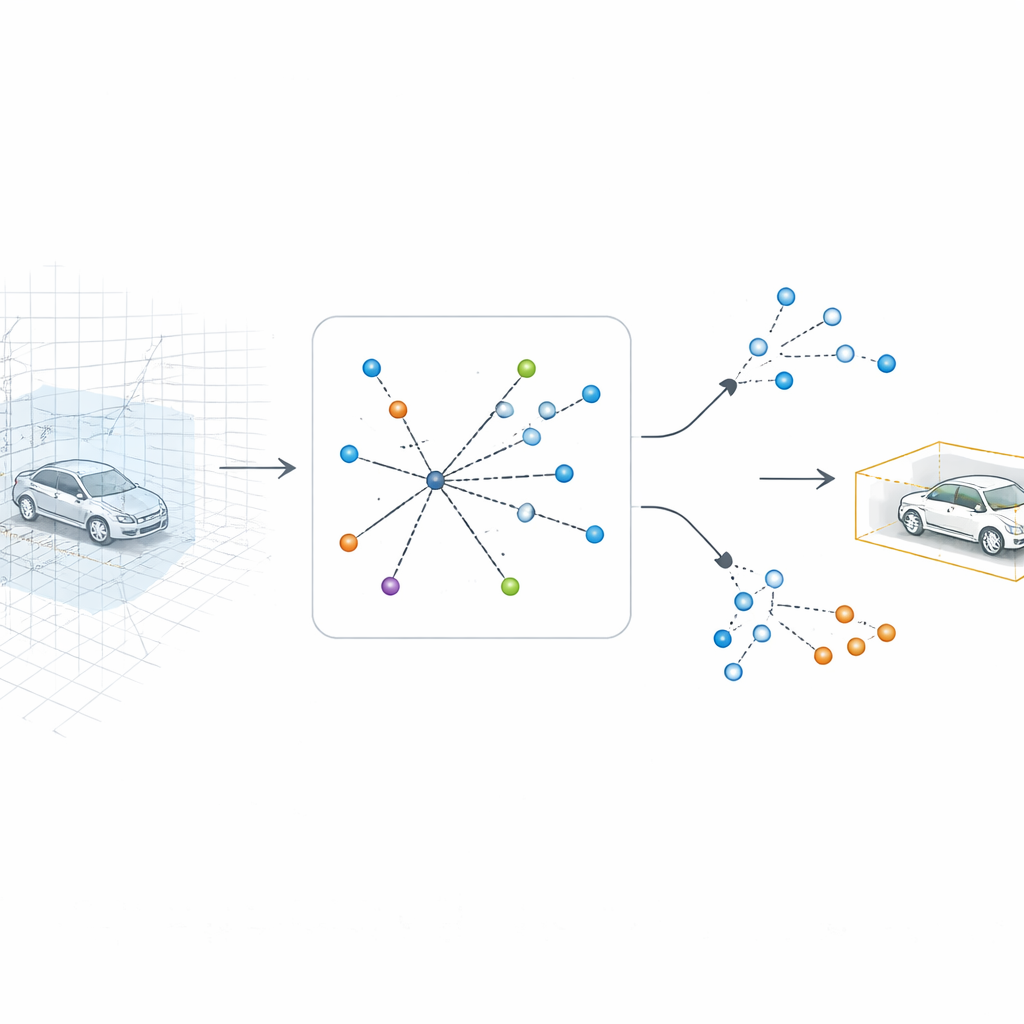
De voordelen aantonen op echte straatdata
Het team testte SV-TransFusion op nuScenes, een veelgebruikte dataset voor autonoom rijden met complexe stedelijke verkeerssituaties. Vergeleken met sterke bestaande methoden, waaronder het populaire TransFusion-model, detecteerde SV-TransFusion objecten nauwkeuriger en schatte hun oriëntatie en beweging betrouwbaarder, en dat alles met slechts een bescheiden toename in rekenkosten. De verbeteringen waren vooral duidelijk voor kleine, hoogtegevoelige categorieën zoals voetgangers en fietsen, en voor objecten die ver weg of deels verborgen zijn—precies de gevallen waarin het verlies van verticale details het meest schadelijk is. De aanpak verbeterde ook verschillende LiDAR-backbones, wat aantoont dat het in veel bestaande systemen kan worden opgenomen.
Wat dit betekent voor veiligere autonomie
In eenvoudige bewoordingen laat SV-TransFusion zelfrijdende auto’s weer in 3D “denken”, zonder snelheid te verliezen. Door detectiemodules toe te staan terug te grijpen naar de ruwe 3D-metingen en door ze te trainen met ruisende, contrastieve voorbeelden, levert de methode een scherper, betrouwbaarder begrip van het wegschema. Dat betekent betere herkenning van kwetsbare weggebruikers, duidelijkere scheiding van soortgelijk ogende voertuigen en zekerder bewegingstracking—allemaal cruciale ingrediënten voor veilig, realtime autonoom rijden.
Bronvermelding: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Trefwoorden: LiDAR 3D-objectdetectie, autonoom rijden, transformermodellen, spaarzame voxels, top-down waarneming