Clear Sky Science · ru
SV-TransFusion для 3D-обнаружения объектов LiDAR с взаимодействием Sparse Voxel–Query
Видеть дорогу в трёх измерениях
Самоуправляемые автомобили должны обнаруживать и отслеживать всё вокруг — от грузовиков и автобусов до велосипедистов и пешеходов — в любых погодных и дорожных условиях. Многие системы опираются на LiDAR, лазерный датчик, который восстанавливает трёхмерную картину мира. Но большинство современных алгоритмов сжимают богатую 3D-информацию в плоский вид сверху, что упрощает вычисления, но теряет важные данные о высоте. В этой работе представлен SV-TransFusion — новый подход, позволяющий сохранить и использовать утраченную 3D-структуру, что приводит к более безопасному и надёжному обнаружению объектов на дороге.
Почему упрощение 3D-данных может быть рискованным
Современные лидеры в детектировании по LiDAR обычно преобразуют облака точек — миллионы измерений расстояний, разбросанных в пространстве — в изображение вида сверху. В такой плоской карте каждый пиксель суммирует всё, что находится над ним, сливая объекты, которые могут существенно отличаться по высоте. Пешеход рядом с высокой стойкой или низкий строительный барьер возле грузовика при виде только сверху могут выглядеть почти одинаково. Этот приём ускоряет обработку, но добавляет неясности, особенно в загроможденных сценах или когда высокие и низкие объекты занимают одну и ту же область на дороге.
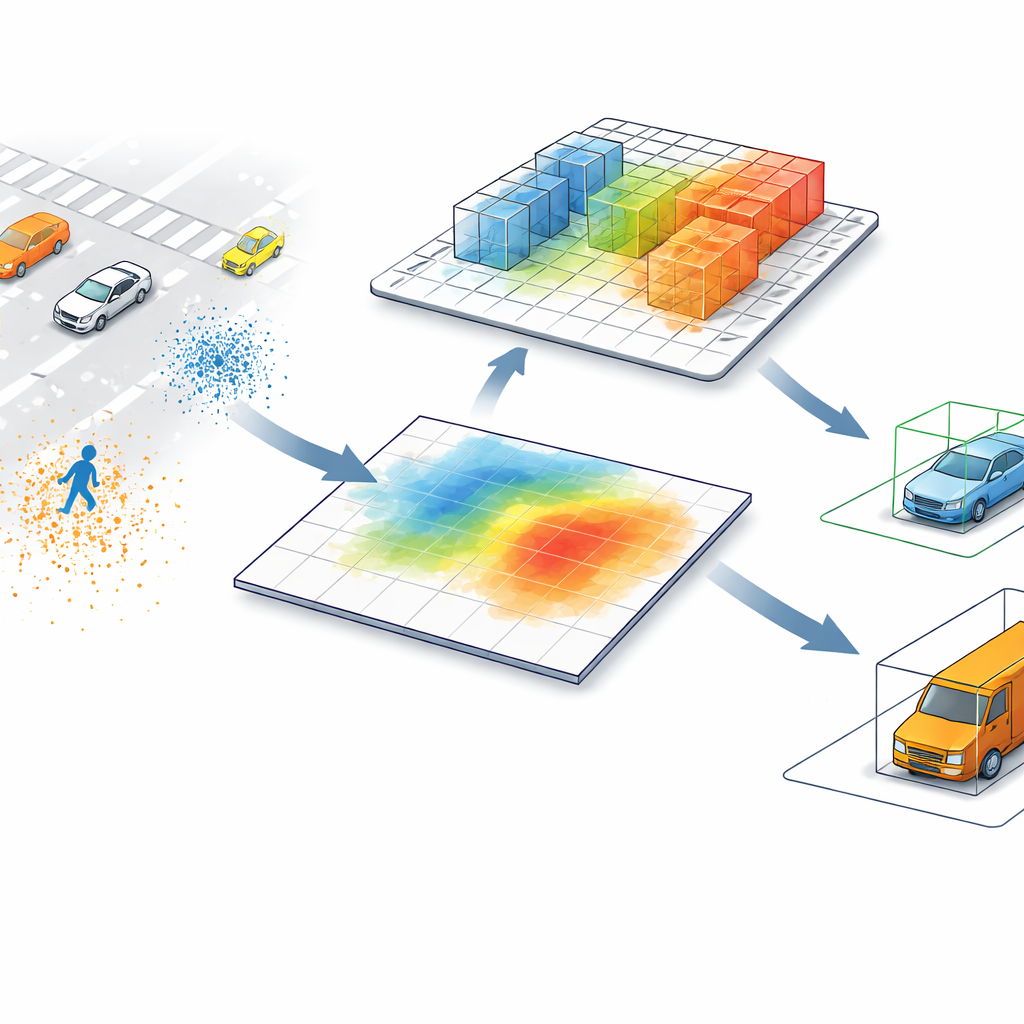
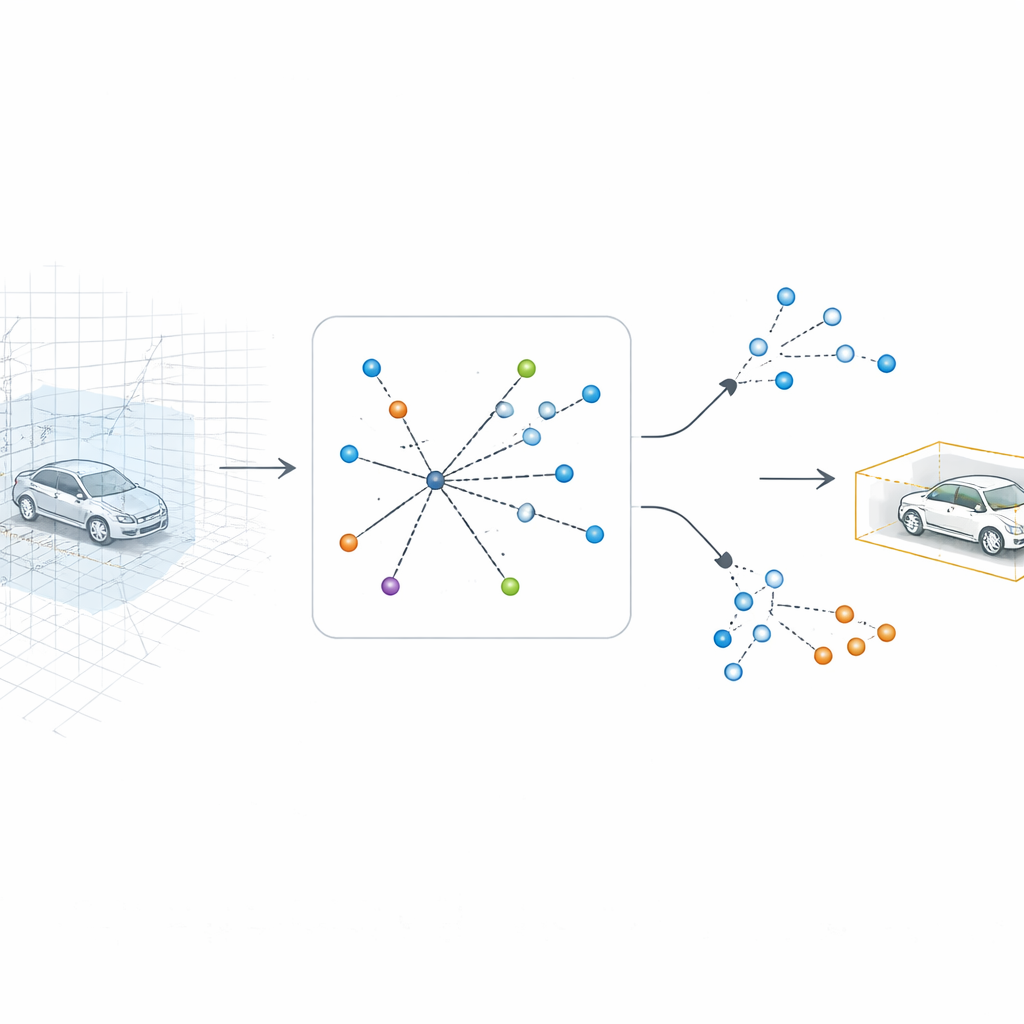
Позволяя системе вернуться к 3D
SV-TransFusion решает эту проблему, восстановив прямую связь детекционной схемы с исходной 3D-структурой. Вместо того чтобы позволять внутренним «запросам объектов» видеть только сплющенную карту, система даёт им возможность выборочно заглядывать в соседние 3D-ячейки объёма, или воксели, которые всё ещё содержат точную информацию о высоте и форме. Специализированный модуль, называемый Sparse Voxel-Query Interaction, обыскивает окрестность каждой предполагаемой позиции объекта и собирает только непустые воксели в этой зоне. Фокусируясь на реально измеренных точках, а не на пустом пространстве, модель восстанавливает тонкие вертикальные признаки, которые иначе теряются.
Быстрое и устойчивое обучение с помощью шумных примеров
Трансформеры, нейронные сети, лежащие в основе многих современных систем обработки зрения и языка, мощны, но часто медленно и нестабильно обучаются для задач детекции. Авторы предлагают схему обучения под названием Query-based Contrastive Denoising. Во время обучения они намеренно добавляют шум к идеальным подсказкам объектов — слегка сдвигают и изменяют размер боксов, отмечающих машины, пешеходов или велосипеды — и просят модель исправить эти шумные догадки. Одновременно они поощряют, чтобы внутренние признаки для одного типа объекта группировались вместе, а признаки разных типов отталкивались друг от друга. Такая комбинация помогает системе быстрее понять, чем, например, автобус отличается от грузовика или фона, даже если в плоском виде они выглядят похоже.
Доказательство преимуществ на реальных уличных данных
Команда протестировала SV-TransFusion на наборе данных nuScenes, широко используемом для автономного вождения с комплексным городским трафиком. По сравнению с сильными существующими методами, включая популярную модель TransFusion, SV-TransFusion точнее обнаруживал объекты и надёжнее оценивал их ориентацию и движение, при этом требуя лишь умеренного увеличения вычислительной нагрузки. Преимущества были особенно заметны для небольших категорий, чувствительных к высоте, таких как пешеходы и велосипеды, а также для удалённых или частично скрытых объектов — именно в тех случаях, когда потеря вертикальной информации наиболее вредна. Подход также улучшал работу различных LiDAR-бекбонов, показывая, что его можно интегрировать в множество существующих систем.
Что это значит для более безопасной автономности
Проще говоря, SV-TransFusion позволяет самоуправляемым автомобилям «думать» снова в 3D, не жертвуя скоростью. Давая модулям детекции доступ к исходным 3D-замерам и обучая их на шумных, контрастных примерах, метод обеспечивает более чёткое и надёжное понимание дорожной сцены. Это значит лучшее распознавание уязвимых участников движения, более чёткое разделение похожих по виду транспортных средств и более уверенное отслеживание движения — всё это ключевые составляющие для безопасного и своевременного автономного вождения.
Цитирование: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Ключевые слова: 3D-обнаружение объектов LiDAR, автономное вождение, модели трансформеров, разреженные воксели, перцепция в виде вида сверху