Clear Sky Science · pl
SV-TransFusion dla wykrywania obiektów 3D w LiDAR z interakcją Sparse Voxel–Query
Widzieć drogę w trzech wymiarach
Samojezdne samochody muszą dostrzegać i śledzić wszystko wokół siebie — od ciężarówek i autobusów po rowerzystów i pieszych — w różnych warunkach pogodowych i ruchowych. Wiele systemów polega na LiDARze, czujniku laserowym budującym trójwymiarowy obraz świata. Jednak większość współczesnych algorytmów spłaszcza te bogate dane 3D do płaskiego widoku z góry, co upraszcza obliczenia, ale pozbawia informacji o wysokości. W artykule przedstawiono SV-TransFusion, nowy sposób pozwalający komputerom zachować i wykorzystać brakującą strukturę 3D, co prowadzi do bezpieczniejszego i bardziej niezawodnego wykrywania obiektów na drodze.
Dlaczego spłaszczanie danych 3D bywa ryzykowne
Obecnie wiodące detektory LiDAR zwykle konwertują chmury punktów — miliony pomiarów odległości rozrzuconych w przestrzeni — na obraz z widoku z góry. W tej płaskiej mapie każdy piksel podsumowuje wszystko, co znajduje się nad nim, łącząc obiekty, które mogą znacznie różnić się wysokością. Pieszy stojący obok wysokiego słupa lub niski barierka budowlana obok ciężarówki mogą wyglądać niemal identycznie, gdy ogląda się je tylko z góry. To uproszczenie przyspiesza przetwarzanie, lecz wprowadza zamieszanie, zwłaszcza w zatłoczonych scenach lub gdy małe i wysokie obiekty zajmują ten sam ślad na jezdni.
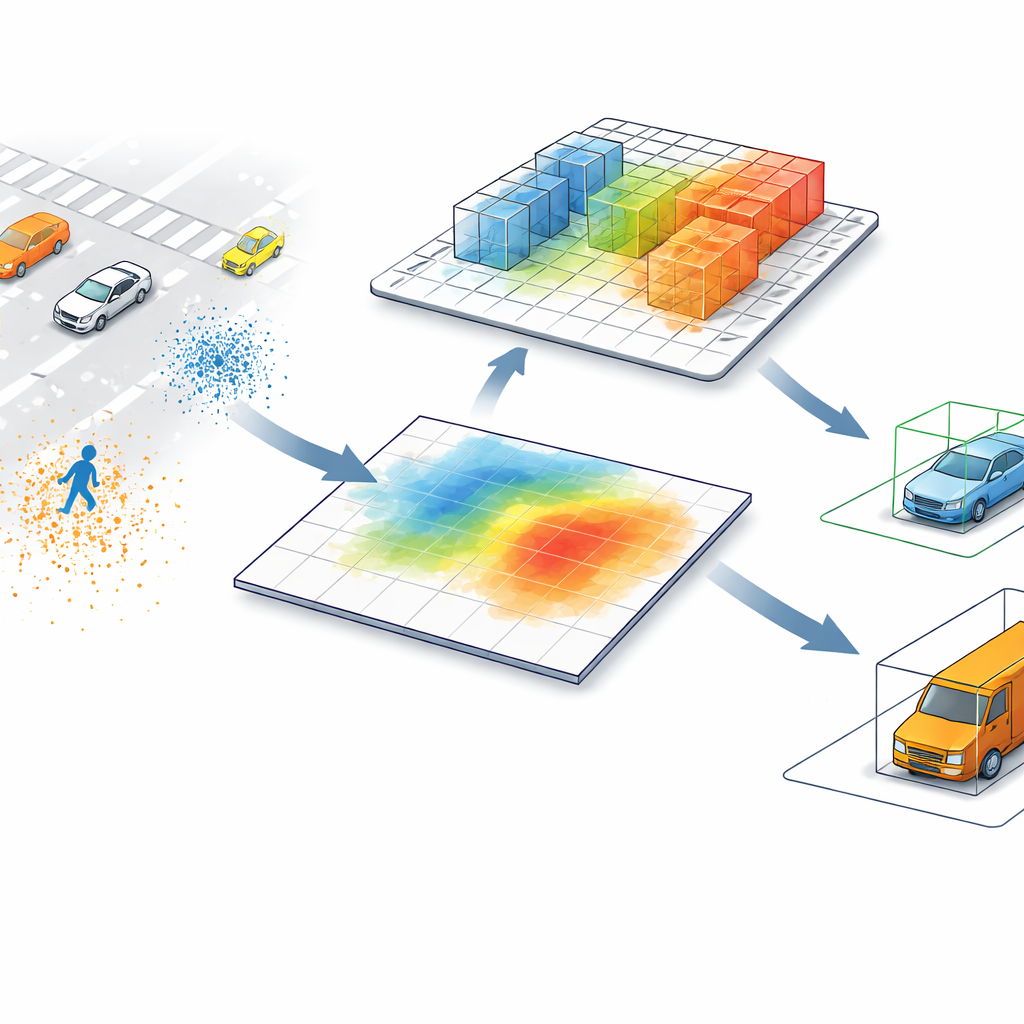
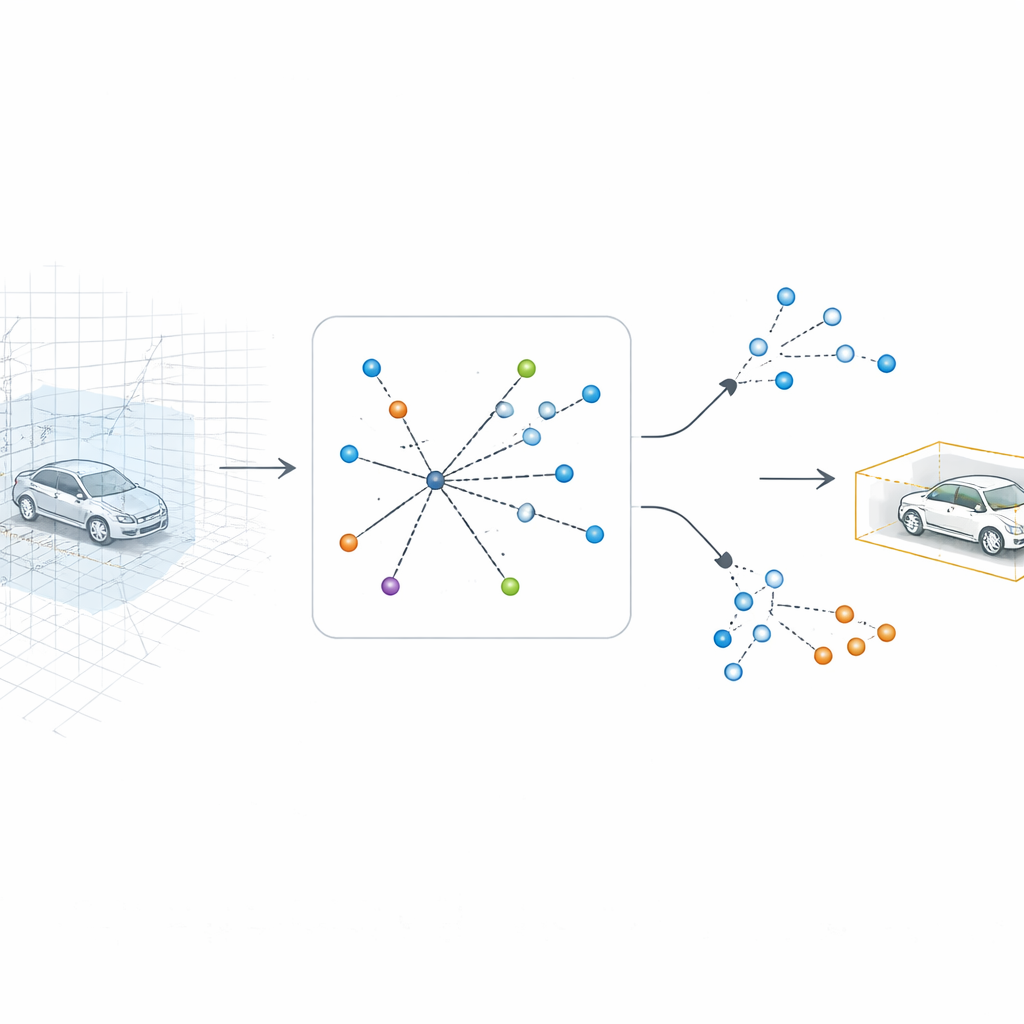
Pozwolić komputerowi spojrzeć z powrotem w 3D
SV-TransFusion rozwiązuje ten problem, ponownie otwierając bezpośrednią linię między algorytmem wykrywania a oryginalną strukturą 3D. Zamiast pozwalać wewnętrznym „zapytywaczom obiektów” widzieć jedynie spłaszczoną mapę, system umożliwia im selektywne sięganie do pobliskich komórek objętości 3D — wokseli — które wciąż zawierają szczegółowe informacje o wysokości i kształcie. Specjalny moduł, zwany Sparse Voxel-Query Interaction, przeszukuje otoczenie każdej wstępnej lokalizacji obiektu i zbiera tylko niepuste woksele z tej okolicy. Koncentrując uwagę na faktycznie zmierzonych punktach, zamiast na pustej przestrzeni, model odzyskuje subtelne wskazówki pionowe, które inaczej zostałyby utracone.
Szybsze, czytelniejsze uczenie dzięki zaszumionym przykładom
Transformatory, sieci neuronowe stojące za wieloma nowoczesnymi systemami widzenia i przetwarzania języka, są potężne, ale często wolne i niestabilne podczas trenowania w zadaniach detekcji. Autorzy wprowadzają schemat treningowy nazwany Query-based Contrastive Denoising, aby temu zaradzić. Podczas treningu celowo dodają szum do idealnych wskazówek obiektów — nieznacznie przesuwając i zmieniając rozmiary ramek oznaczających samochody, pieszych czy rowery — a następnie proszą model o skorygowanie tych zaszumionych zgadywań. Jednocześnie zachęcają wewnętrzne cechy tych samych typów obiektów do grupowania się, a różne typy do oddzielania. To połączenie pomaga systemowi szybko nauczyć się, co odróżnia np. autobus od ciężarówki lub od tła, nawet gdy wydają się podobne na spłaszczonym widoku.
Dowód korzyści na rzeczywistych danych ulicznych
Zespół przetestował SV-TransFusion na nuScenes, szeroko używanym zbiorze danych autonomicznego prowadzenia obejmującym złożony ruch miejski. W porównaniu z silnymi istniejącymi metodami, w tym popularnym modelem TransFusion, SV-TransFusion wykrywał obiekty dokładniej i rzetelniej estymował ich orientację oraz ruch, przy tylko umiarkowanym wzroście obliczeń. Zyski były szczególnie widoczne w przypadku małych kategorii wrażliwych na wysokość, takich jak piesi i rowery, oraz obiektów oddalonych lub częściowo zasłoniętych — dokładnie tam, gdzie utrata informacji pionowej jest najbardziej szkodliwa. Podejście poprawiło też działanie różnych rdzeni LiDAR, pokazując, że można je włączyć do wielu istniejących systemów.
Co to oznacza dla bezpieczniejszej autonomii
Mówiąc prosto, SV-TransFusion pozwala samochodom autonomicznym „myśleć” znowu w 3D, bez poświęcania szybkości. Dzięki umożliwieniu modułom wykrywania sięgania do surowych pomiarów 3D oraz treningowi z zaszumionymi, kontrastowymi przykładami, metoda dostarcza ostrzejsze, bardziej niezawodne rozumienie sceny drogowej. Oznacza to lepsze rozpoznawanie podatnych uczestników ruchu, wyraźniejsze rozdzielanie pojazdów o podobnym wyglądzie i pewniejsze śledzenie ruchu — wszystkie kluczowe składniki bezpiecznej, działającej w czasie rzeczywistym autonomii.
Cytowanie: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Słowa kluczowe: Wykrywanie obiektów 3D z LiDAR, autonomiczna jazda, modele transformerowe, rzadkie woksele, percepcja z widoku z góry