Clear Sky Science · sv
SV-TransFusion för LiDAR 3D-objektdetektion med Sparse Voxel–Query Interaction
Att se vägen i tre dimensioner
Självkörande bilar måste upptäcka och följa allt runt omkring dem — från lastbilar och bussar till cyklister och fotgängare — i alla slags väder och trafikförhållanden. Många system förlitar sig på LiDAR, en laserbaserad sensor som bygger upp en tredimensionell bild av omgivningen. Men de flesta nuvarande algoritmer pressar denna rika 3D-information ner till en platt fågelperspektivbild, vilket förenklar matematiken men kastar bort viktiga höjddetaljer. Denna artikel presenterar SV-TransFusion, ett nytt sätt för datorer att bevara och använda den saknade 3D-strukturen, vilket leder till säkrare och mer pålitlig detektion av objekt på vägen.
Varför det kan vara riskabelt att platta ut 3D-data
Dagens ledande LiDAR-detektorer omvandlar ofta punktmoln — miljontals avståndsmätningar utspridda i rummet — till en fågelperspektivbild. I den platta kartan sammanfattar varje pixel allt ovanför den och slår ihop objekt som kan skilja sig mycket i höjd. En fotgängare bredvid en hög stolpe, eller ett lågt byggstaket nära en lastbil, kan se nästan identiska ut när de bara betraktas uppifrån. Denna genväg snabbar upp bearbetningen, men den skapar också förvirring, särskilt i röriga scenarier eller när små och höga objekt delar samma avtryck på vägbanan.
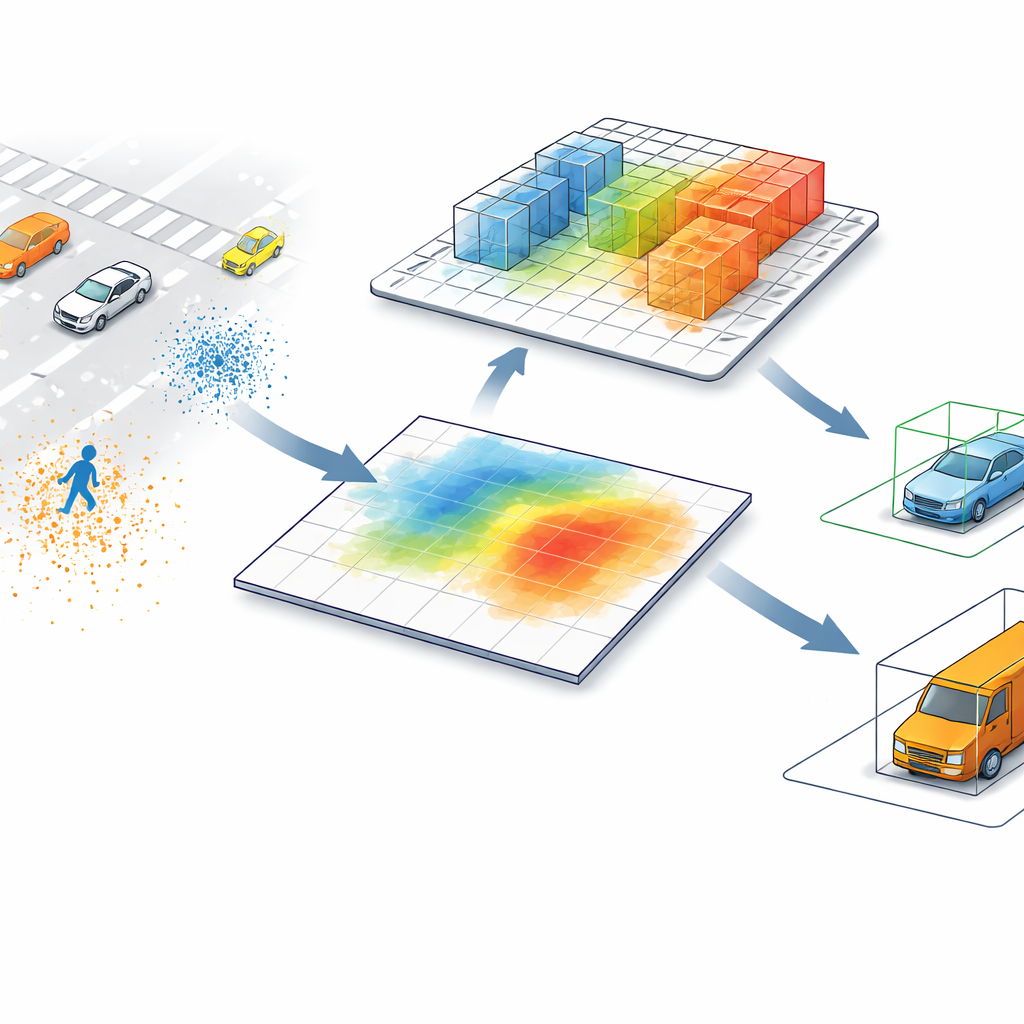
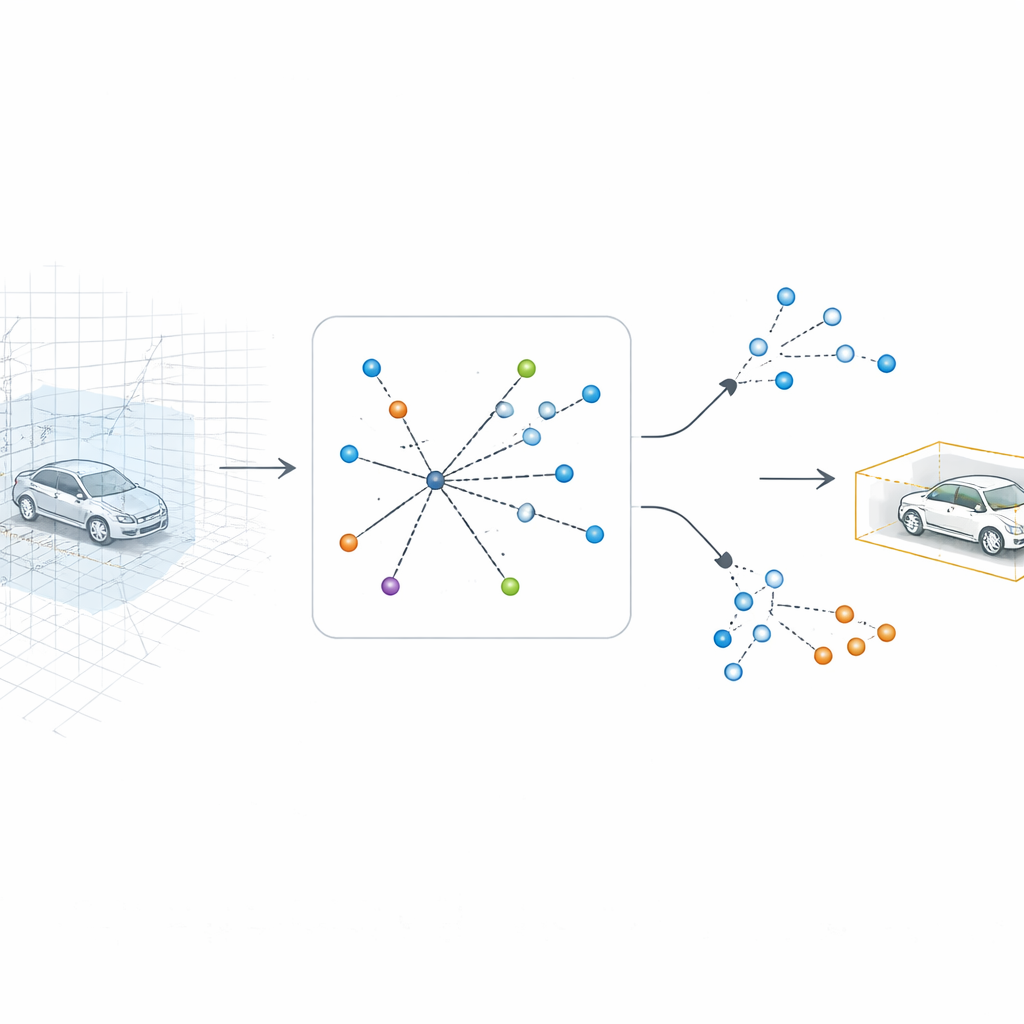
Låta datorn titta tillbaka in i 3D
SV-TransFusion tar itu med detta problem genom att återöppna en direkt förbindelse från detektionsalgoritmen tillbaka till den ursprungliga 3D-strukturen. Istället för att låta sina interna "object queries" bara se den plattade kartan, låter systemet dem selektivt nå in i närliggande 3D-volymceller, eller voxlar, som fortfarande rymmer fin information om höjd och form. En specialiserad modul, kallad Sparse Voxel-Query Interaction, söker runt varje tentativ objektposition och samlar endast de icke-tomma voxlarna i det området. Genom att fokusera uppmärksamheten på de faktiska uppmätta punkterna, snarare än tomt utrymme, återvinner modellen subtila vertikala ledtrådar som annars skulle gå förlorade.
Snabbare, tydligare inlärning genom bullriga exempel
Transformers, de neurala nätverk som ligger bakom många moderna syn- och språksystem, är kraftfulla men ofta långsamma och instabila att träna för detektionsuppgifter. Författarna introducerar ett träningsschema kallat Query-based Contrastive Denoising för att hantera detta. Under träningen tillsätter de avsiktligt brus till idealiska objekthintar — genom att lätt förskjuta och ändra storlek på rutorna som markerar bilar, fotgängare eller cyklar — och ber sedan modellen rätta dessa brusiga gissningar. Samtidigt uppmuntrar de interna representationerna för samma objekttyp att klustra ihop sig, samtidigt som olika typer skjuts ifrån varandra. Denna kombination hjälper systemet att snabbt lära sig vad som skiljer till exempel en buss från en lastbil eller bakgrundsrubriser, även när de ser lika ut i den plattade vyn.
Bevisa fördelarna på verkliga gatudata
Teamet testade SV-TransFusion på nuScenes, en vida använd dataset för autonom körning med komplex urban trafik. Jämfört med starka befintliga metoder, inklusive den populära TransFusion-modellen, upptäckte SV-TransFusion objekt mer exakt och uppskattade deras orientering och rörelse mer pålitligt — allt med endast en måttlig ökning i beräkning. Vinsterna var särskilt tydliga för små, höjdkänsliga kategorier som fotgängare och cyklar, och för objekt som ligger långt bort eller är delvis dolda — precis de fall där förlorad vertikal detalj är mest skadlig. Metoden förbättrade också en rad olika LiDAR-backbones, vilket visar att den kan kopplas in i många befintliga system.
Vad detta betyder för säkrare autonomi
Enkelt uttryckt låter SV-TransFusion självkörande bilar "tänka" i 3D igen, utan att offra hastighet. Genom att tillåta detektionsmoduler att nå tillbaka till de råa 3D-mätningarna och genom att träna dem med bullriga, kontrastiva exempel levererar metoden skarpare och mer pålitlig förståelse av vägsituationen. Det innebär bättre igenkänning av sårbara trafikanter, tydligare åtskillnad mellan liknande fordon och mer säker spårning av rörelse — alla avgörande ingredienser för säker, realtidsautonom körning.
Citering: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Nyckelord: LiDAR 3D-objektdetektion, autonom körning, transformermodeller, sparsa voxlar, fågelperspektivsuppfattning