Clear Sky Science · it
SV-TransFusion per il rilevamento di oggetti 3D con LiDAR tramite Sparse Voxel–Query Interaction
Vedere la strada in tre dimensioni
Le auto a guida autonoma devono individuare e tracciare tutto ciò che le circonda — dai camion e autobus ai ciclisti e pedoni — in ogni condizione meteorologica e di traffico. Molti sistemi si basano sul LiDAR, un sensore laser che costruisce un’immagine 3D dell’ambiente. Ma la maggior parte degli algoritmi attuali comprime queste ricche informazioni tridimensionali in una vista piana dall’alto, che semplifica i calcoli ma sacrifica dettagli importanti sull’altezza. Questo articolo presenta SV-TransFusion, un nuovo approccio che permette ai sistemi di conservare e sfruttare quella struttura 3D mancante, portando a un rilevamento degli oggetti sulla strada più sicuro e affidabile.
Perché appiattire i dati 3D può essere rischioso
I migliori rilevatori LiDAR odierni tipicamente convertono le nuvole di punti — milioni di misurazioni di distanza sparse nello spazio — in un’immagine bird’s-eye-view. In quella mappa piatta, ogni pixel riassume tutto ciò che si trova sopra di esso, fondendo oggetti che possono variare molto in altezza. Un pedone accanto a un palo alto, o una barriera bassa vicino a un camion, possono apparire quasi identici visti solo dall’alto. Questa scorciatoia accelera l’elaborazione, ma introduce anche confusione, specialmente in scene affollate o quando oggetti piccoli e alti condividono la stessa impronta sulla carreggiata.
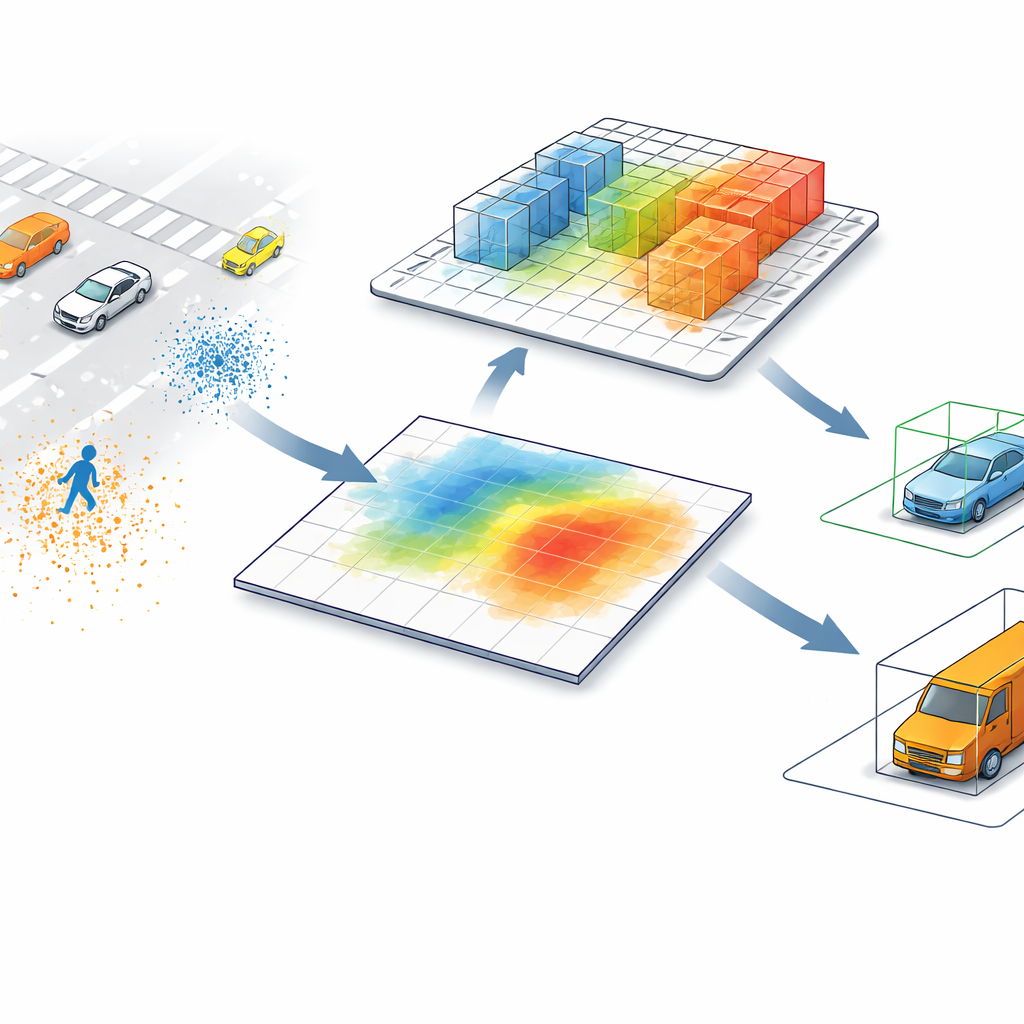
Permettere al computer di guardare di nuovo nella 3D
SV-TransFusion affronta questo problema riaprendo una linea diretta dall’algoritmo di rilevamento alla struttura 3D originale. Invece di permettere alle sue “query di oggetto” interne di vedere solo la mappa appiattita, il sistema consente loro di accedere selettivamente alle celle volumetriche 3D vicine, o voxel, che mantengono ancora informazioni dettagliate su altezza e forma. Un modulo specializzato, chiamato Sparse Voxel-Query Interaction, esplora l’intorno di ogni posizione oggettiva provvisoria e raccoglie solo i voxel non vuoti in quel quartiere. Concentrando l’attenzione sui punti effettivamente misurati, piuttosto che sullo spazio vuoto, il modello recupera indizi verticali sottili che altrimenti andrebbero persi.
Apprendimento più rapido e chiaro tramite esempi rumorosi
I transformer, le reti neurali dietro molti sistemi moderni di visione e linguaggio, sono potenti ma spesso lenti e instabili da addestrare per compiti di rilevamento. Gli autori introducono uno schema di addestramento chiamato Query-based Contrastive Denoising per affrontare questo. Durante l’addestramento, aggiungono deliberatamente rumore agli indizi ideali sugli oggetti — spostando e ridimensionando leggermente le scatole che segnano auto, pedoni o biciclette — e poi chiedono al modello di correggere queste ipotesi rumorose. Allo stesso tempo, incentivano le caratteristiche interne per lo stesso tipo di oggetto a raggrupparsi, mentre separano quelle di tipi differenti. Questa combinazione aiuta il sistema a imparare rapidamente cosa distingue, per esempio, un autobus da un camion o dal rumore di fondo, anche quando appaiono simili nella vista appiattita.
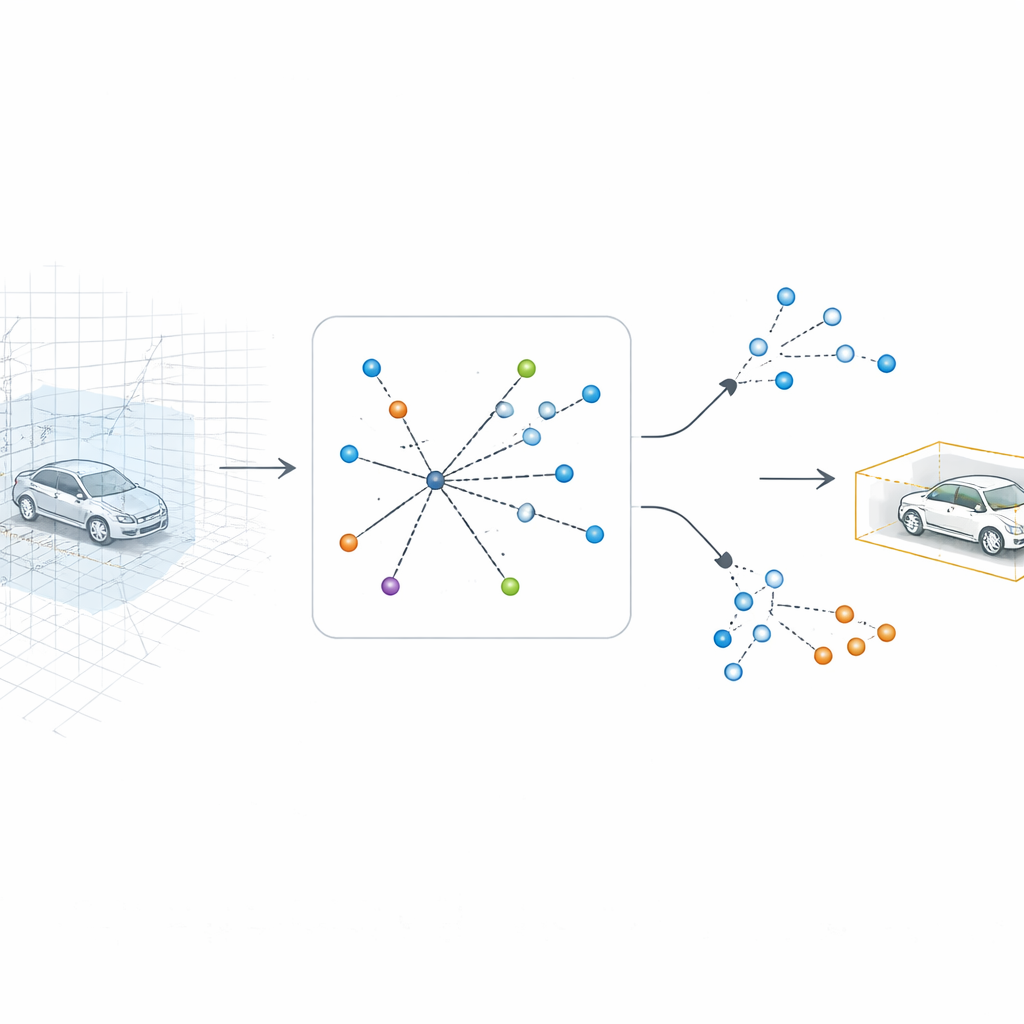
Dimostrare i benefici su dati reali di strada
Il team ha testato SV-TransFusion su nuScenes, un dataset ampiamente utilizzato per la guida autonoma con traffico urbano complesso. Rispetto a metodi consolidati, incluso il popolare modello TransFusion, SV-TransFusion ha rilevato gli oggetti con maggiore accuratezza e stimato con più affidabilità la loro orientazione e il movimento, il tutto con un aumento di calcolo solo modesto. I miglioramenti sono risultati particolarmente evidenti per categorie di piccole dimensioni sensibili all’altezza come pedoni e biciclette, e per oggetti lontani o parzialmente nascosti — esattamente i casi in cui la perdita di dettaglio verticale è più dannosa. L’approccio ha inoltre migliorato diverse backbone LiDAR, mostrando che può essere integrato in molti sistemi esistenti.
Cosa significa questo per una guida autonoma più sicura
In termini semplici, SV-TransFusion permette alle auto a guida autonoma di “pensare” di nuovo in 3D, senza sacrificare la velocità. Consentendo ai moduli di rilevamento di tornare alle misure 3D grezze e addestrandoli con esempi rumorosi e contrastivi, il metodo fornisce una comprensione della scena stradale più nitida e affidabile. Ciò si traduce in un riconoscimento migliore degli utenti deboli della strada, in una separazione più chiara di veicoli dall’aspetto simile e in un tracciamento del movimento più sicuro e sicuro — tutti ingredienti cruciali per una guida autonoma in tempo reale e sicura.
Citazione: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Parole chiave: Rilevamento oggetti 3D con LiDAR, guida autonoma, modelli transformer, voxel sparsi, percezione dall’alto (bird’s-eye-view)