Clear Sky Science · ar
SV-TransFusion لاكتشاف الأشياء ثلاثية الأبعاد من LiDAR مع تفاعل الاستعلام مع الفوكسلات المتناثرة
رؤية الطريق في ثلاثة أبعاد
على السيارات ذاتية القيادة أن تكتشف وتتتبع كل ما يحيط بها — من الشاحنات والحافلات إلى راكبي الدراجات والمشاة — في جميع الأحوال الجوية وحالات المرور. تعتمد العديد من الأنظمة على LiDAR، وهو مستشعر ليزري يبني صورة ثلاثية الأبعاد للعالم. لكن معظم الخوارزميات الحالية تضغط هذه المعلومات الثلاثية الأبعاد الغنية إلى رؤية مسطحة من أعلى، ما يُبسط الحسابات لكنه يتجاهل تفاصيل هامة حول الارتفاع. تقدم هذه الورقة SV-TransFusion، طريقة جديدة للحفاظ على تلك البنية الثلاثية الأبعاد المفقودة واستخدامها، ما يؤدي إلى اكتشاف أكثر أمانًا وموثوقية للأجسام على الطريق.
لماذا يمكن أن يكون تسطيح البيانات ثلاثية الأبعاد مخاطرة
تحول أجهزة كشف LiDAR الرائدة اليوم عادة سحب النقاط — ملايين القياسات من المسافات المبعثرة في الفضاء — إلى صورة من منظور طائر. في تلك الخريطة المسطحة، يلخص كل بكسل كل ما فوقه، ما يدمج أجسامًا قد تختلف كثيرًا في الارتفاع. قد يبدو المشي بجانب عمود طويل، أو حاجز بناء منخفض قرب شاحنة، متشابهين تقريبًا عند النظر إليهما من الأعلى فقط. هذه الحيلة تُسرّع المعالجة، لكنها تخلق أيضًا لبسًا، خاصة في المشاهد المزدحمة أو عندما تشترك أجسام قصيرة وطويلة في نفس البصمة على الطريق.
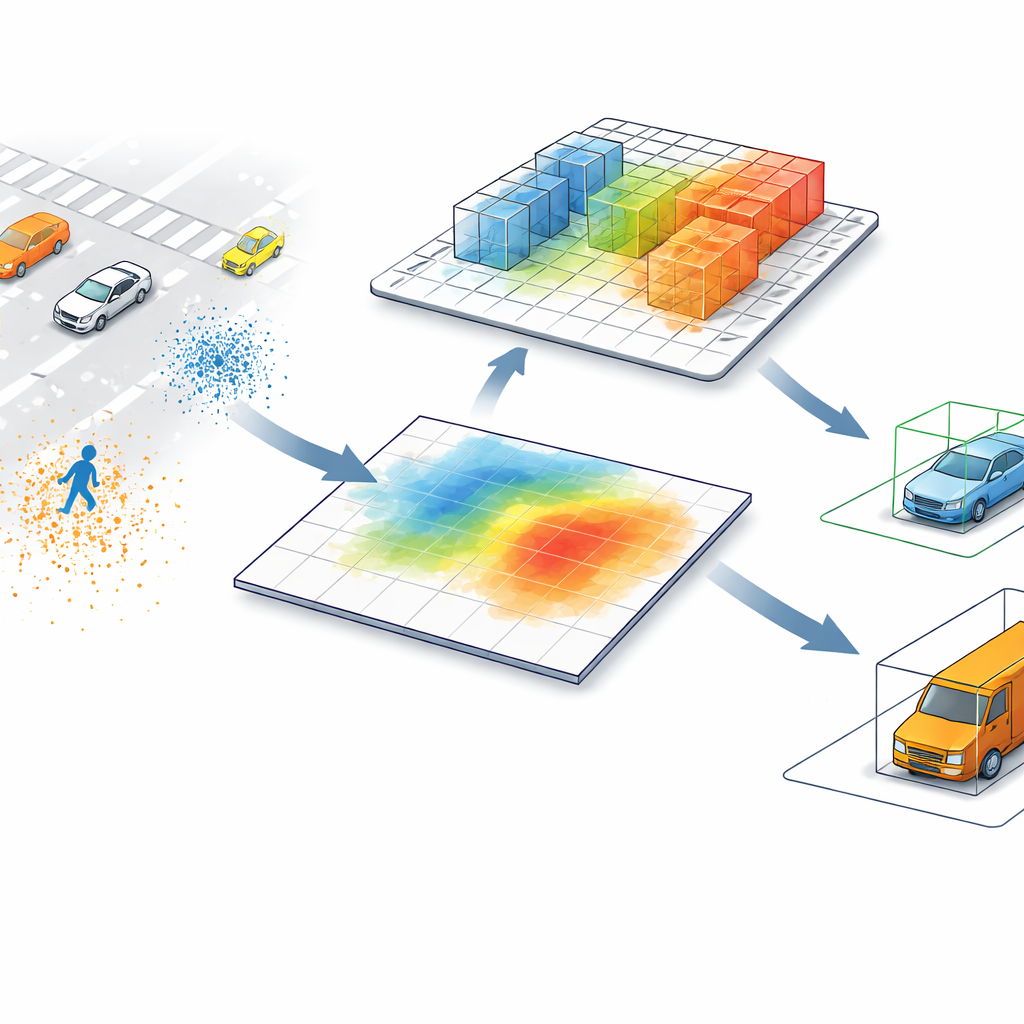
إتاحة الاطلاع على البنية ثلاثية الأبعاد
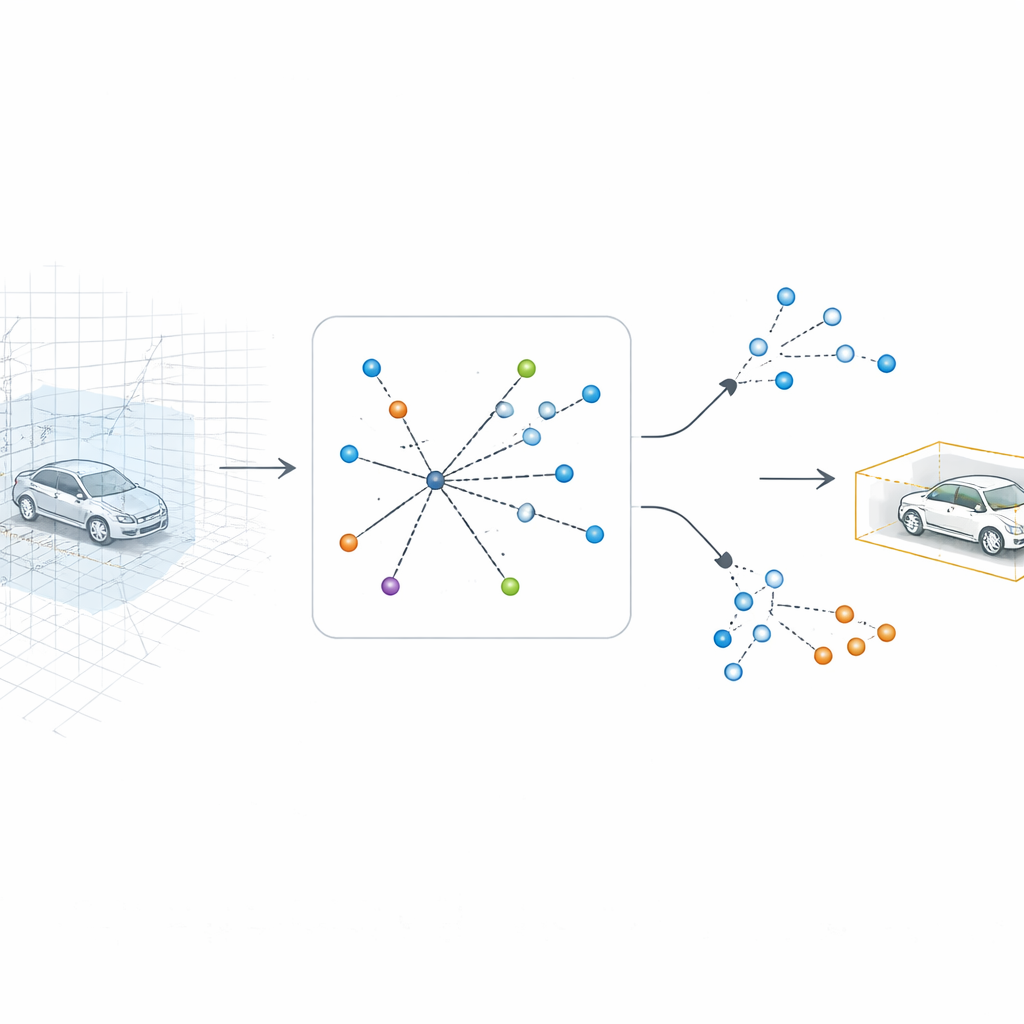
يتعامل SV-TransFusion مع هذه المشكلة بإعادة فتح خط مباشر من خوارزمية الكشف إلى البنية الثلاثية الأبعاد الأصلية. بدلاً من أن ترى «استعلامات الكائن» الداخلية الخريطة المسطحة فقط، يسمح النظام لها بالوصول انتقائيًا إلى خلايا حجم ثلاثية الأبعاد قريبة، أو فوكسلات، التي لا تزال تحتفظ بمعلومات دقيقة عن الارتفاع والشكل. تبحث وحدة متخصصة، تُسمى تفاعل الفوكسل-الاستعلام المتناثر، حول كل موقع كائن مؤقت وتجميع فقط الفوكسلات غير الفارغة في تلك الجوار. من خلال تركيز الانتباه على النقاط المقاسة فعلًا بدلاً من الفراغ، تسترجع النموذج دلائل رأسية دقيقة كانت ستضيع بخلاف ذلك.
تعلّم أسرع أوضح عبر أمثلة مضطربة
المحولات، الشبكات العصبية وراء العديد من أنظمة الرؤية واللغة الحديثة، قوية لكنها غالبًا بطيئة وغير مستقرة عند التدريب لمهام الكشف. قدم المؤلفون مخطط تدريب يسمى إزالة التشويش التبايني القائم على الاستعلام (Query-based Contrastive Denoising) لمعالجة ذلك. أثناء التدريب، يضيفون عمدًا ضوضاء إلى مؤشرات الكائن المثالية — بتحريك وتغيير حجم الصناديق التي تشير إلى السيارات أو المشاة أو الدراجات قليلاً — ثم يطلبون من النموذج تصحيح هذه التخمينات المشوَّشة. في الوقت نفسه، يشجعون الميزات الداخلية لنفس نوع الكائن على التجمع معًا، بينما يدفعون الأنواع المختلفة بعيدًا. تساعد هذه التركيبة النظام على تعلم سريع لما يميز، على سبيل المثال، حافلة عن شاحنة أو عن خلفية فوضوية، حتى عندما تبدو متشابهة في الرؤية المسطحة.
إثبات الفوائد على بيانات الشوارع الحقيقية
اختبر الفريق SV-TransFusion على مجموعة بيانات nuScenes، وهي مجموعة مستخدمة على نطاق واسع للقيادة الذاتية تضم حركة مرور حضرية معقدة. مقارنة بالأساليب القوية القائمة، بما في ذلك نموذج TransFusion الشائع، كشف SV-TransFusion عن الأجسام بدقة أعلى وقدَّر اتجاهها وحركتها بمزيد من الموثوقية، مع زيادة بسيطة فقط في الحساب. كانت المكاسب واضحة بشكل خاص للفئات الحساسة للارتفاع مثل المشاة والدراجات، وللأجسام البعيدة أو المخفية جزئيًا — وهي بالضبط الحالات التي يكون فيها فقدان التفاصيل الرأسية أكثر ضررًا. كما حسّن النهج مجموعة من هياكل LiDAR الأساسية المختلفة، مما يبيّن إمكانية توصيله بأنظمة موجودة متعددة.
ماذا يعني هذا لسلامة القيادة الذاتية
ببساطة، يتيح SV-TransFusion للسيارات ذاتية القيادة «التفكير» في ثلاثة أبعاد مرة أخرى، من دون التضحية بالسرعة. من خلال السماح لوحدات الكشف بالوصول مرة أخرى إلى القياسات الثلاثية الأبعاد الخام وبالتدريب على أمثلة مشوشة وتباينية، يقدم الأسلوب فهمًا أوضح وأكثر موثوقية لمشهد الطريق. وهذا يعني تعرفًا أفضل على مستخدمي الطريق الضعفاء، وفصلًا أوضح للمركبات المتشابهة المظهر، وتتبع حركة أكثر ثقة — وكلها عناصر أساسية للقيادة الذاتية الآمنة في الزمن الحقيقي.
الاستشهاد: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
الكلمات المفتاحية: كشف الأشياء ثلاثية الأبعاد باستخدام LiDAR, القيادة الذاتية, نماذج المحولات, الفوكسلات المتناثرة, إدراك العرض العلوي (bird’s-eye-view)