Clear Sky Science · es
SV-TransFusion para detección de objetos 3D con LiDAR mediante Interacción Consulta–Voxeles Dispersos
Ver la carretera en tres dimensiones
Los coches autónomos deben detectar y seguir todo lo que les rodea —desde camiones y autobuses hasta ciclistas y peatones— en todo tipo de condiciones meteorológicas y de tráfico. Muchos sistemas se apoyan en LiDAR, un sensor basado en láser que construye una imagen 3D del entorno. Pero la mayoría de los algoritmos actuales comprimen esta rica información 3D en una vista plana desde arriba, lo que facilita los cálculos pero descarta detalles importantes sobre la altura. Este artículo presenta SV-TransFusion, una nueva forma de que los ordenadores conserven y utilicen esa estructura 3D perdida, lo que conduce a una detección de objetos en carretera más segura y fiable.
Por qué puede ser arriesgado aplanar datos 3D
Los detectores de LiDAR punteros de hoy suelen convertir nubes de puntos —millones de mediciones de distancia dispersas en el espacio— en una imagen en vista cenital. En ese mapa plano, cada píxel resume todo lo que hay por encima, fusionando objetos que pueden diferir mucho en altura. Un peatón junto a un poste alto, o una barrera baja de obra cerca de un camión, pueden parecer casi idénticos vistos solo desde arriba. Este atajo acelera el procesamiento, pero también introduce confusión, especialmente en escenas con mucha información o cuando objetos pequeños y altos comparten la misma huella en la calzada.
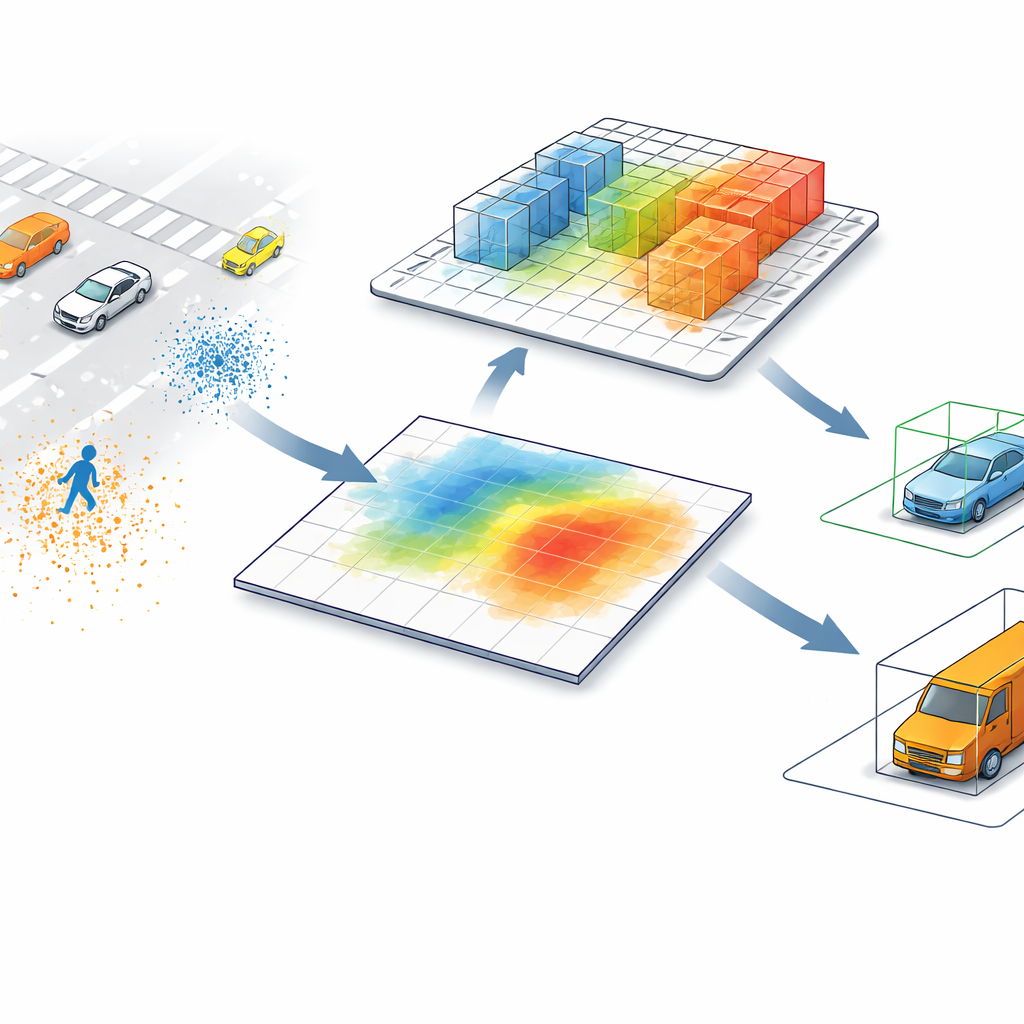
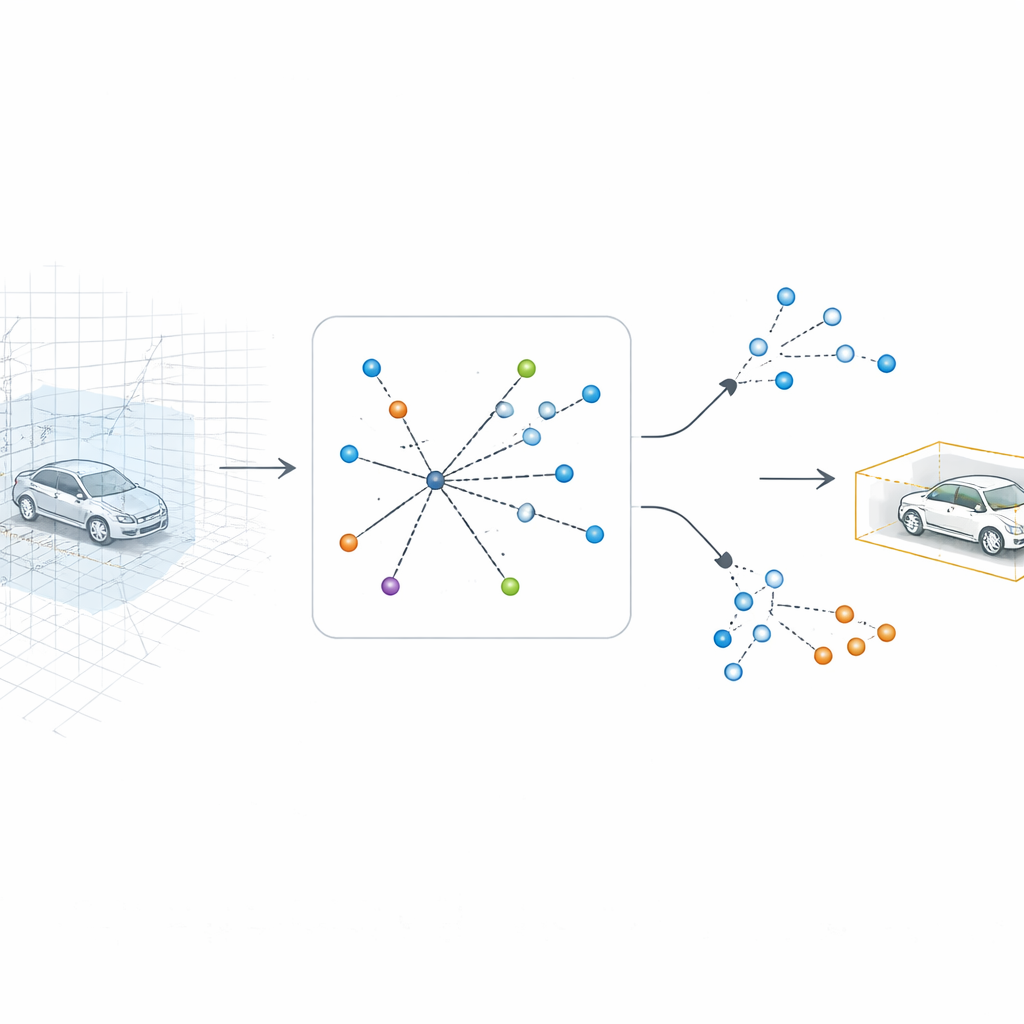
Permitir que el ordenador vuelva a mirar al 3D
SV-TransFusion aborda este problema reabriendo una vía directa desde el algoritmo de detección hasta la estructura 3D original. En lugar de permitir que sus "consultas de objeto" internas vean solo el mapa aplanado, el sistema les permite acceder selectivamente a celdas de volumen 3D cercanas, o voxeles, que siguen conteniendo información fina de altura y forma. Un módulo especializado, llamado Interacción Consulta–Voxeles Dispersos, busca alrededor de cada ubicación de objeto tentativa y reúne solo los voxeles no vacíos en ese vecindario. Al centrar la atención en los puntos realmente medidos, en lugar del espacio vacío, el modelo recupera pistas verticales sutiles que de otro modo se perderían.
Aprendizaje más rápido y claro mediante ejemplos ruidosos
Los transformers, las redes neuronales detrás de muchos sistemas modernos de visión y lenguaje, son potentes pero a menudo lentos e inestables de entrenar para tareas de detección. Los autores introducen un esquema de entrenamiento llamado Desruido Contrastivo basado en Consultas para abordar esto. Durante el entrenamiento, aplican deliberadamente ruido a indicios ideales de objetos —desplazando y redimensionando ligeramente las cajas que marcan coches, peatones o bicicletas— y piden al modelo que corrija esas conjeturas ruidosas. Al mismo tiempo, fomentan que las características internas del mismo tipo de objeto se agrupen, mientras separan las de tipos diferentes. Esta combinación ayuda al sistema a aprender rápidamente qué distingue, por ejemplo, a un autobús de un camión o del ruido de fondo, incluso cuando aparecen similares en la vista aplanada.
Demostrando los beneficios con datos reales de calle
El equipo probó SV-TransFusion en nuScenes, un conjunto de datos ampliamente usado en conducción autónoma con tráfico urbano complejo. En comparación con métodos existentes fuertes, incluido el popular modelo TransFusion, SV-TransFusion detectó objetos con mayor precisión y estimó su orientación y movimiento de forma más fiable, todo ello con solo un aumento modesto del cálculo. Las mejoras fueron especialmente notables en categorías pequeñas y sensibles a la altura, como peatones y bicicletas, y en objetos lejanos o parcialmente ocultos —justo los casos en los que perder el detalle vertical resulta más perjudicial. El enfoque también mejoró diversos backbones de LiDAR, mostrando que puede integrarse en muchos sistemas existentes.
Qué significa esto para una autonomía más segura
En términos sencillos, SV-TransFusion permite que los coches autónomos "piensen" en 3D de nuevo, sin sacrificar la velocidad. Al permitir que los módulos de detección vuelvan a acceder a las mediciones 3D sin procesar y entrenarlos con ejemplos ruidosos y contrastivos, el método ofrece una comprensión de la escena vial más nítida y fiable. Eso se traduce en mejor reconocimiento de usuarios vulnerables de la vía, una separación más clara entre vehículos de aspecto similar y un seguimiento de movimiento más seguro y confiado —todos ingredientes cruciales para la conducción autónoma segura en tiempo real.
Cita: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Palabras clave: detección de objetos 3D con LiDAR, conducción autónoma, modelos transformer, voxeles dispersos, percepción en vista cenital