Clear Sky Science · pt
SV-TransFusion para detecção de objetos 3D com LiDAR usando Interação Esparsa Voxel–Consulta
Vendo a estrada em três dimensões
Carros autônomos precisam identificar e rastrear tudo ao redor — de caminhões e ônibus a ciclistas e pedestres — em todos os tipos de clima e trânsito. Muitos sistemas dependem do LiDAR, um sensor a laser que constrói uma imagem 3D do mundo. Mas a maioria dos algoritmos atuais comprime essa rica informação 3D em uma vista plana de cima, o que facilita os cálculos, mas descarta detalhes importantes sobre a altura. Este artigo apresenta o SV-TransFusion, uma nova abordagem para os computadores preservarem e usarem essa estrutura 3D faltante, levando a uma detecção de objetos na estrada mais segura e confiável.
Por que achatar dados 3D pode ser arriscado
Os detectores de LiDAR mais avançados normalmente convertem nuvens de pontos — milhões de medidas de distância espalhadas no espaço — em uma imagem em vista aérea. Nesse mapa plano, cada pixel resume tudo que está acima dele, fundindo objetos que podem diferir muito em altura. Um pedestre ao lado de um poste alto, ou uma barreira de construção baixa perto de um caminhão, podem parecer quase idênticos quando vistos apenas de cima. Esse atalho acelera o processamento, mas também introduz confusão, especialmente em cenas cheias de elementos ou quando objetos pequenos e altos compartilham a mesma projeção no chão.
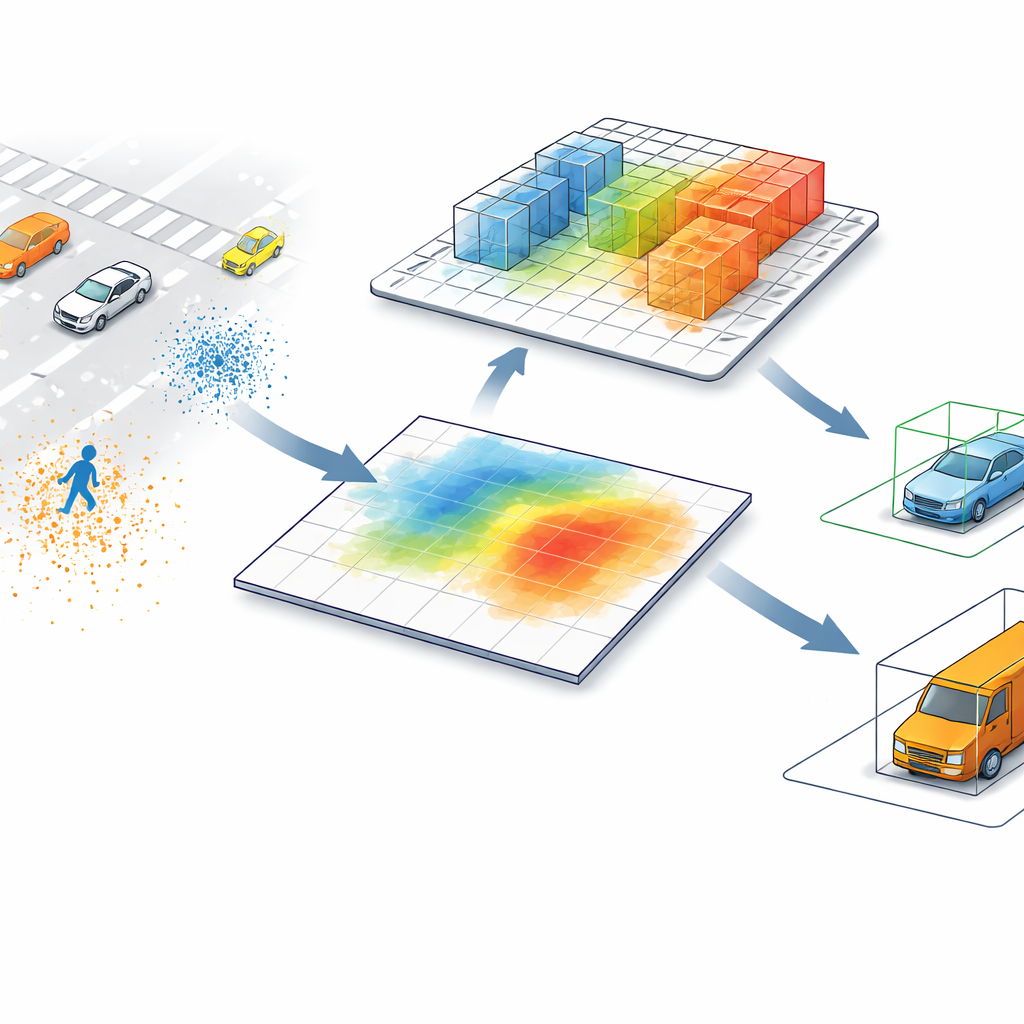
Deixando o computador olhar de volta para o 3D
O SV-TransFusion aborda esse problema reabrindo uma linha direta do algoritmo de detecção de volta para a estrutura 3D original. Em vez de permitir que suas “consultas de objeto” internas vejam apenas o mapa achatado, o sistema deixa que elas alcancem seletivamente células de volume 3D próximas, ou voxels, que ainda preservam informações finas de altura e forma. Um módulo especializado, chamado Sparse Voxel-Query Interaction, procura ao redor de cada localização de objeto proposta e agrupa apenas os voxels não vazios naquela vizinhança. Ao concentrar a atenção nos pontos efetivamente medidos, em vez do espaço vazio, o modelo recupera pistas verticais sutis que seriam perdidas de outra forma.
Aprendizado mais rápido e claro por meio de exemplos ruidosos
Transformers, as redes neurais por trás de muitos sistemas modernos de visão e linguagem, são poderosos, mas frequentemente lentos e instáveis para treinar em tarefas de detecção. Os autores introduzem um esquema de treinamento chamado Query-based Contrastive Denoising para tratar disso. Durante o treinamento, eles adicionam deliberadamente ruído a dicas ideais de objeto — deslocando e redimensionando ligeiramente as caixas que marcam carros, pedestres ou bicicletas — e então pedem ao modelo que corrija essas estimativas ruidosas. Ao mesmo tempo, incentivam que as representações internas para o mesmo tipo de objeto se agrupem, enquanto empurram tipos diferentes para longe. Essa combinação ajuda o sistema a aprender rapidamente o que faz, por exemplo, um ônibus ser diferente de um caminhão ou de ruído de fundo, mesmo quando parecem semelhantes na vista achatada.
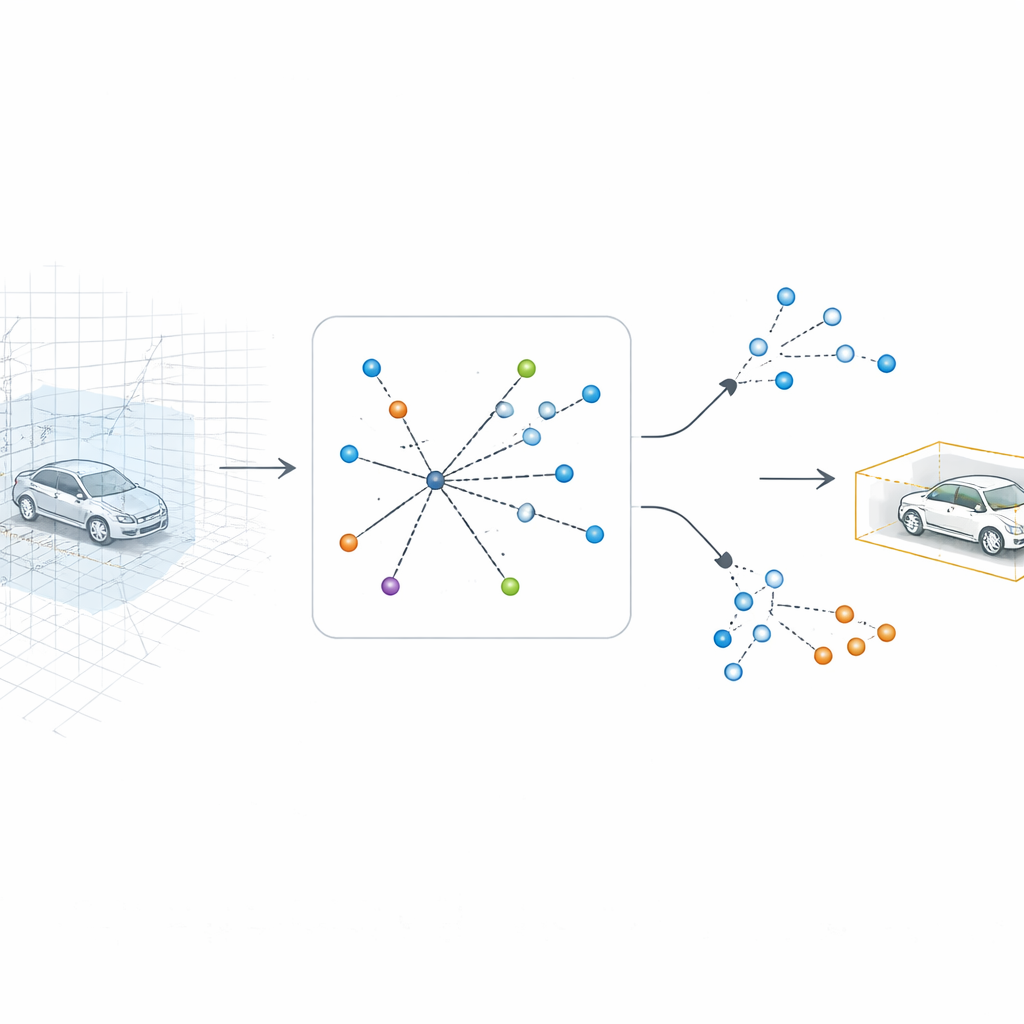
Comprovando os benefícios em dados de rua reais
A equipe testou o SV-TransFusion no nuScenes, um conjunto de dados amplamente usado em condução autônoma com tráfego urbano complexo. Em comparação com métodos existentes robustos, incluindo o popular modelo TransFusion, o SV-TransFusion detectou objetos com mais precisão e estimou sua orientação e movimento de forma mais confiável, tudo com apenas um aumento modesto no custo computacional. Os ganhos foram especialmente claros para categorias pequenas e sensíveis à altura, como pedestres e bicicletas, e para objetos distantes ou parcialmente ocultos — exatamente os casos em que perder detalhes verticais é mais prejudicial. A abordagem também melhorou uma variedade de diferentes backbones de LiDAR, mostrando que pode ser integrada a muitos sistemas existentes.
O que isso significa para uma autonomia mais segura
Em termos simples, o SV-TransFusion permite que carros autônomos “pensem” novamente em 3D, sem sacrificar a velocidade. Ao permitir que os módulos de detecção acessem as medições 3D brutas e ao treiná-los com exemplos ruidosos e contrastivos, o método oferece uma compreensão mais nítida e confiável da cena rodoviária. Isso se traduz em melhor reconhecimento de usuários vulneráveis da via, separação mais clara de veículos de aparência semelhante e rastreamento de movimento mais confiante — todos ingredientes cruciais para uma condução autônoma segura em tempo real.
Citação: Shi, T. SV-TransFusion for LiDAR 3D object detection with Sparse Voxel–Query Interaction. Sci Rep 16, 13375 (2026). https://doi.org/10.1038/s41598-026-42093-y
Palavras-chave: detecção de objetos 3D com LiDAR, condução autônoma, modelos transformer, voxels esparsos, percepção em vista aérea