Clear Sky Science · zh
基于神经风格化的端到端示例驱动仿真到现实强化学习策略迁移及其在机器人切割中的应用
教会机器人在现实中切割
机器人在计算机仿真中学习复杂任务的能力越来越强,但在转入现实世界时常常遇到困难——摩擦、磨损和混乱的材料使一切变得更不可预测。本文探讨了一种新的方法来弥合这一差距,使在仿真中学会安全高效切割的机器人能够在真实、未知材料上保持这种能力,而无需大量额外的真实世界训练数据。
从屏幕到车间为何如此困难
强化学习让机器人通过试错发现有效策略,但现实世界的试验可能缓慢、危险且昂贵。因此工程师常在仿真中训练——在那里数百万次练习既便宜又安全。问题在于仿真中的切割总比现实干净。在实验室里,刀具会抖动、电机有松弛、材料差异大且传感器会漂移。这些差异造成了“领域差距”:在仿真中看似出色的策略在真实硬件上可能表现不佳甚至危险。现有的解决方案要么依赖可能不准确的精细物理模型,要么依赖每当硬件、传感器或材料变化就需重新训练的大型深度学习系统。
借用数码艺术的一个想法
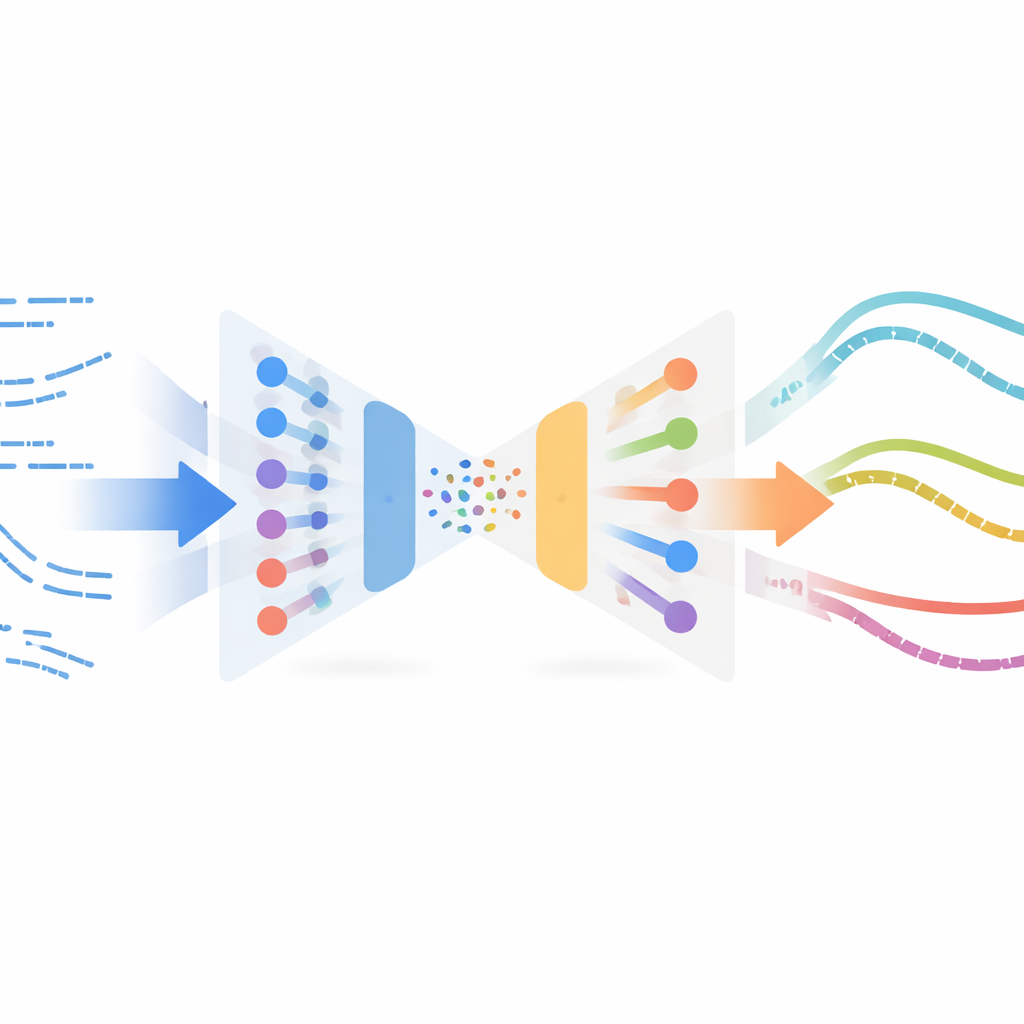
作者借鉴了图像处理领域中一个出人意料的概念——神经风格迁移。在图像应用中,风格迁移把一张图像的内容(例如照片)与另一张图像的风格(例如画作)融合成新图。这里不是对图片操作,而是把“内容”定义为机器人随时间的仿真切割行为,“风格”则是真实切割在传感器数据中的表现。该方法使用变分自编码器来学习短运动片段的紧凑表示,变分自编码器是一类能够压缩并重建时间序列的神经网络。这个网络首先仅在仿真轨迹上训练,使其能够可靠地编码和解码机器人状态与动作,而无需任何来自真实试验的标签或奖励。
将真实感注入仿真体验
一旦该编码器训练完成,系统便把所有可用的真实世界切割示例(离策略收集,意味着并非来自最终的精炼控制器)也输入同一网络。在这个共享的潜在空间中,感觉相似的仿真片段和真实片段会彼此靠近。该方法随后使用相似性度量将仿真片段与附近的真实片段配对,并执行风格迁移优化:温和地改变每个仿真片段,使其保持任务结构(例如机器人何时以及如何推进材料)同时带上真实传感器读数的统计特征。这些风格化片段构成了一个代理“真实”数据集,自动带有仿真中的专家动作标签,随后通过模仿学习用于训练用于物理机器人的新策略。
将方法付诸测试
研究人员在一台配备电动切缝锯的协作机器人上测试了他们的方法,切割了包括泡沫、纸板、塑料、云母和铝在内的多种材料。机器人需要沿着平面、错位和平滑曲面路径移动,并在行进过程中调整进给速度、切割深度和刚度。基于风格迁移的新策略与若干替代方案进行了比较:直接使用在仿真中训练的专家、先前添加手工修正模型的方法,以及两种先进的深度学习转换方案(条件变分自编码器和CycleGAN)。在多个案例研究中,风格迁移策略比原始仿真专家和基于GAN的方法切割更快,并在性能上与更复杂的替代方法相当或更好,同时保持了稳定行为和更平滑的刀具轨迹。
这对未来机器人意味着什么
简单来说,这项研究表明机器人可以在无需广泛再训练或精确物理模型的前提下“借用”真实世界的感觉。通过将仿真技能与真实传感器数据的风格相融合,机器人学会了在不同材料和形状上都能良好迁移的切割策略,即使无法获得来自真实世界的直接奖励反馈。这使得在要求高、接触密集的任务(如拆解、回收甚至外科手术)中部署基于强化学习的控制更加可行——这些场景中在真实系统上大量试验受限且错误代价高昂。
引用: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
关键词: 仿真到现实迁移, 机器人切割, 强化学习, 神经风格迁移, 领域自适应