Clear Sky Science · pt
Transferência de política RL sim‑to‑real baseada em exemplos de ponta a ponta com estilização neural aplicada ao corte robótico
Ensinando Robôs a Cortar no Mundo Real
Robôs estão ficando melhores em aprender tarefas complexas em simulações por computador, mas frequentemente têm dificuldade quando são levados ao mundo real, onde atritos, desgaste e materiais desordenados tornam tudo menos previsível. Este artigo explora uma nova maneira de reduzir essa lacuna para que um robô que aprenda a cortar materiais de forma segura e eficiente em simulação possa continuar a fazê‑lo em materiais reais e desconhecidos, sem necessidade de grandes quantidades de dados de treino reais.
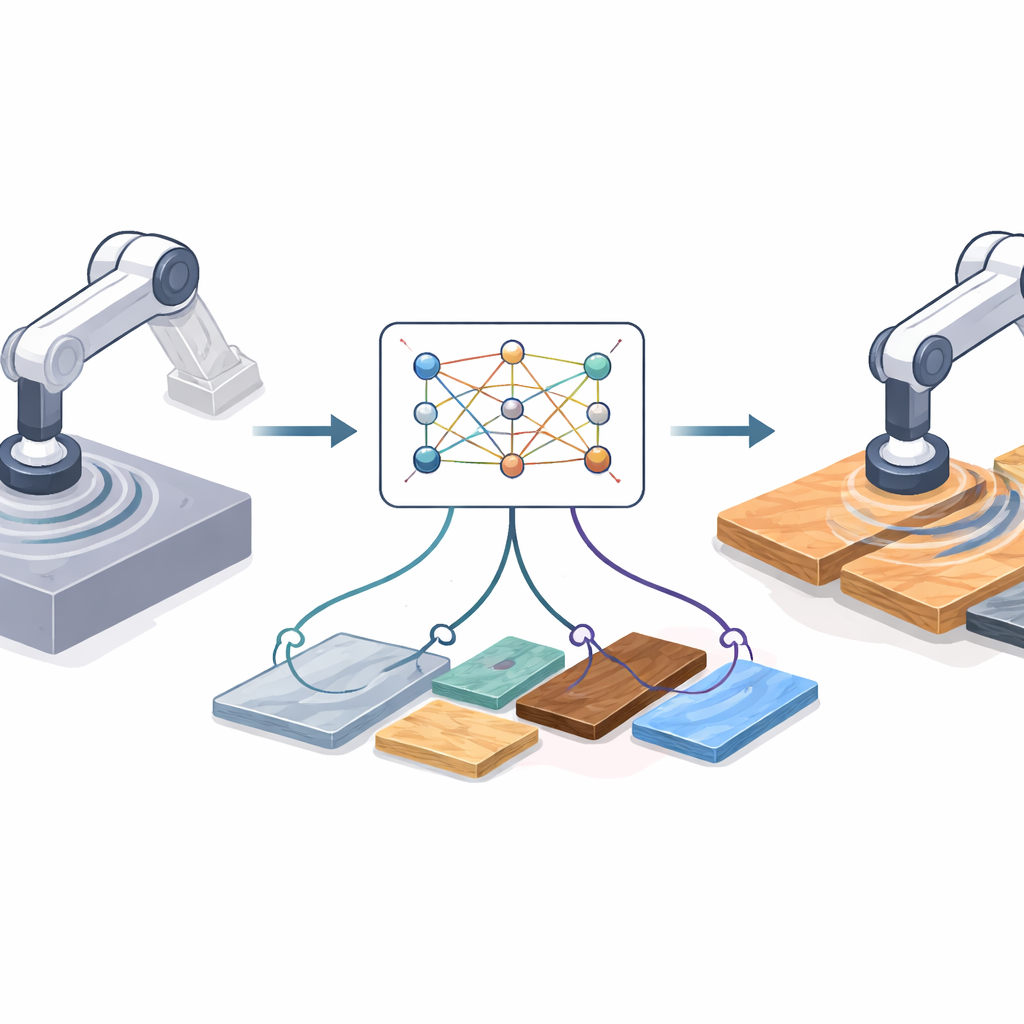
Por que ir da Tela à Oficina é Difícil
O aprendizado por reforço permite que um robô descubra boas estratégias por tentativa e erro, mas experimentos no mundo real podem ser lentos, arriscados e caros. Em vez disso, engenheiros frequentemente treinam em simulação, onde milhões de ensaios são baratos e seguros. O problema é que o corte simulado é sempre mais limpo que a realidade. No laboratório, a ferramenta do robô pode vibrar, os motores têm folgas, os materiais variam e os sensores derivam. Essas diferenças criam uma “lacuna de domínio”: uma política que parece brilhante na simulação pode ter desempenho ruim ou até perigoso no hardware real. Correções existentes dependem ou de modelos físicos detalhados — que podem estar errados — ou de complexos sistemas de deep learning que precisam ser retreinados sempre que o hardware, sensores ou materiais mudam.
Tomando uma Ideia da Arte Digital
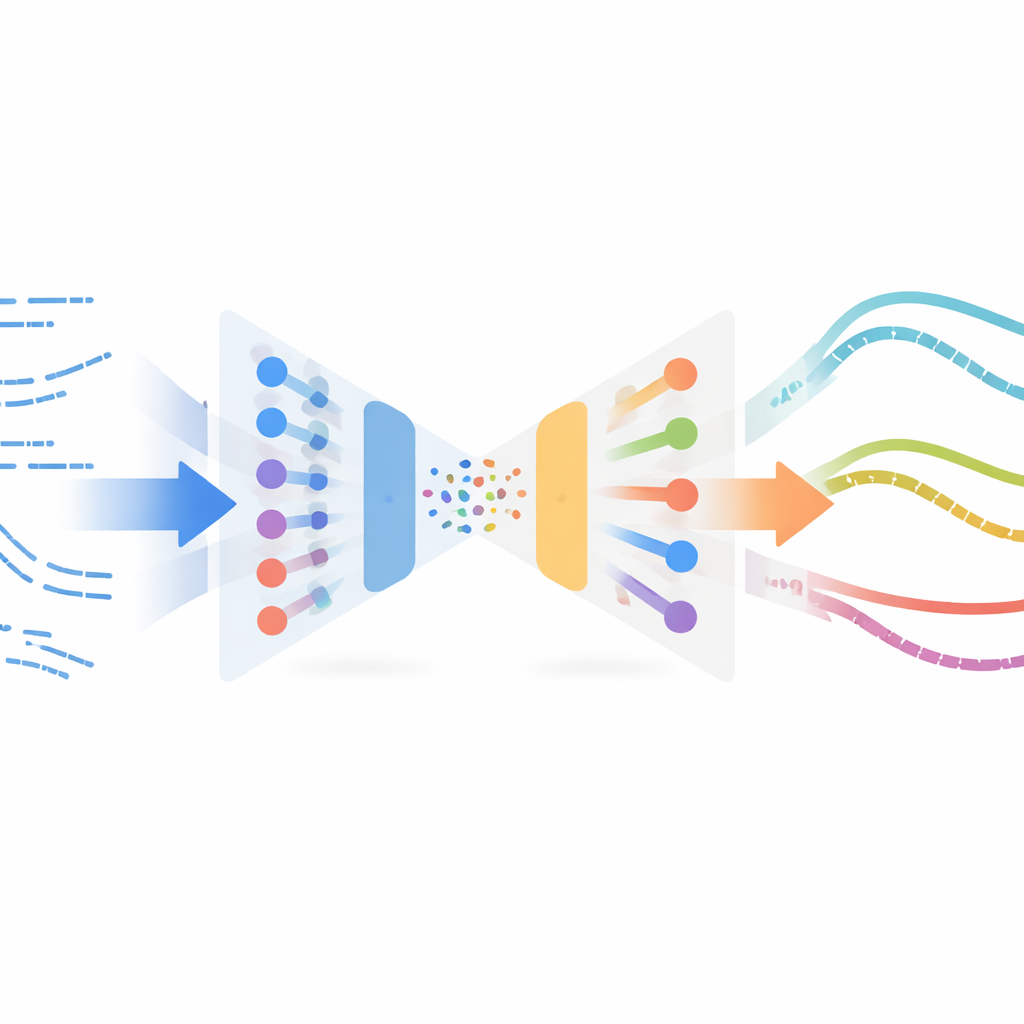
Os autores adaptam um conceito surpreendente do processamento de imagens chamado transferência de estilo neural. Em aplicativos de imagem, a transferência de estilo combina o conteúdo de uma imagem (por exemplo, uma fotografia) com o estilo de outra (por exemplo, uma pintura) e os funde em uma nova imagem. Aqui, em vez de imagens, o “conteúdo” é o comportamento de corte do robô ao longo do tempo, e o “estilo” é como o corte real aparece nos dados dos sensores. O método aprende uma representação compacta de pequenos trechos de movimento usando um autoencoder variacional, um tipo de rede neural que comprime e reconstrói séries temporais. Essa rede é treinada inicialmente apenas com trajetórias simuladas para que possa codificar e decodificar estados e ações do robô de forma confiável, sem precisar de rótulos ou recompensas de experimentos reais.
Misturando a Sensação do Mundo Real na Experiência Simulada
Uma vez treinado esse codificador, o sistema alimenta todos os exemplos de corte do mundo real disponíveis — coletados off‑policy, isto é, não a partir de um controlador final refinado — pela mesma rede. Nesse espaço latente compartilhado, trechos simulados e reais que “se sentem” semelhantes acabam próximos. O método então pareia trechos simulados com trechos reais próximos usando uma medida de similaridade e realiza uma otimização de transferência de estilo: altera suavemente cada trecho simulado para que ele mantenha sua estrutura de tarefa (por exemplo, quando e como o robô avança no material) enquanto adota as assinaturas estatísticas das leituras reais dos sensores. Esses trechos estilizados formam um conjunto de dados substituto “real”, rotulado automaticamente com as ações especialistas da simulação, e são então usados para treinar uma nova política para o robô físico via aprendizado por imitação.
Colocando o Método à Prova
Os pesquisadores testaram sua abordagem em um robô colaborativo equipado com uma serra de corte motorizada, cortando uma variedade de materiais incluindo espuma, papelão, plástico, mica e alumínio. O robô teve de seguir trajetórias sobre superfícies planas, desalinhadas e curvas, ajustando a velocidade de avanço, a profundidade de corte e a rigidez ao longo do processo. A nova política baseada em transferência de estilo foi comparada a diversas alternativas: usar diretamente o especialista treinado na simulação, um método anterior que adicionava um modelo corretivo feito à mão, e duas esquemas avançados de tradução por aprendizado profundo (um autoencoder variacional condicional e um CycleGAN). Nos estudos de caso, a política com transferência de estilo cortou mais rápido do que o especialista bruto da simulação e do que o método baseado em GAN, alcançando desempenho similar ou superior às alternativas mais complexas, enquanto mantinha comportamento estável e trajetórias de ferramenta mais suaves.
O Que Isso Significa para Robôs do Futuro
Em termos simples, o estudo mostra que robôs podem “emprestar a sensação” da experiência do mundo real sem grande retraining ou modelos físicos precisos. Ao mesclar habilidade simulada com o estilo dos dados reais de sensores, o robô aprende uma estratégia de corte que se transfere bem para diferentes materiais e formas, mesmo quando feedbacks diretos de recompensa do mundo real não estão disponíveis. Isso torna mais prático o uso de controle baseado em aprendizado por reforço em tarefas exigentes e com muitos contatos, como desmontagem, reciclagem ou até cirurgia, onde experimentar no sistema real é limitado e erros são custosos.
Citação: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Palavras-chave: transferência sim‑to‑real, corte robótico, aprendizado por reforço, transferência de estilo neural, adaptação de domínio