Clear Sky Science · pl
Przykład end-to-end transferu polityki RL z symulacji do rzeczywistości oparty na neuralnym stylizowaniu z zastosowaniem do robotycznego cięcia
Uczenie robotów cięcia w świecie rzeczywistym
Roboty coraz lepiej radzą sobie z nauką skomplikowanych zadań w symulacjach komputerowych, ale często mają problemy po przeniesieniu do rzeczywistości, gdzie tarcie, zużycie i nieporządek materiałów sprawiają, że wszystko staje się mniej przewidywalne. Artykuł przedstawia nowy sposób zmniejszania tej przepaści, dzięki czemu robot, który nauczył się bezpiecznie i wydajnie ciąć materiały w symulacji, może robić to samo na rzeczywistych, nieznanych materiałach, bez potrzeby gromadzenia ogromnych ilości danych treningowych z prawdziwego świata.
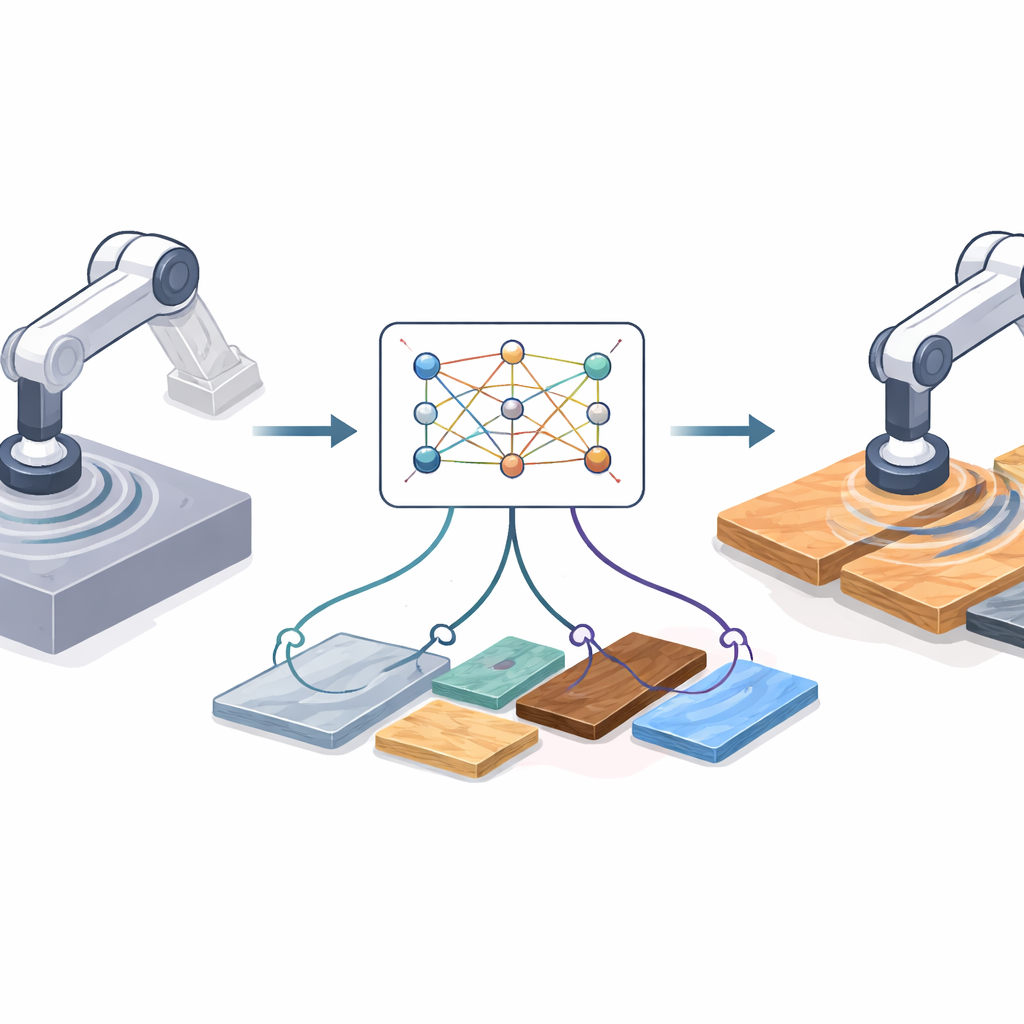
Dlaczego przejście z ekranu do warsztatu jest trudne
Uczenie przez wzmacnianie pozwala robotowi odkrywać dobre strategie metodą prób i błędów, ale próby w świecie rzeczywistym bywają wolne, ryzykowne i kosztowne. Dlatego inżynierowie często trenują w symulacji, gdzie miliony prób są tanie i bezpieczne. Problem w tym, że symulowane cięcie jest zawsze czystsze niż rzeczywistość. W laboratorium narzędzie robota może wibrować, silniki mają luz, materiały się różnią, a czujniki dryfują. Te różnice tworzą „lukę domenową”: polityka, która wygląda świetnie w symulacji, może działać słabo lub nawet niebezpiecznie na rzeczywistym sprzęcie. Istniejące rozwiązania opierają się albo na szczegółowych modelach fizycznych — które mogą być nieprecyzyjne — albo na rozbudowanym uczeniu głębokim, które trzeba ponownie trenować za każdym razem, gdy zmienia się sprzęt, czujniki lub materiały.
Zapożyczenie pomysłu z cyfrowej sztuki
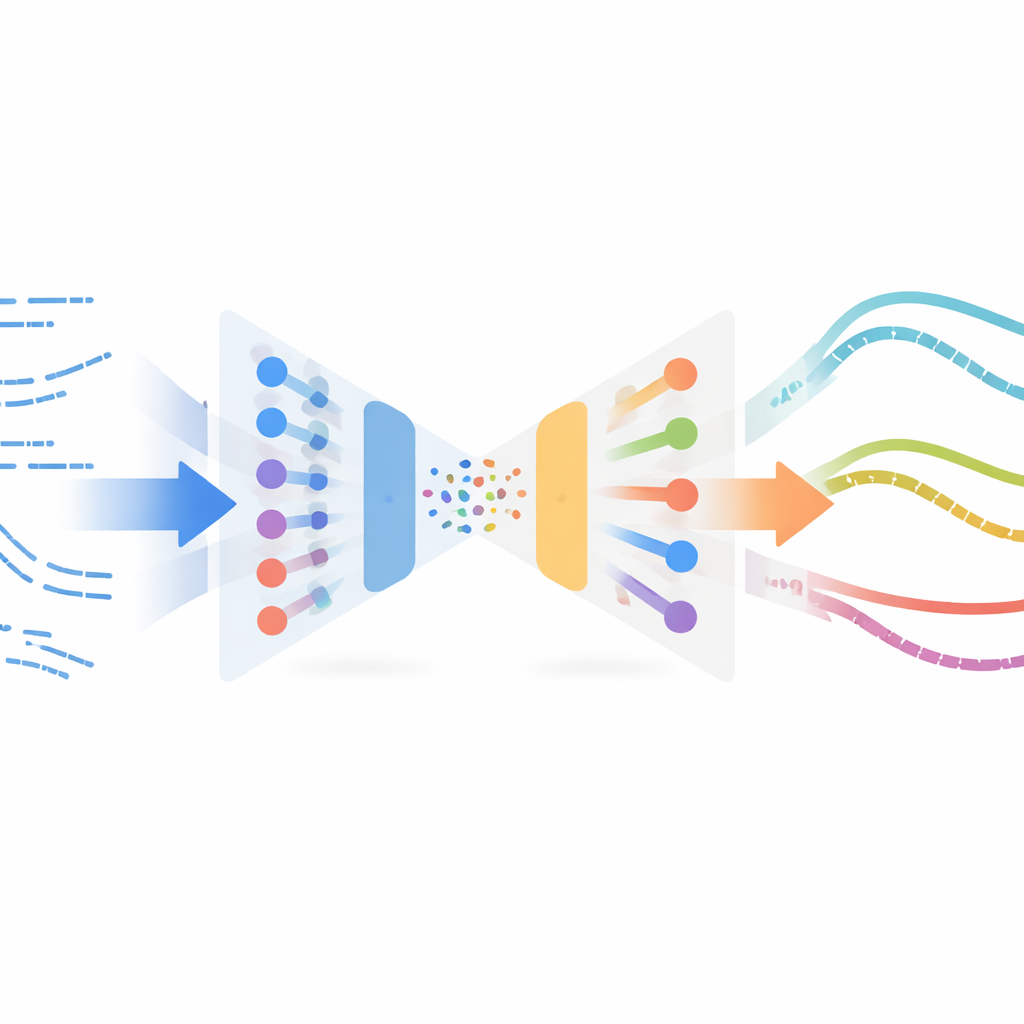
Autorzy adaptują zaskakującą koncepcję z przetwarzania obrazów nazwaną neuralnym transferem stylu. W aplikacjach graficznych transfer stylu bierze treść jednego obrazu (na przykład fotografii) i styl innego (na przykład obrazu malarskiego) i łączy je w nową grafikę. Tutaj zamiast obrazów „treścią” jest symulowane zachowanie robota podczas cięcia w czasie, a „stylem” to, jak rzeczywiste cięcie wygląda w danych czujnikowych. Metoda uczy się zwartej reprezentacji krótkich fragmentów ruchu przy użyciu wariacyjnego autoenkodera — rodzaju sieci neuronowej, która kompresuje i rekonstrukuje szereg czasowy. Sieć ta jest najpierw trenowana tylko na trajektoriach symulowanych, tak by mogła niezawodnie kodować i dekodować stany i akcje robota, bez potrzeby etykietowania czy nagród z eksperymentów rzeczywistych.
Mieszanie odczucia rzeczywistości z doświadczeniem symulacyjnym
Gdy enkoder zostanie wytrenowany, system przetwarza wszystkie dostępne przykłady rzeczywistego cięcia — zebrane off-policy, czyli niepochodzące od ostatecznego, dopracowanego sterownika — przez tę samą sieć. W tej wspólnej przestrzeni utajonej fragmenty symulowane i rzeczywiste, które „czują się” podobnie, znajdują się blisko siebie. Metoda następnie paruje fragmenty symulowane z pobliskimi rzeczywistymi za pomocą miary podobieństwa i przeprowadza optymalizację transferu stylu: delikatnie modyfikuje każdy fragment symulowany tak, aby zachował strukturę zadania (na przykład kiedy i jak robot przesuwa się w materiale), a jednocześnie przyjął statystyczne cechy rzeczywistych odczytów czujników. Te wystylizowane fragmenty tworzą zastępczy „rzeczywisty” zbiór danych, automatycznie oznakowany ekspertowymi akcjami ze symulacji, i są następnie używane do wytrenowania nowej polityki dla robota fizycznego poprzez uczenie przez naśladowanie.
Przetestowanie metody
Naukowcy przetestowali swoje podejście na robocie współpracującym wyposażonym w silnikową piłę szczelinową, tnąc różne materiały, w tym pianę, tekturę, plastik, mikę i aluminium. Robot musiał podążać ścieżkami po płaskich, źle wyrównanych i zakrzywionych powierzchniach, dostosowując prędkość posuwu, głębokość cięcia i sztywność w trakcie pracy. Nowa polityka oparta na transferze stylu została porównana z kilkoma alternatywami: użyciem eksperta wytrenowanego w symulacji bezpośrednio, wcześniejszą metodą dodającą ręcznie skonstruowany model korekcyjny oraz dwoma zaawansowanymi schematami translacji opartymi na deep learningu (warunkowy wariacyjny autoenkoder i CycleGAN). W badanych przypadkach polityka oparta na transferze stylu ciąła szybciej niż surowy ekspert z symulacji i metoda oparta na GAN, oraz osiągała porównywalne lub lepsze wyniki niż bardziej złożone alternatywy, przy zachowaniu stabilnego zachowania i gładszych ścieżek narzędzia.
Co to oznacza dla przyszłych robotów
Prościej mówiąc, badanie pokazuje, że roboty mogą „pożyczyć odczucie” doświadczenia ze świata rzeczywistego bez rozległego retreningu czy precyzyjnych modeli fizycznych. Poprzez łączenie umiejętności nabytych w symulacji ze stylem rzeczywistych danych czujnikowych robot uczy się strategii cięcia, która dobrze przenosi się na różne materiały i kształty, nawet gdy bezpośrednie informacje zwrotne w postaci nagrody z rzeczywistego świata są niedostępne. To ułatwia wdrażanie sterowania opartego na uczeniu przez wzmacnianie w wymagających, kontaktowych zadaniach, takich jak demontaż, recykling czy nawet chirurgia, gdzie eksperymentowanie na rzeczywistym systemie jest ograniczone, a błędy kosztowne.
Cytowanie: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Słowa kluczowe: transfer sim-to-real, robotyczne cięcie, uczenie przez wzmacnianie, neuralny transfer stylu, adaptacja domeny