Clear Sky Science · ar
نقل سياسات التعلم التعزيزي من المحاكاة إلى العالم الحقيقي اعتمادًا على التشيؤ العصبي: مثال نهائي مع تطبيق على القطع الروبوتي
تعليم الروبوتات كيفية القطع في العالم الحقيقي
تتحسن الروبوتات في تعلم المهام المعقدة داخل المحاكاة الحاسوبية، لكنها غالبًا ما تواجه صعوبات عند الانتقال إلى العالم الحقيقي، حيث تجعل الاحتكاك والتآكل والمواد غير المنتظمة كل شيء أقل قابلية للتنبؤ. تستكشف هذه الورقة طريقة جديدة لسد تلك الفجوة بحيث يظل الروبوت الذي تعلم قطع المواد بأمان وكفاءة في المحاكاة قادرًا على الأداء نفسه على مواد حقيقية ومجهولة، دون الحاجة إلى كميات هائلة من بيانات تدريب حقيقية جديدة.
لماذا الانتقال من الشاشة إلى الورشة صعب
يتيح التعلم التعزيزي للروبوت اكتشاف استراتيجيات جيدة بالتجربة والخطأ، لكن التجارب الواقعية قد تكون بطيئة وخطرة ومكلفة. لذلك يقوم المهندسون غالبًا بالتدريب في المحاكاة، حيث تكون ملايين المحاولات رخيصة وآمنة. المشكلة أن عمليات القطع في المحاكاة دائمًا أنظف من الواقع. في المختبر، قد يهتز أداة الروبوت، وتوجد مساحات خلوية في المحركات، وتختلف المواد، وتنحرف المستشعرات. تخلق هذه الاختلافات "فجوة نطاق": سياسة تبدو رائعة في المحاكاة قد تؤدي أداءً ضعيفًا أو حتى خطيرًا على العتاد الحقيقي. الحلول الحالية إما تعتمد على نماذج فيزيائية مفصلة — والتي قد تكون خاطئة — أو على آلات تعلم عميق ضخمة يجب إعادة تدريبها في كل مرة يتغير فيها العتاد أو المستشعرات أو المواد.
اقتباس فكرة من الفن الرقمي
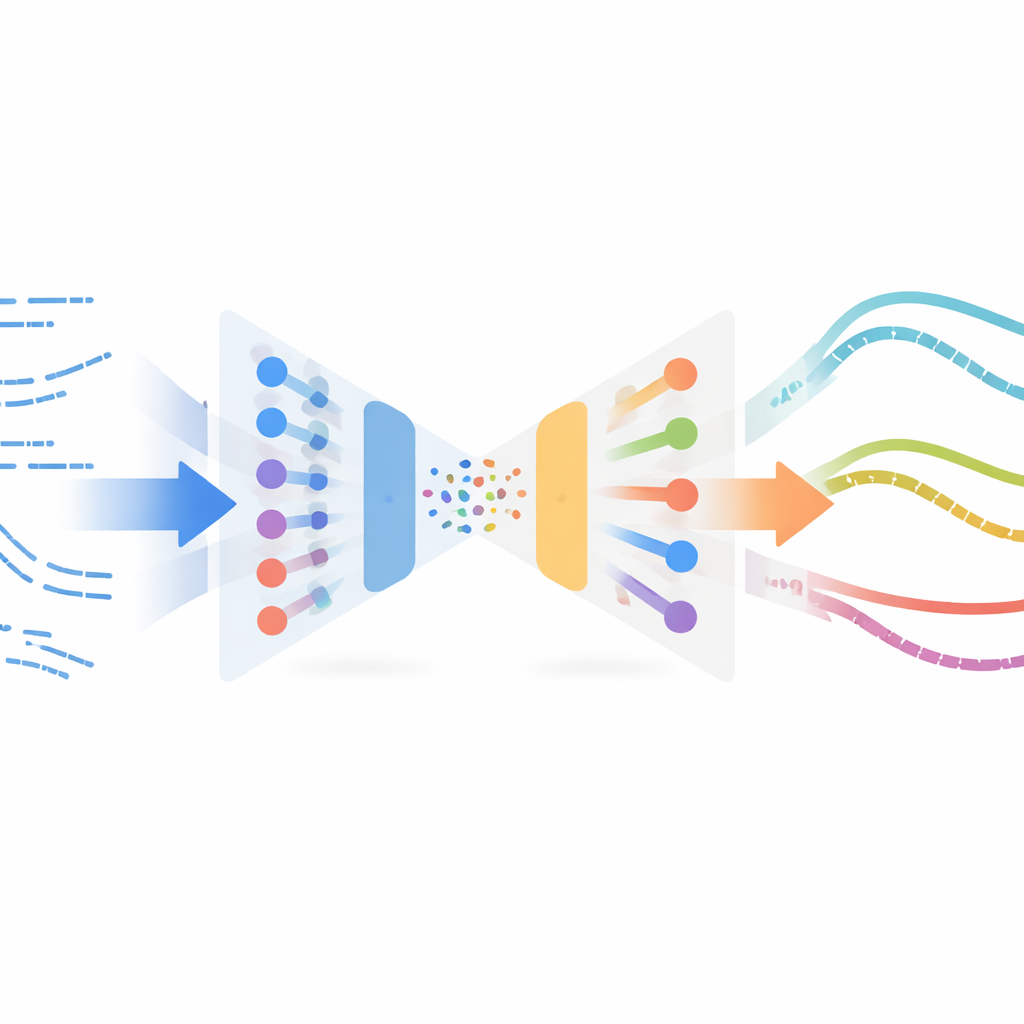
يتبنى المؤلفون فكرة مفاجئة من معالجة الصور تُسمى نقل النمط العصبي. في تطبيقات الصور، يأخذ نقل النمط محتوى صورة (مثل صورة فوتوغرافية) ونمط صورة أخرى (مثل لوحة فنية) ويخلط بينهما لإنشاء صورة جديدة. هنا، بدل الصور، يكون "المحتوى" هو سلوك القطع المحاكى على مدار الزمن، و"النمط" هو كيف يبدو القطع الحقيقي في بيانات المستشعرات. تتعلم الطريقة تمثيلاً مدمجًا لمقاطع حركة قصيرة باستخدام مشفر تلقائي تبايني، وهو نوع من الشبكات العصبية التي تضغط وتعيد بناء السلاسل الزمنية. يتم تدريب هذه الشبكة أولًا على المسارات المحاكاة فقط حتى تتمكن من ترميز وفك ترميز حالات وإجراءات الروبوت بشكل موثوق، دون الحاجة إلى أي تسميات أو مكافآت من التجارب الحقيقية.
خلط إحساس العالم الحقيقي في خبرة المحاكاة
بمجرد تدريب هذا المشفر، تغذي النظام بكل أمثلة القطع الحقيقية المتاحة — المجمعة خارج سياسة التشغيل الحالية، مما يعني أنها ليست مأخوذة من متحكم نهائي مصقول — عبر نفس الشبكة. في فضاء الكمون المشترك هذا، تقترَب المقاطع المحاكية والحقيقية التي "تشعر" بشكل مشابه إلى بعضها البعض. ثم تقترن الطريقة مقاطع المحاكاة بمقاطع حقيقية مجاورة باستخدام مقياس التشابه وتنفذ تحسين نقل النمط: تُعدِّل كل مقطع محاكاة برفق بحيث يحتفظ ببنية المهمة (على سبيل المثال، متى وكيف يتقدم الروبوت في المادة) مع اكتساب بصمات إحصائية لقراءات المستشعر الحقيقية. تشكل هذه المقاطع المعدلة مجموعة بيانات مُحاكاة لـ"الحقيقي"، مُعلَّمة تلقائيًا بإجراءات الخبير من المحاكاة، ثم تُستخدم لتدريب سياسة جديدة للروبوت الفيزيائي عبر التعلم بالتقليد.
اختبار المنهجية
اختبر الباحثون منهجيتهم على روبوت تعاوني مزود بمنشار شق محركي، وقاموا بقطع مجموعة متنوعة من المواد بما في ذلك الرغوة والورق المقوى والبلاستيك والمِيكا والألمنيوم. كان على الروبوت اتباع مسارات على أسطح مسطحة وغير مُحاذاة ومنحنية، مع تعديل معدل التغذية وعمق القطع والصلابة أثناء الحركة. قورنت السياسة المبنية على نقل النمط بعدة بدائل: استخدام الخبير المدرب في المحاكاة مباشرة، طريقة سابقة أضافت نموذج تصحيحي مصمم يدويًا، واثنتان من مخططات الترجمة العميقة المتقدمة (مشفر تلقائي تبايني شرطي وCycleGAN). عبر دراسات الحالة، قطعت سياسة نقل النمط أسرع من خبير المحاكاة الخام ومن الطريقة المبنية على GAN، وحققت أداءً مشابهًا أو أفضل من البدائل الأكثر تعقيدًا، مع الحفاظ على سلوك مستقر ومسارات أداة أكثر سلاسة.
ما يعنيه هذا للروبوتات المستقبلية
بعبارة بسيطة، تُظهر الدراسة أن الروبوتات يمكنها "اقتراض الإحساس" من الخبرة الحقيقية دون إعادة تدريب واسعة أو نماذج فيزيائية دقيقة. عبر مزج المهارة المحاكية مع نمط بيانات المستشعرات الحقيقية، يتعلم الروبوت استراتيجية قطع تنتقل جيدًا إلى مواد وأشكال مختلفة، حتى عندما لا يتوفر تغذية مرتدة بالمكافأة من العالم الحقيقي مباشرة. هذا يجعل من العملي أكثر نشر ضوابط معتمدة على التعلم التعزيزي في المهام المتطلبة والتي تتضمن تلامسًا كثيفًا مثل الفك، وإعادة التدوير، أو حتى الجراحة، حيث يكون التجريب على النظام الحقيقي محدودًا والأخطاء مكلفة.
الاستشهاد: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
الكلمات المفتاحية: الانتقال من المحاكاة إلى الواقع, القطع الروبوتي, التعلم التعزيزي, نقل النمط العصبي, تكييف النطاق