Clear Sky Science · fr
Transfert de politique RL sim-vers-réel basé sur des exemples de bout en bout via la stylisation neuronale avec application à la découpe robotique
Apprendre aux robots à découper dans le monde réel
Les robots s’améliorent pour apprendre des tâches complexes dans des simulations informatiques, mais ils peinent souvent lorsqu’on les transpose dans le monde réel, où le frottement, l’usure et les matériaux désordonnés rendent tout moins prévisible. Cet article explore une nouvelle façon de combler cet écart pour qu’un robot ayant appris à découper des matériaux de manière sûre et efficace en simulation puisse continuer à le faire sur des matériaux réels inconnus, sans nécessiter des quantités massives de nouvelles données d’entraînement réelles.
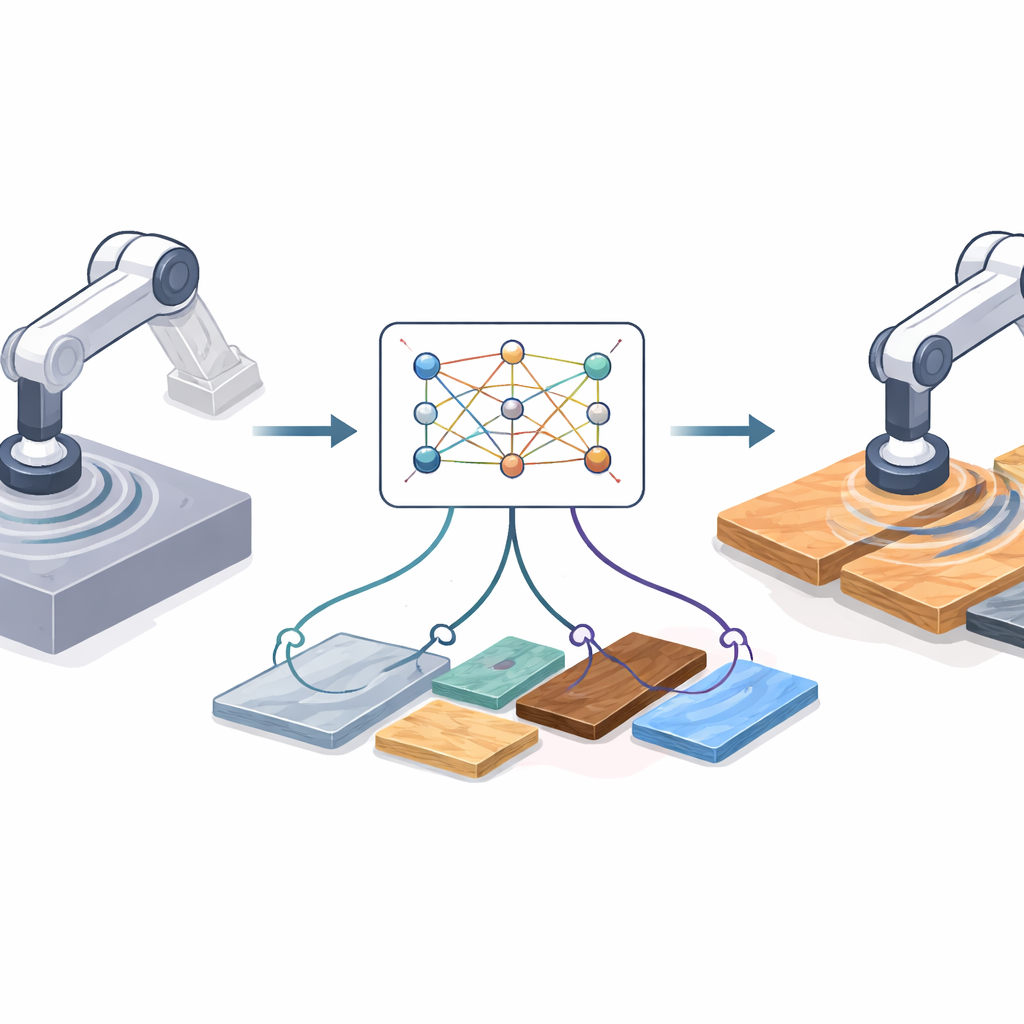
Pourquoi passer de l’écran à l’atelier est difficile
L’apprentissage par renforcement permet à un robot de découvrir de bonnes stratégies par essais et erreurs, mais les essais réels peuvent être lents, risqués et coûteux. Les ingénieurs préfèrent souvent entraîner en simulation, où des millions d’essais sont bon marché et sans danger. Le problème est que la découpe simulée est toujours plus propre que la réalité. En laboratoire, l’outil du robot peut vibrer, les moteurs ont du jeu, les matériaux varient et les capteurs dérivent. Ces différences créent un « écart de domaine » : une politique qui semble brillante en simulation peut mal fonctionner voire être dangereuse sur du matériel réel. Les solutions existantes reposent soit sur des modèles physiques détaillés — qui peuvent être erronés — soit sur des architectures d’apprentissage profond lourdes qu’il faut réentraîner chaque fois que le matériel, les capteurs ou les matériaux changent.
Emprunter une idée à l’art numérique
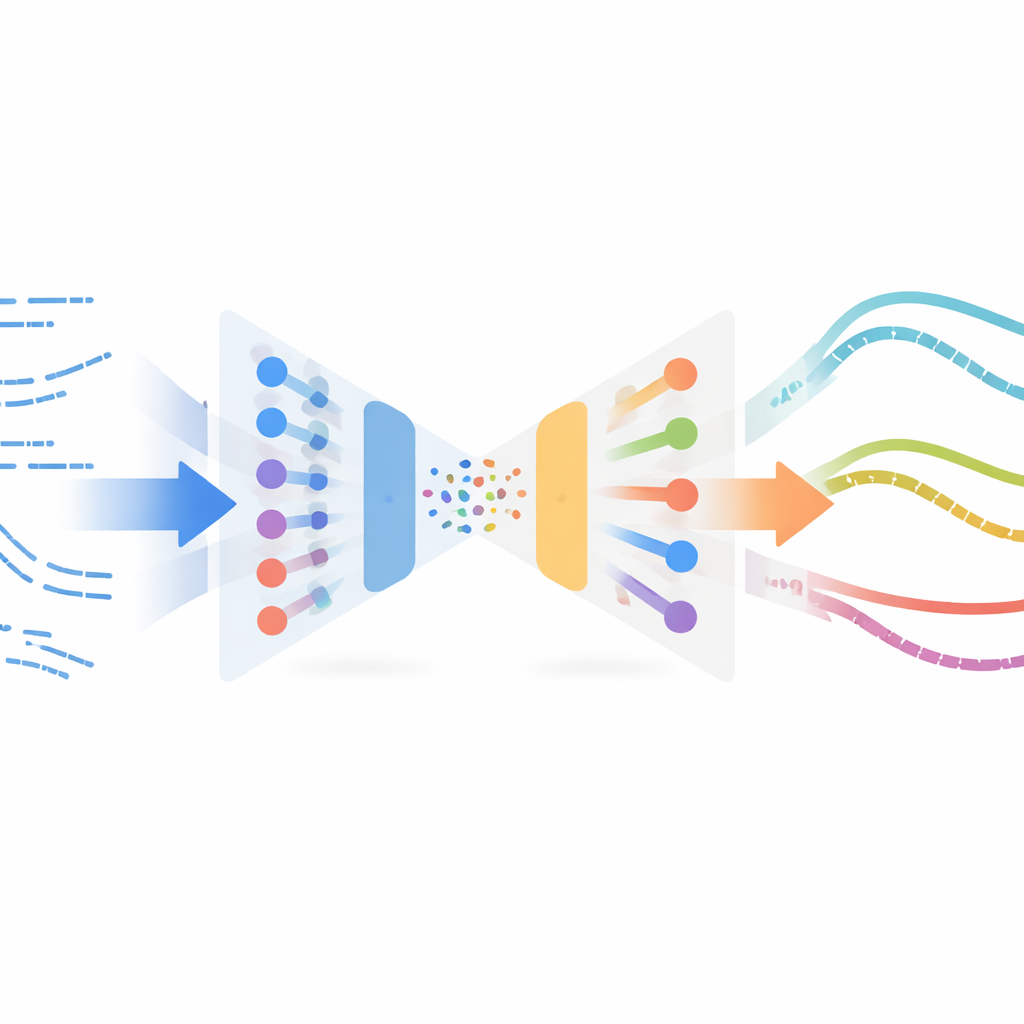
Les auteurs adaptent un concept surprenant issu du traitement d’images, appelé transfert de style neuronal. Dans les applications d’images, le transfert de style prend le contenu d’une image (par exemple une photo) et le style d’une autre (par exemple une peinture) pour les fusionner en une nouvelle image. Ici, au lieu d’images, le « contenu » est le comportement de découpe simulé du robot au fil du temps, et le « style » est l’apparence de la découpe réelle dans les données capteurs. La méthode apprend une représentation compacte de courts extraits de mouvement à l’aide d’un autoencodeur variationnel, un type de réseau neuronal qui compresse et reconstruit des séries temporelles. Ce réseau est d’abord entraîné uniquement sur des trajectoires simulées afin qu’il puisse encoder et décoder les états et actions du robot de façon fiable, sans avoir besoin d’étiquettes ou de récompenses issues d’expériences réelles.
Mélanger la sensation réelle à l’expérience simulée
Une fois cet encodeur entraîné, le système fait passer tous les exemples réels de découpe disponibles — collectés hors politique, c’est‑à‑dire pas à partir d’un contrôleur final et poli — dans le même réseau. Dans cet espace latent partagé, les extraits simulés et réels qui « se ressentent » comme similaires se retrouvent proches. La méthode apparie alors des extraits simulés avec des extraits réels voisins à l’aide d’une mesure de similarité et effectue une optimisation de transfert de style : elle modifie légèrement chaque extrait simulé de sorte qu’il conserve sa structure de tâche (par exemple quand et comment le robot avance dans le matériau) tout en adoptant les empreintes statistiques des lectures capteurs réelles. Ces extraits stylisés forment un jeu de données de substitution « réel », automatiquement étiqueté avec les actions expertes issues de la simulation, et sont ensuite utilisés pour entraîner une nouvelle politique pour le robot physique via l’apprentissage par imitation.
Mettre la méthode à l’épreuve
Les chercheurs ont testé leur approche sur un robot collaboratif équipé d’une scie circulaire motorisée, découpant une variété de matériaux incluant mousse, carton, plastique, mica et aluminium. Le robot devait suivre des trajectoires sur des surfaces plates, mal alignées et courbes, en ajustant la vitesse d’avance, la profondeur de coupe et la rigidité au fil du geste. La nouvelle politique basée sur le transfert de style a été comparée à plusieurs alternatives : utiliser directement l’expert entraîné en simulation, une méthode précédente ajoutant un modèle correctif conçu manuellement, et deux schémas avancés de traduction par apprentissage profond (un autoencodeur variationnel conditionnel et un CycleGAN). Sur les cas d’étude, la politique par transfert de style a découpé plus vite que l’expert simulé brut et la méthode basée sur le GAN, et a obtenu des performances similaires ou meilleures que les alternatives plus complexes, tout en maintenant un comportement stable et des trajectoires d’outil plus lisses.
Ce que cela signifie pour les robots de demain
En termes simples, l’étude montre que les robots peuvent « emprunter la sensation » de l’expérience réelle sans un réentraînement étendu ni des modèles physiques précis. En mélangeant l’expérience simulée avec le style des données capteurs réelles, le robot apprend une stratégie de découpe qui se transfère bien à différents matériaux et formes, même lorsque les retours de récompense directs du monde réel sont indisponibles. Cela rend plus pratique le déploiement du contrôle basé sur l’apprentissage par renforcement pour des tâches exigeantes et en contact, comme le démontage, le recyclage ou même la chirurgie, où expérimenter sur le système réel est limité et les erreurs coûtent cher.
Citation: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Mots-clés: transfert sim-vers-réel, découpe robotique, apprentissage par renforcement, transfert de style neuronal, adaptation de domaine