Clear Sky Science · ru
Конечный пример переноса RL-политики «сим в реальность» на основе нейронной стилизации с применением к роботизированной резке
Обучение роботов резать в реальном мире
Роботы становятся лучше в освоении сложных задач в компьютерных симуляциях, но при переносе в реальный мир они часто испытывают трудности: трение, износ и неаккуратные материалы делают поведение менее предсказуемым. В этой статье исследуется новый способ преодоления этого разрыва, который позволяет роботу, обученному безопасно и эффективно резать материалы в симуляции, сохранять хорошие результаты на реальных, неизвестных материалах без большого количества новых реальных данных для обучения.
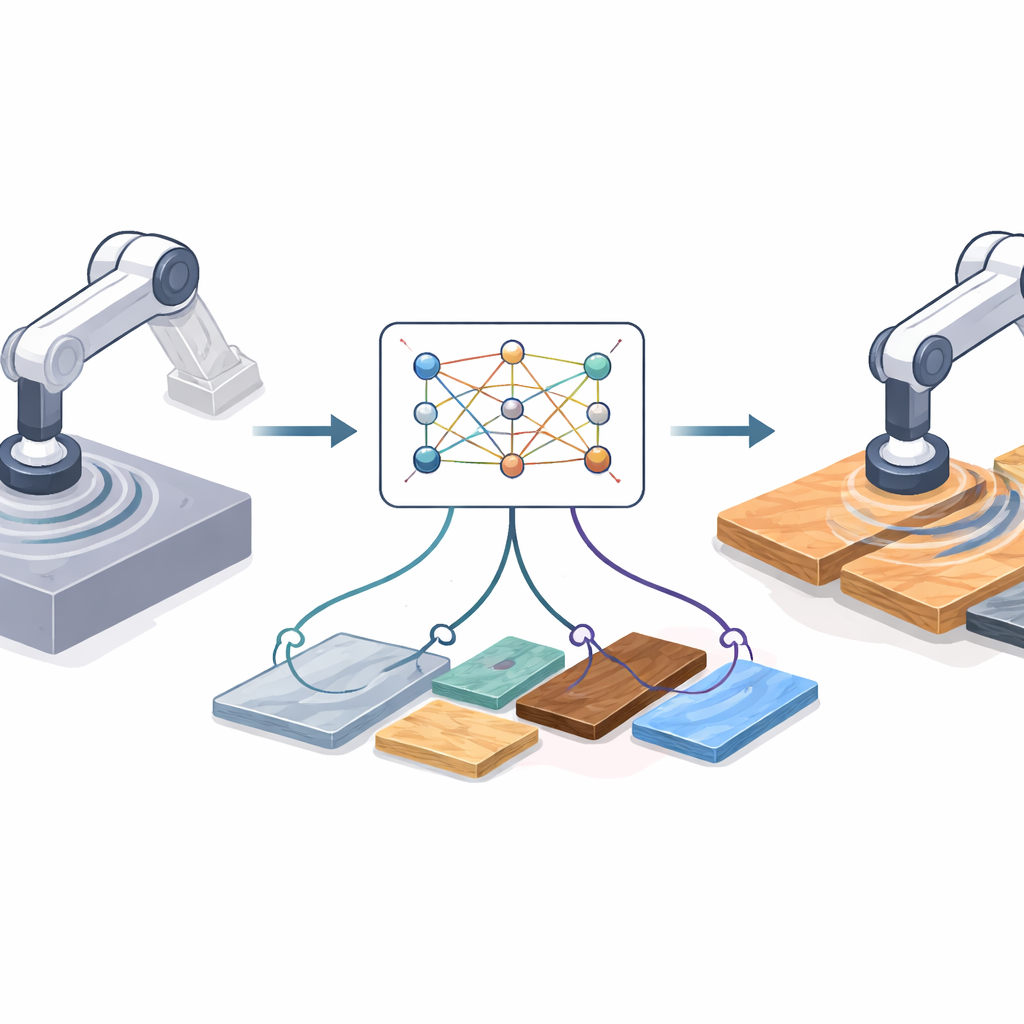
Почему переход от экрана к мастерской сложен
Обучение с подкреплением позволяет роботу находить эффективные стратегии методом проб и ошибок, но реальные испытания могут быть медленными, рискованными и дорогими. Поэтому инженеры часто тренируют робота в симуляции, где миллионы прогонов дешевы и безопасны. Проблема в том, что моделирование резки всегда чище, чем реальность. В лаборатории инструмент может вибрировать, в моторах есть люфт, материалы отличаются, а датчики дрейфуют. Эти различия создают «рамочный разрыв» (domain gap): политика, которая выглядит блестяще в симуляции, может работать плохо или даже опасно на реальном оборудовании. Существующие решения либо опираются на подробные физические модели — которые могут быть неточными, — либо на тяжёлые глубокие методы, которые нужно переобучать при изменении аппаратуры, датчиков или материалов.
Заимствуя идею из цифрового искусства
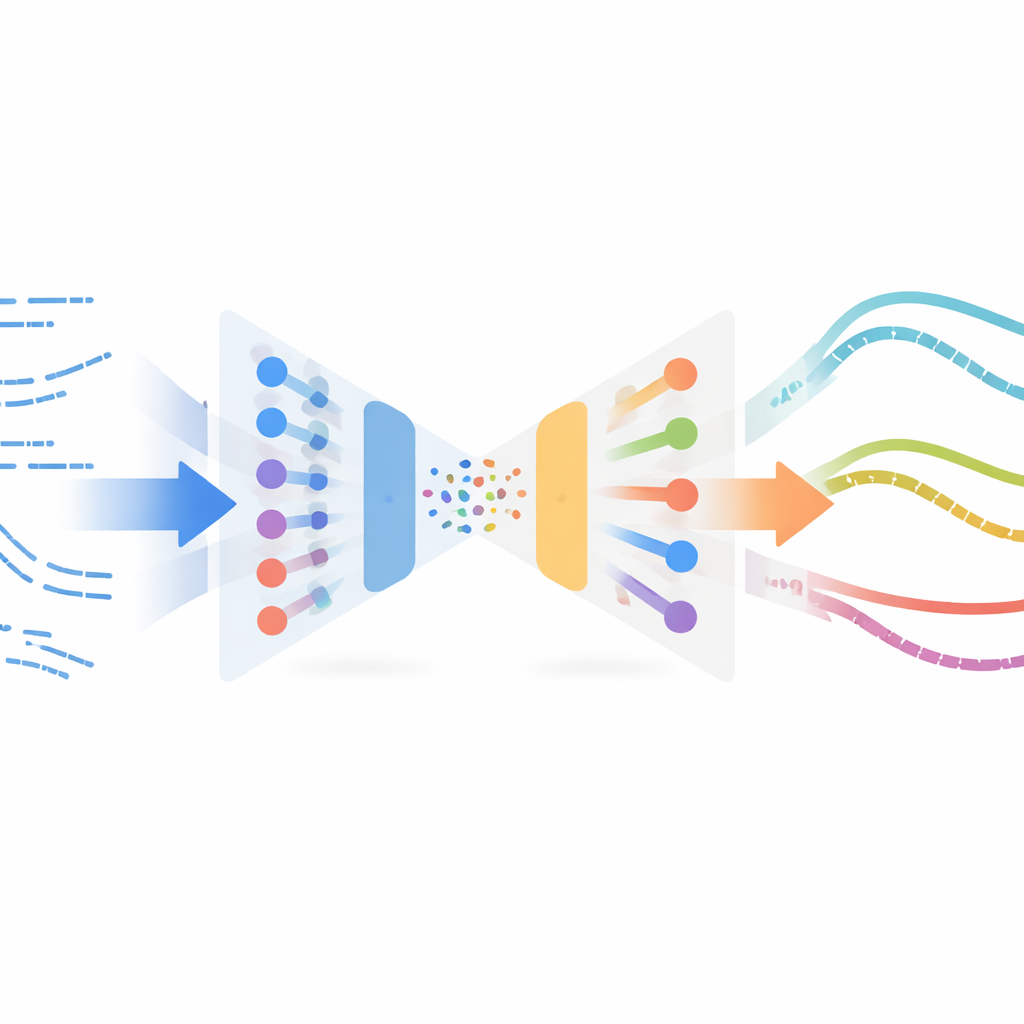
Авторы адаптируют неожиданную концепцию из обработки изображений, называемую нейронной передачей стиля. В приложениях для изображений перенос стиля берет содержание одной картинки (например, фотографию) и стиль другой (например, картину) и смешивает их в новое изображение. Здесь вместо картинок «содержанием» является поведение робота при резке во времени, а «стилем» — то, как резка выглядит в данных датчиков на реальном оборудовании. Метод обучает компактное представление коротких фрагментов движения с помощью вариационного автоэнкодера — типа нейросети, которая сжимает и восстанавливает временные ряды. Эта сеть сначала обучается только на симулированных траекториях, чтобы надежно кодировать и декодировать состояния и действия робота, без необходимости меток или вознаграждений из реальных экспериментов.
Придание симулированному опыту реалистичного звучания
Когда кодировщик обучен, система прогоняет через него все доступные реальные примеры резки — собранные офф-полиси, то есть не с использованием окончательного отточенного контроллера. В этом общем латентном пространстве симулированные и реальные фрагменты, которые «ощущаются» похожими, оказываются близко друг к другу. Метод затем подбирает пары симулированных и ближайших реальных фрагментов по мере подобия и выполняет оптимизацию передачи стиля: аккуратно изменяет каждый симулированный фрагмент так, чтобы он сохранял структуру задачи (например, когда и как робот входит в материал), но принимал на себя статистические отпечатки реальных показаний датчиков. Эти стилизованные фрагменты формируют суррогатный «реальный» набор данных, автоматически промаркированный экспертными действиями из симуляции, и затем используются для обучения новой политики для физического робота методом имитационного обучения.
Проверка метода на практике
Исследователи протестировали подход на коллаборативном роботе с моторизованной дисковой пилой, который резал разные материалы: пену, картон, пластик, слюду и алюминий. Роботу приходилось следовать траекториям по плоским, смещённым и изогнутым поверхностям, регулируя подачу, глубину реза и жёсткость по ходу выполнения. Новая политика на основе передачи стиля сравнивалась с несколькими альтернативами: прямым применением эксперта, обученного в симуляции; предыдущим методом с вручную созданной корректирующей моделью; и двумя продвинутыми схемами глубокого перевода (условный вариационный автоэнкодер и CycleGAN). По результатам кейсов политика с передачей стиля резала быстрее, чем исходный симуляционный эксперт и метод на основе GAN, и демонстрировала сопоставимую или лучшую производительность по сравнению с более сложными альтернативами, сохраняя при этом стабильное поведение и более плавные траектории инструмента.
Что это значит для будущих роботов
Проще говоря, исследование показывает, что роботы могут «заимствовать ощущение» реального опыта без длительного переобучения или точных физических моделей. Смешивая симулированные навыки со стилем реальных сигналов датчиков, робот усваивает стратегию резки, которая хорошо переносится на разные материалы и формы, даже когда прямые сигналы вознаграждения из реального мира недоступны. Это делает более практичным применение управления на основе обучения с подкреплением в требовательных задачах с контактами, таких как разборка, переработка или даже хирургия, где эксперименты на реальной системе ограничены, а ошибки дороги.
Цитирование: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Ключевые слова: перенос из симуляции в реальность, роботизированная резка, обучение с подкреплением, нейронная передача стиля, адаптация домена