Clear Sky Science · de
End-to-end beispielbasierter Sim-to-Real RL-Policy-Transfer basierend auf neuronaler Stilisierung mit Anwendung auf robotisches Schneiden
Robotern beibringen, in der realen Welt zu schneiden
Roboter werden immer besser darin, komplexe Aufgaben in Computersimulationen zu erlernen, doch beim Transfer in die reale Welt haben sie oft Probleme: Reibung, Verschleiß und unordentliche Materialien machen alles unvorhersehbarer. Dieses Paper untersucht einen neuen Weg, diese Lücke zu überbrücken, sodass ein Roboter, der in der Simulation sicher und effizient schneiden lernt, dies auch an echten, unbekannten Materialien tun kann, ohne große Mengen neuer Realwelt-Trainingsdaten zu benötigen.
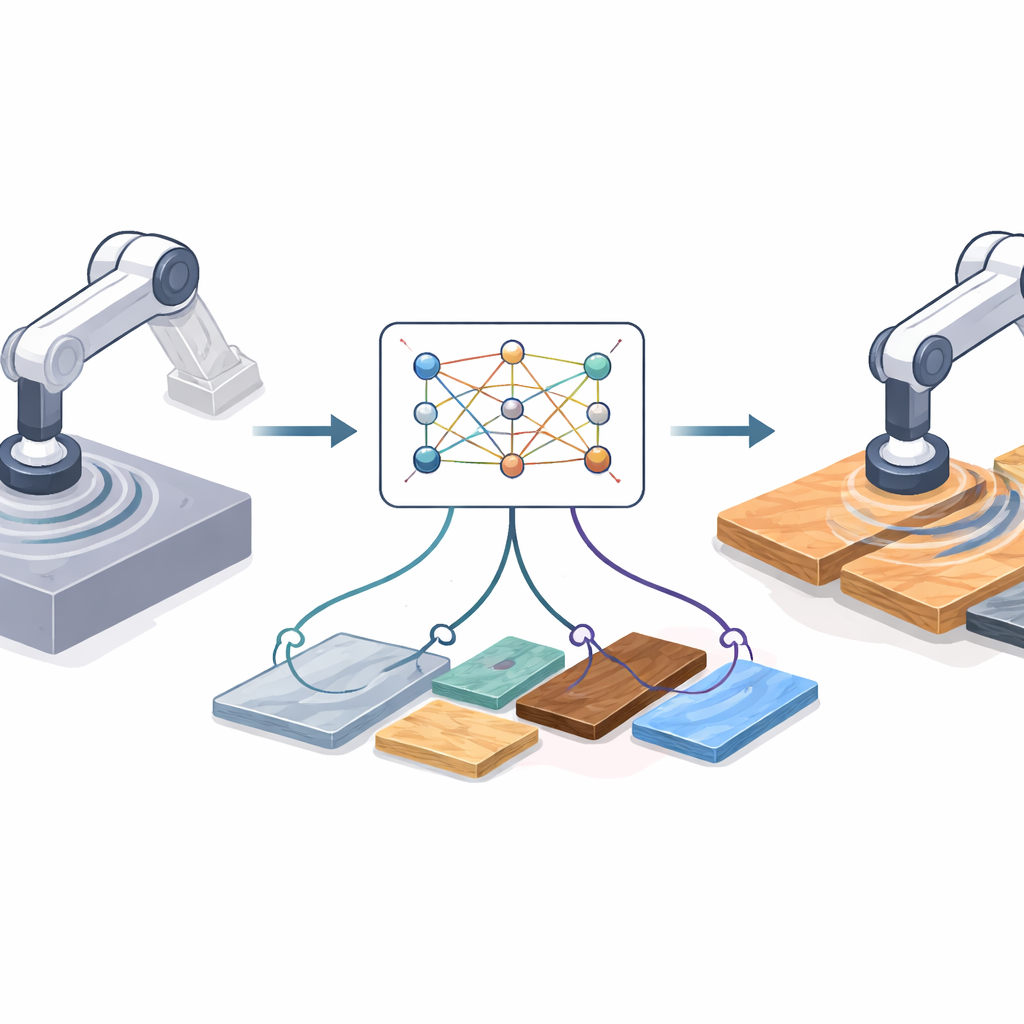
Warum der Wechsel vom Bildschirm in die Werkstatt schwerfällt
Verstärkungslernen erlaubt es einem Roboter, durch Ausprobieren gute Strategien zu entdecken, doch reale Versuche sind langsam, riskant und teuer. Deshalb trainieren Ingenieure oft in Simulation, wo Millionen von Übungsdurchläufen günstig und sicher sind. Der Haken ist, dass simuliertes Schneiden immer sauberer ist als die Realität. Im Labor kann das Werkzeug vibrieren, Motoren haben Spiel, Materialien variieren und Sensoren driften. Diese Unterschiede erzeugen eine „Domänenlücke“: Eine Policy, die in der Simulation glänzt, kann auf echter Hardware schlecht oder sogar gefährlich reagieren. Bestehende Lösungen stützen sich entweder auf detaillierte physikalische Modelle – die fehlerhaft sein können – oder auf schwere Deep‑Learning‑Systeme, die bei jeder Änderung an Hardware, Sensoren oder Materialien neu trainiert werden müssen.
Eine Idee aus der digitalen Kunst ausleihen
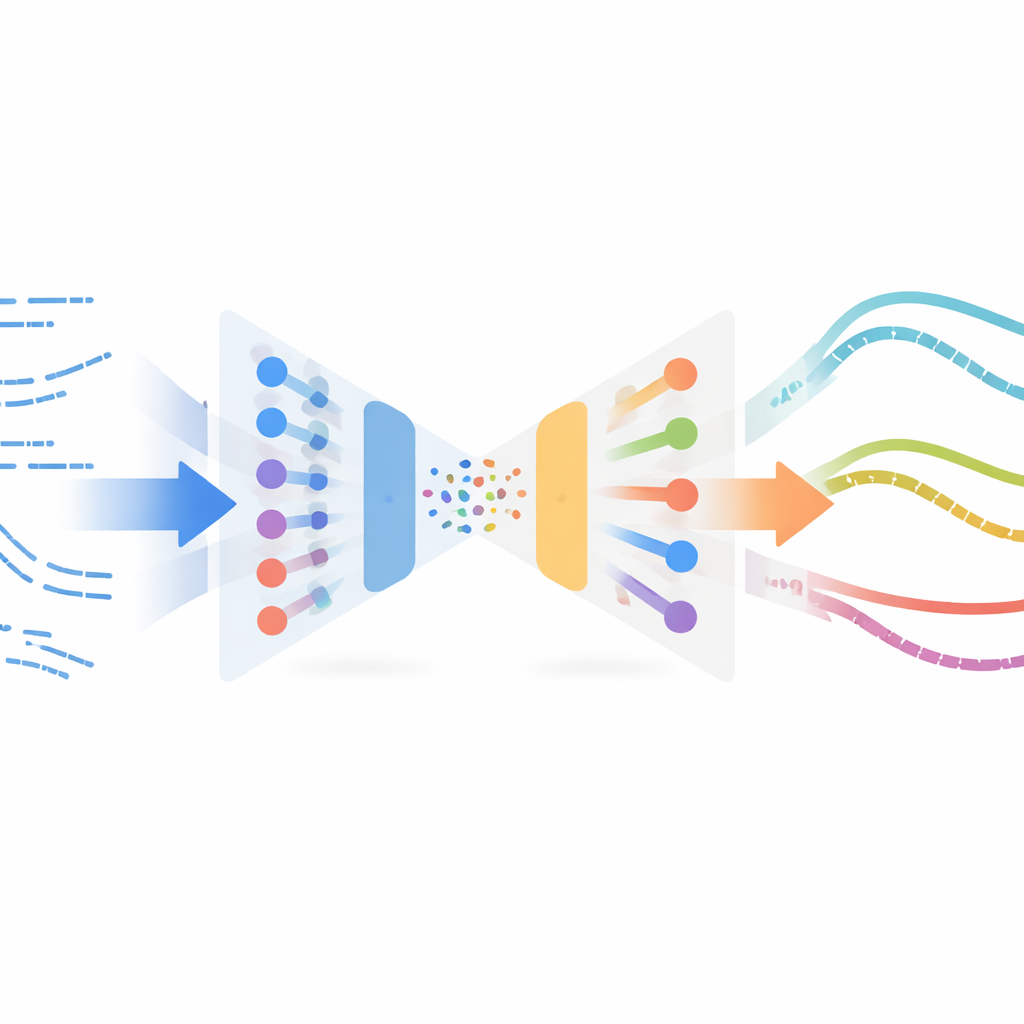
Die Autorinnen und Autoren adaptieren ein überraschendes Konzept aus der Bildverarbeitung: die neuronale Stilübertragung. In Bild‑Apps nimmt die Stilübertragung den Inhalt eines Bildes (etwa ein Foto) und den Stil eines anderen (etwa ein Gemälde) und mischt sie zu einem neuen Bild. Hier sind statt Bildern die „Inhalte“ das zeitliche Schneideverhalten des Roboters, und der „Stil“ ist, wie echtes Schneiden in Sensordaten aussieht. Die Methode lernt eine kompakte Repräsentation kurzer Bewegungsabschnitte mithilfe eines Variational Autoencoder, eines neuronalen Netzes, das Zeitreihen komprimiert und rekonstruiert. Dieses Netzwerk wird zunächst ausschließlich mit simulierten Trajektorien trainiert, sodass es Roboterzustände und -aktionen zuverlässig kodieren und dekodieren kann, ohne Labels oder Belohnungen aus realen Experimenten zu benötigen.
Realitätsgefühl in simulierte Erfahrung einmischen
Sobald dieser Encoder trainiert ist, werden alle verfügbaren Realwelt‑Schneidebeispiele – off‑policy gesammelt, also nicht von einem finalen, ausgereiften Regler stammend – durch dasselbe Netzwerk geleitet. Im gemeinsamen latenten Raum liegen simulierte und reale Ausschnitte, die sich „ähnlich anfühlen“, dicht beieinander. Die Methode paaren simulierte Ausschnitte mit nahegelegenen realen mittels einer Ähnlichkeitsmessung und führt eine Stiltransfer‑Optimierung durch: Jeder simulierte Ausschnitt wird behutsam so angepasst, dass seine Aufgabenstruktur (zum Beispiel wann und wie der Roboter ins Material eindringt) erhalten bleibt, während er die statistischen Kennzeichen realer Sensordaten annimmt. Diese stilisierten Ausschnitte bilden ein surrogates „reales“ Datenset, automatisch mit den Expertenaktionen aus der Simulation etikettiert, und werden anschließend verwendet, um eine neue Policy für den physischen Roboter mittels Imitationslernen zu trainieren.
Die Methode auf die Probe gestellt
Die Forschenden testeten ihren Ansatz an einem kollaborativen Roboter mit motorisiertem Trennsägeblatt und schnitten verschiedenste Materialien wie Schaumstoff, Karton, Kunststoff, Glimmer und Aluminium. Der Roboter musste Bahnen über flache, versetzte und gekrümmte Oberflächen folgen und dabei Vorschubrate, Schnitttiefe und Steifigkeit anpassen. Die neue, auf Stilübertragung basierende Policy wurde mit mehreren Alternativen verglichen: dem direkt aus der Simulation stammenden Experten, einer früheren Methode mit einem handgefertigten Korrekturmodell und zwei fortgeschrittenen Deep‑Learning‑Übersetzungsschemata (einem konditionalen Variational Autoencoder und einem CycleGAN). In den Fallstudien schnitt die Stiltransfer‑Policy schneller als der rohe Simulations‑Experte und die GAN‑basierte Methode und erzielte eine ähnliche oder bessere Leistung als die komplexeren Alternativen, dabei mit stabilerem Verhalten und sanfteren Werkzeugpfaden.
Was das für zukünftige Roboter bedeutet
Kurz gesagt zeigt die Studie, dass Roboter das „Gefühl“ realer Erfahrung übernehmen können, ohne umfangreiches Nachtrainieren oder präzise physikalische Modelle. Indem simulierte Fertigkeit mit dem Stil realer Sensordaten vermischt wird, lernt der Roboter eine Schneidstrategie, die gut auf verschiedene Materialien und Formen übertragbar ist, sogar wenn direktes Belohnungsfeedback aus der realen Welt fehlt. Das macht den Einsatz von verstärkungslernenden Steuerungen in anspruchsvollen, kontaktintensiven Aufgaben wie Demontage, Recycling oder sogar Chirurgie praktischer, wo Experimente am realen System begrenzt sind und Fehler teuer sind.
Zitation: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Schlüsselwörter: sim-to-real-Transfer, robotisches Schneiden, Verstärkungslernen, neuronale Stilübertragung, Domänenanpassung