Clear Sky Science · en
End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting
Teaching Robots to Cut in the Real World
Robots are getting better at learning complex tasks in computer simulations, but they often struggle when moved into the real world, where friction, wear, and messy materials make everything less predictable. This paper explores a new way to bridge that gap so a robot that learns to cut materials safely and efficiently in simulation can keep doing so on real, unknown materials, without needing huge amounts of new real-world training data.
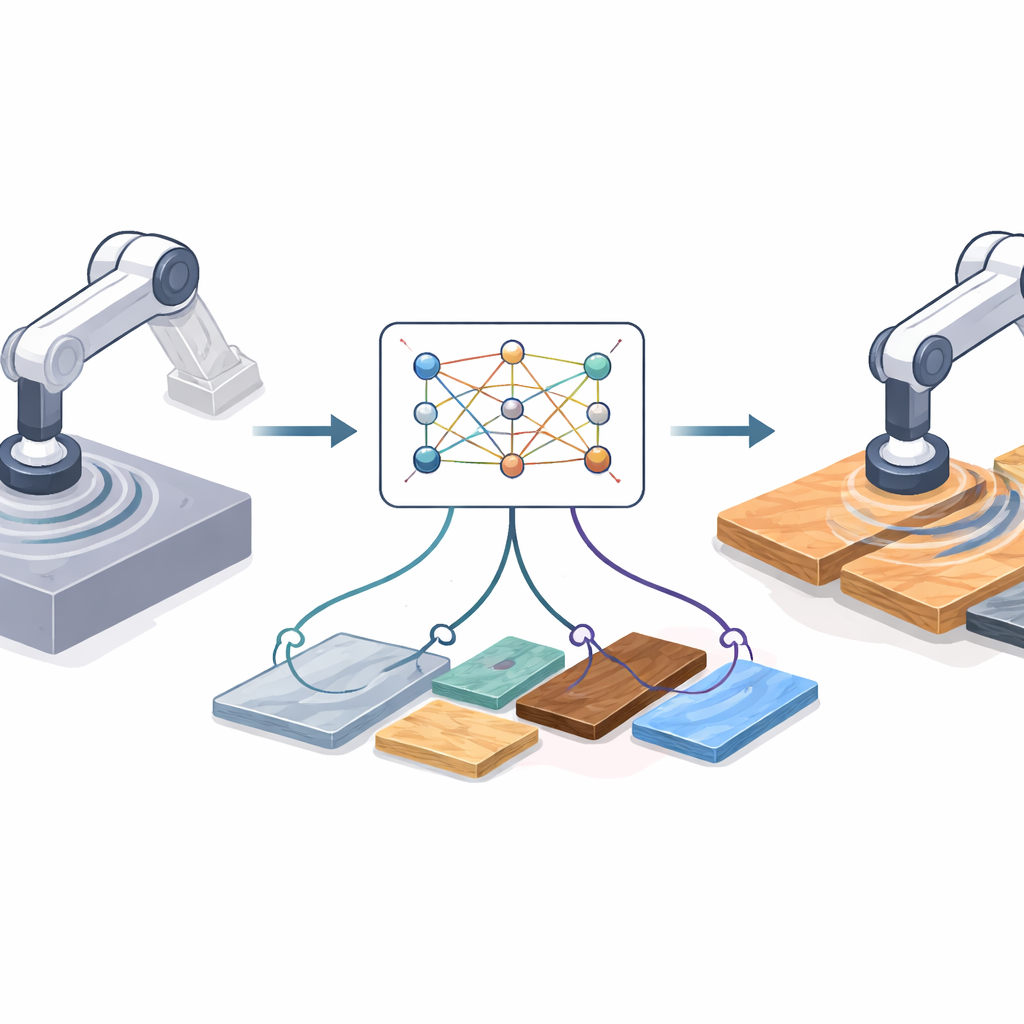
Why Moving from Screen to Workshop Is Hard
Reinforcement learning lets a robot discover good strategies by trial and error, but real-world trials can be slow, risky, and expensive. Instead, engineers often train in simulation, where millions of practice runs are cheap and safe. The catch is that simulated cutting is always cleaner than reality. In the lab, the robot’s tool can chatter, motors have slack, materials vary, and sensors drift. These differences create a “domain gap”: a policy that looks brilliant in simulation can perform poorly or even dangerously on real hardware. Existing fixes either rely on detailed physical models—which may be wrong—or on heavy deep-learning machinery that must be retrained every time the hardware, sensors, or materials change.
Borrowing an Idea from Digital Art
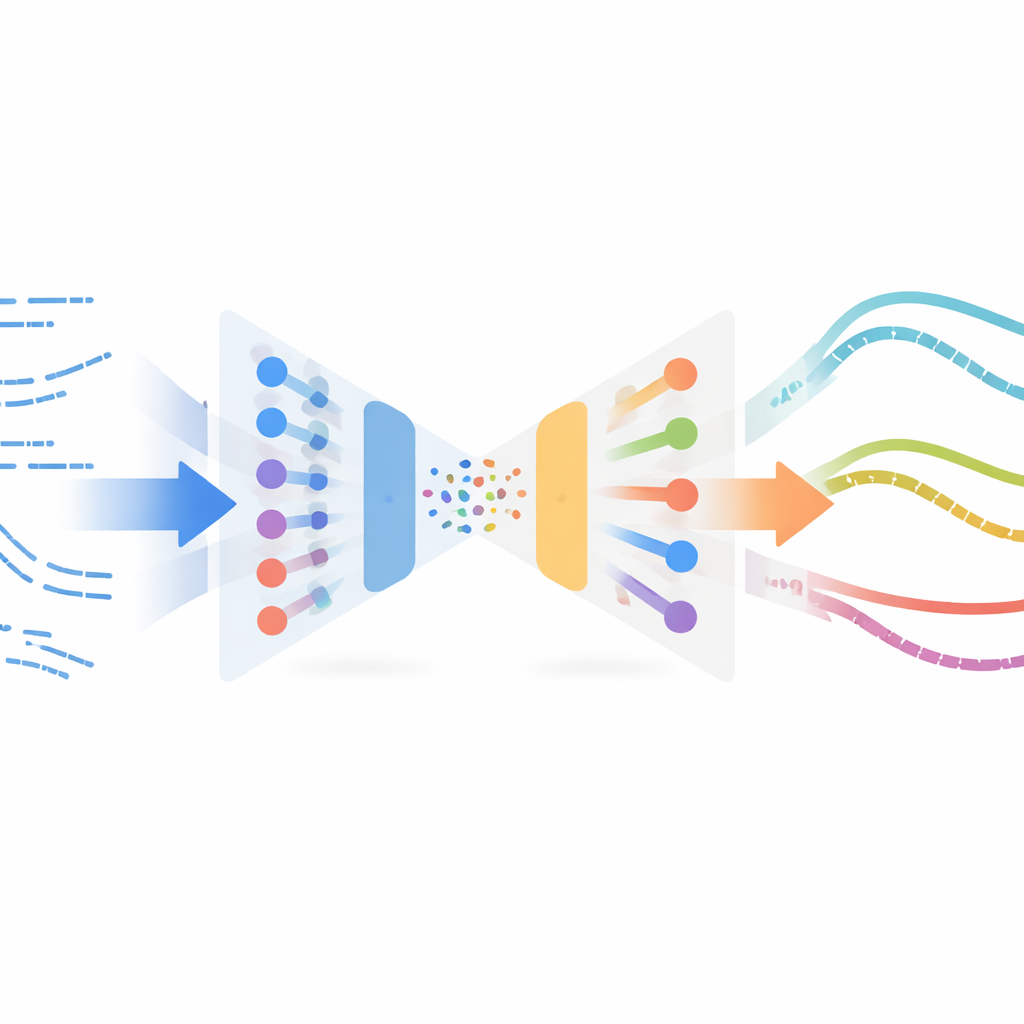
The authors adapt a surprising concept from image processing called neural style transfer. In image apps, style transfer takes the content of one image (say, a photograph) and the style of another (say, a painting) and blends them into a new picture. Here, instead of pictures, the “content” is the robot’s simulated cutting behavior over time, and the “style” is how real cutting looks in sensor data. The method learns a compact representation of short motion snippets using a variational autoencoder, a type of neural network that compresses and reconstructs time series. This network is first trained only on simulated trajectories so it can encode and decode robot states and actions reliably, without needing any labels or rewards from real experiments.
Mixing Real-World Feel into Simulated Experience
Once this encoder is trained, the system feeds all available real-world cutting examples—collected off-policy, meaning not from a final, polished controller—through the same network. In this shared latent space, simulated and real snippets that “feel” similar end up close together. The method then pairs simulated snippets with nearby real ones using a similarity measure and performs a style-transfer optimization: it gently alters each simulated snippet so that it keeps its task structure (for example, when and how the robot advances into the material) while taking on the statistical fingerprints of real sensor readings. These stylized snippets form a surrogate “real” dataset, automatically labelled with the expert actions from simulation, and are then used to train a new policy for the physical robot via imitation learning.
Putting the Method to the Test
The researchers tested their approach on a collaborative robot equipped with a motorized slitting saw, cutting a variety of materials including foam, cardboard, plastic, mica, and aluminum. The robot had to follow paths over flat, misaligned, and curved surfaces, adjusting feed rate, cutting depth, and stiffness as it went. The new style-transfer-based policy was compared to several alternatives: using the simulation-trained expert directly, a previous method that added a hand-crafted corrective model, and two advanced deep-learning translation schemes (a conditional variational autoencoder and a CycleGAN). Across case studies, the style-transfer policy cut faster than the raw simulation expert and the GAN-based method, and achieved similar or better performance than the more complex alternatives, while maintaining stable behavior and smoother tool paths.
What This Means for Future Robots
In plain terms, the study shows that robots can “borrow the feel” of real-world experience without extensive retraining or precise physical models. By blending simulated skill with the style of real sensor data, the robot learns a cutting strategy that transfers well to different materials and shapes, even when direct reward feedback from the real world is unavailable. This makes it more practical to deploy reinforcement-learning-based control in demanding, contact-heavy tasks such as disassembly, recycling, or even surgery, where experimenting on the real system is limited and mistakes are costly.
Citation: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Keywords: sim-to-real transfer, robotic cutting, reinforcement learning, neural style transfer, domain adaptation