Clear Sky Science · it
Trasferimento end-to-end di policy RL da simulazione a realtà basato su esempi e stilizzazione neurale con applicazione al taglio robotico
Insegnare ai robot a tagliare nel mondo reale
I robot stanno migliorando nell’apprendere compiti complessi in simulazioni al computer, ma spesso faticano quando vengono trasferiti nel mondo reale, dove attriti, usura e materiali disordinati rendono tutto meno prevedibile. Questo articolo esplora un nuovo modo per colmare quel divario: consentire a un robot che impara a tagliare materiali in modo sicuro ed efficiente in simulazione di continuare a farlo su materiali reali e sconosciuti, senza necessitare di grandi quantità di dati di addestramento reali.
Perché passare dallo schermo all’officina è difficile
L’apprendimento per rinforzo permette a un robot di scoprire strategie efficaci tramite tentativi ed errori, ma le prove nel mondo reale possono essere lente, rischiose e costose. Perciò gli ingegneri spesso addestrano in simulazione, dove milioni di prove sono economiche e sicure. Il problema è che il taglio simulato è sempre più pulito della realtà. In laboratorio lo strumento può vibrare, i motori hanno gioco, i materiali variano e i sensori deragliano. Queste differenze creano un “gap di dominio”: una policy che sembra eccellente in simulazione può avere prestazioni scadenti o perfino pericolose sull’hardware reale. Le soluzioni esistenti si basano o su modelli fisici dettagliati — che possono essere errati — o su complesse reti deep learning da riaddestrare ogni volta che cambiano l’hardware, i sensori o i materiali.
Pescare un’idea dall’arte digitale
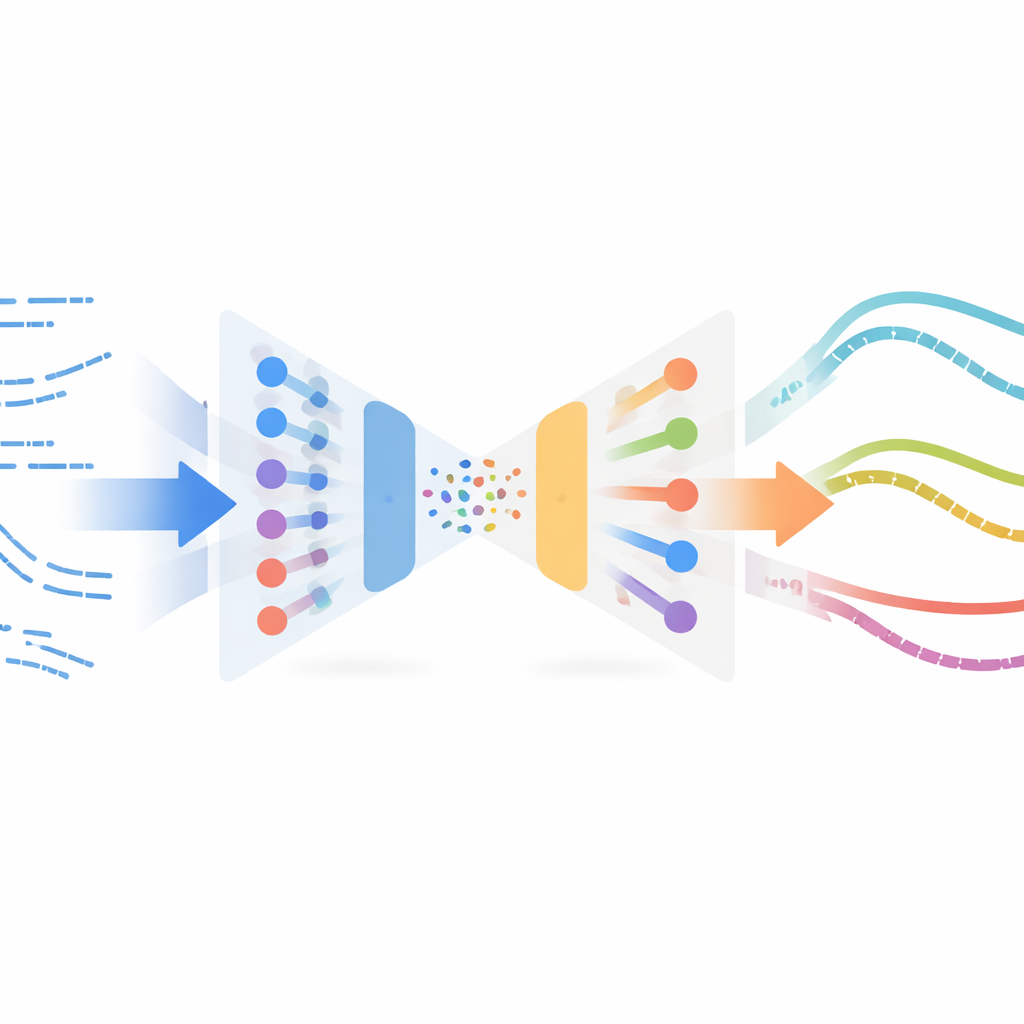
Gli autori adattano un’idea sorprendente dalla elaborazione delle immagini chiamata trasferimento di stile neurale. Nelle app per immagini, il trasferimento di stile prende il contenuto di una foto e lo stile di un dipinto e li fonde in una nuova immagine. Qui, invece delle immagini, il “contenuto” sono i comportamenti di taglio simulati del robot nel tempo, e lo “stile” è l’aspetto dei tagli reali nei dati dei sensori. Il metodo impara una rappresentazione compatta di brevi frammenti di moto usando un variational autoencoder, un tipo di rete neurale che comprime e ricostruisce serie temporali. Questa rete viene prima addestrata solo su traiettorie simulate in modo da poter codificare e decodificare stati e azioni del robot in modo affidabile, senza richiedere etichette o ricompense derivanti da esperimenti reali.
Mescolare la sensazione del mondo reale nell’esperienza simulata
Una volta addestrato l’encoder, il sistema passa attraverso la stessa rete tutti gli esempi reali di taglio disponibili — raccolti off-policy, cioè non da un controllore finale rifinito. In questo spazio latente condiviso, frammenti simulati e frammenti reali che “sembrano” simili finiscono vicini. Il metodo associa quindi frammenti simulati a quelli reali più prossimi usando una misura di somiglianza e svolge un’ottimizzazione di trasferimento di stile: altera delicatamente ogni frammento simulato in modo che mantenga la struttura del compito (per esempio quando e come il robot avanza nel materiale) pur assumendo le impronte statistiche delle letture dei sensori reali. Questi frammenti stilizzati formano un dataset surrogato “reale”, automaticamente etichettato con le azioni esperte provenienti dalla simulazione, e vengono poi usati per addestrare una nuova policy per il robot fisico tramite apprendimento per imitazione.
Mettere alla prova il metodo
I ricercatori hanno testato l’approccio su un robot collaborativo dotato di una sega a disco motorizzata, tagliando una varietà di materiali tra cui schiuma, cartone, plastica, mica e alluminio. Il robot doveva seguire traiettorie su superfici piane, disallineate e curve, regolando avanzamento, profondità di taglio e rigidità durante l’operazione. La nuova policy basata sul trasferimento di stile è stata confrontata con diverse alternative: l’esperto addestrato in simulazione usato direttamente, un metodo precedente che aggiungeva un modello correttivo fatto a mano e due avanzati schemi di traduzione deep learning (un variational autoencoder condizionale e una CycleGAN). Nei casi d’uso, la policy con trasferimento di stile ha tagliato più velocemente rispetto all’esperto puramente simulato e al metodo basato su GAN, ottenendo prestazioni simili o migliori rispetto alle alternative più complesse, mantenendo comportamento stabile e traiettorie dello strumento più fluide.
Cosa significa per i robot del futuro
In parole semplici, lo studio dimostra che i robot possono “prendere in prestito la sensazione” dell’esperienza reale senza lunghi riaddestramenti o modelli fisici precisi. Mescolando l’abilità simulata con lo stile dei dati sensoriali reali, il robot apprende una strategia di taglio che si trasferisce bene su materiali e forme diverse, anche quando il feedback di ricompensa diretto dal mondo reale non è disponibile. Questo rende più pratico l’impiego di controlli basati su apprendimento per rinforzo in compiti gravosi e con contatto, come smontaggio, riciclaggio o anche chirurgia, dove sperimentare sul sistema reale è limitato e gli errori sono costosi.
Citazione: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Parole chiave: trasferimento sim-to-real, taglio robotico, apprendimento per rinforzo, trasferimento di stile neurale, adattamento del dominio