Clear Sky Science · sv
Exempelbaserad end-to-end sim-till-verklighet RL-policyöverföring baserad på neuralt stilisering med tillämpning på robotisk kapning
Lära robotar att kapa i verkligheten
Robotar blir bättre på att lära sig komplexa uppgifter i datorsimuleringar, men de har ofta svårt när de flyttas ut i verkligheten, där friktion, slitage och röriga material gör allt mindre förutsägbart. Denna artikel undersöker ett nytt sätt att överbrygga den klyftan så att en robot som lär sig kapa material säkert och effektivt i simulering kan fortsätta göra det på verkliga, okända material, utan att behöva stora mängder ny träning på verklig data.
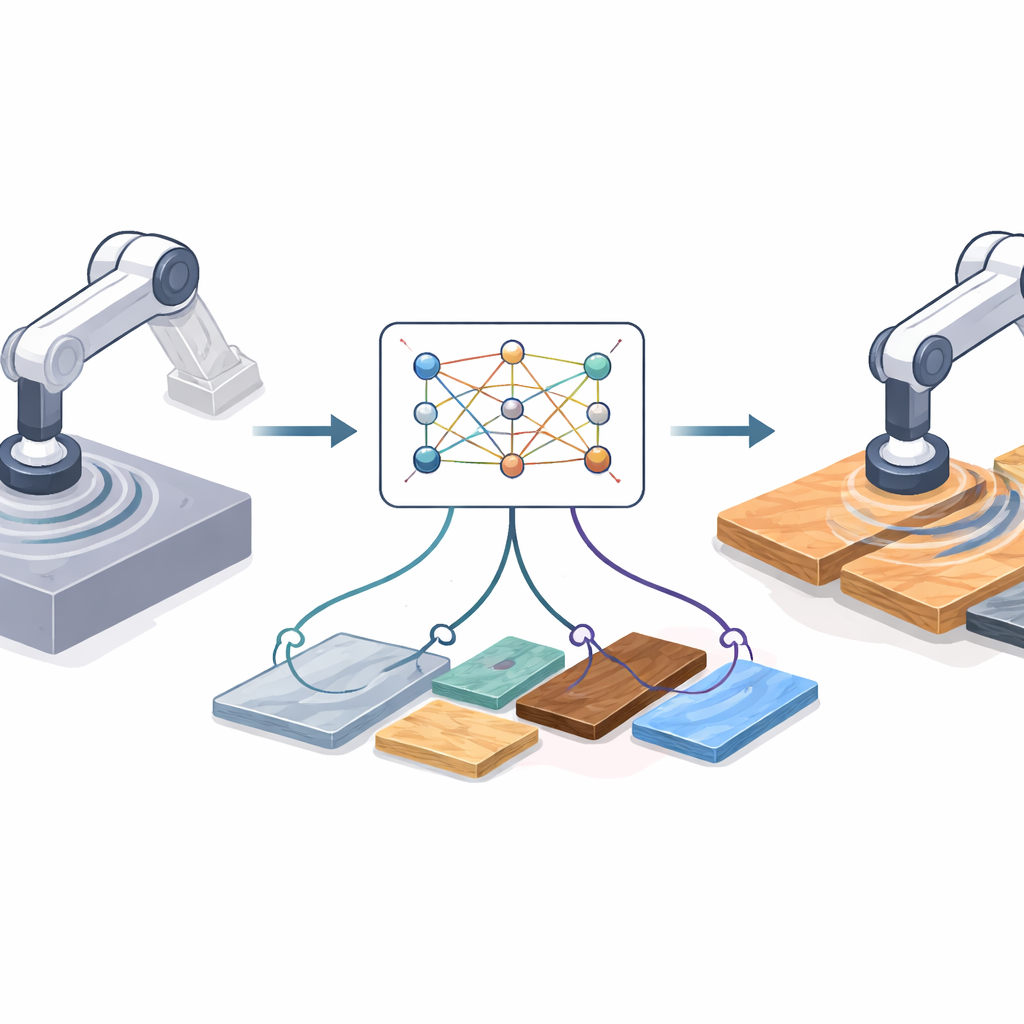
Varför övergången från skärm till verkstad är svår
Förstärkningsinlärning låter en robot upptäcka bra strategier genom försök och misstag, men verkliga försök kan vara långsamma, riskfyllda och kostsamma. Ingenjörer tränar därför ofta i simulering, där miljontals repetitionskörningar är billiga och säkra. Problemet är att simulerad kapning alltid är renare än verkligheten. I labbet kan verktygets vibrationer, motorernas slack, materialvariationer och sensoravdrift förekomma. Dessa skillnader skapar ett ”domängap”: en policy som ser lysande ut i simuleringen kan prestera dåligt eller till och med farligt på riktig hårdvara. Befintliga lösningar förlitar sig antingen på detaljerade fysikaliska modeller—som kan vara felaktiga—or på tung djupinlärningsarkitektur som måste omskolas varje gång hårdvaran, sensorerna eller materialen ändras.
Låna en idé från digital konst
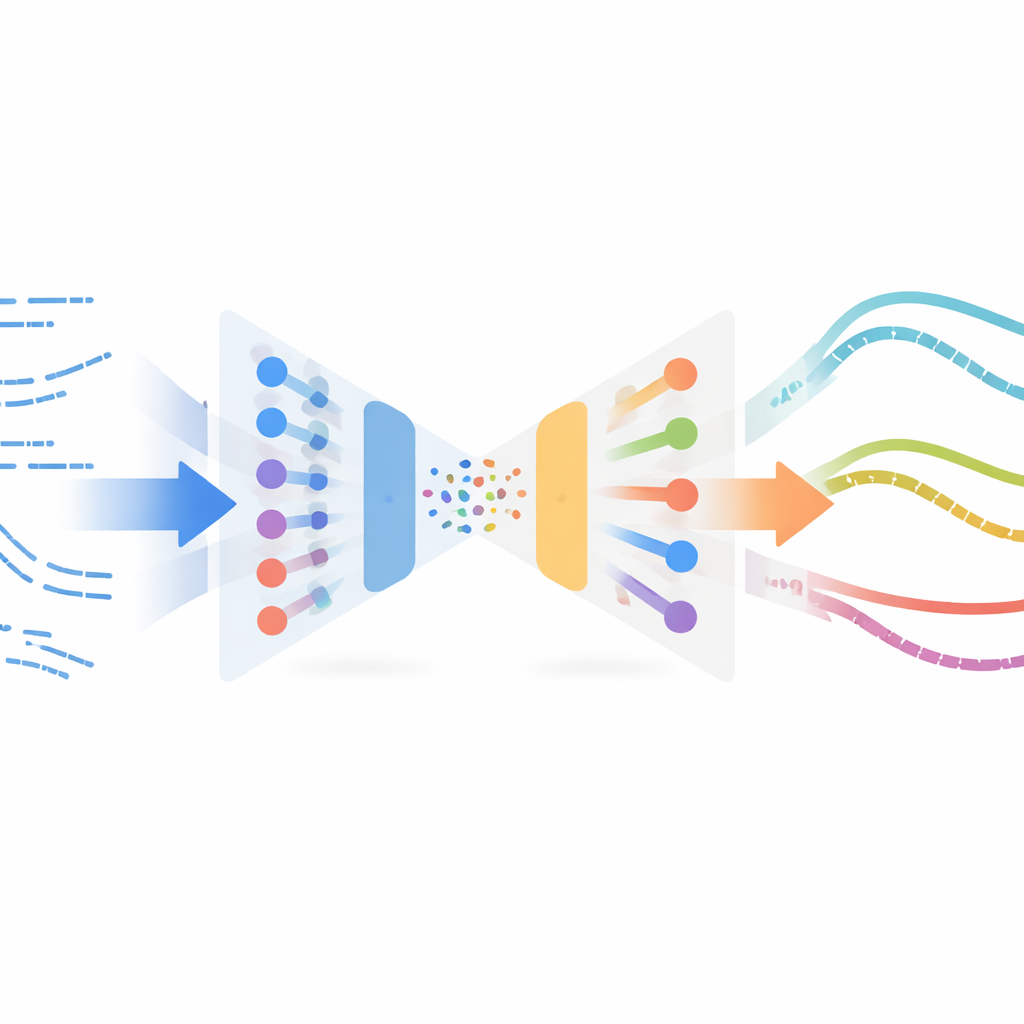
Författarna anpassar ett överraskande koncept från bildbehandling kallat neural stilöverföring. I bildappar tar stilöverföring innehållet i en bild (till exempel ett fotografi) och stilen i en annan (till exempel en målning) och blandar dem till en ny bild. Här, i stället för bilder, är ”innehållet” robotens simulerade kapbeteende över tid och ”stilen” är hur verklig kapning ser ut i sensordata. Metoden lär sig en kompakt representation av korta rörelsesnuttar med hjälp av en variational autoencoder, en typ av neuralt nätverk som komprimerar och rekonstruerar tidsserier. Detta nätverk tränas först endast på simulerade banor så att det kan koda och avkoda robottillstånd och handlingar pålitligt, utan att behöva några etiketter eller belöningar från verkliga experiment.
Blanda verklighetskänsla i simulerad erfarenhet
När denna encoder är tränad matar systemet alla tillgängliga verkliga kapexempel—insamlade off-policy, vilket betyder att de inte kommer från en färdig, förfinad controller—genom samma nätverk. I detta delade latenta rum hamnar simulerade och verkliga snuttar som ”känns” lika nära varandra. Metoden parar sedan ihop simulerade snuttar med närliggande verkliga med hjälp av ett likhetsmått och utför en stilöverföringsoptimering: den ändrar försiktigt varje simulerad snutt så att den behåller sin uppgiftsstruktur (till exempel när och hur roboten går in i materialet) samtidigt som den antar de statistiska fingeravtrycken från verkliga sensormätningar. Dessa stiliserade snuttar bildar en surrogat-"verklig" dataset, automatiskt etiketterad med expertåtgärderna från simuleringen, och används sedan för att träna en ny policy för den fysiska roboten via imitation learning.
Sätta metoden på prov
Forskarna testade sitt tillvägagångssätt på en kollaborativ robot utrustad med ett motoriserat slitsåg och kapade en rad material inklusive skum, kartong, plast, glimmer och aluminium. Roboten behövde följa banor över plana, feljusterade och kurvade ytor och justera matningshastighet, kapdjup och styvhet under arbetets gång. Den nya stilöverföringsbaserade policyn jämfördes med flera alternativ: att använda den simuleringstränade experten direkt, en tidigare metod som lade till en handgjord korrigeringsmodell, och två avancerade djupinlärningstranslationsscheman (en konditionell variational autoencoder och en CycleGAN). I fallstudierna kapade stilöverföringspolicyn snabbare än den råa simuleringsexperten och GAN-baserade metoden, och uppnådde liknande eller bättre prestanda än de mer komplexa alternativen, samtidigt som den bibehöll stabilt beteende och jämnare verktygsbanor.
Vad detta betyder för framtida robotar
Enkelt uttryckt visar studien att robotar kan ”låna känslan” av verklig erfarenhet utan omfattande omskolning eller precisa fysikaliska modeller. Genom att blanda simulerad skicklighet med stilen från verkliga sensordata lär sig roboten en kapstrategi som överförs väl till olika material och former, även när direkt belöningsfeedback från den verkliga världen saknas. Detta gör det mer praktiskt att använda förstärkningsinlärningsbaserad styrning i krävande, kontaktintensiva uppgifter som demontering, återvinning eller till och med kirurgi, där experimenterande på det verkliga systemet är begränsat och misstag är kostsamma.
Citering: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Nyckelord: sim-till-verklighet-överföring, robotisk kapning, förstärkningsinlärning, neural stilöverföring, domänanpassning