Clear Sky Science · es
Transferencia de políticas RL sim-a-real basada en ejemplos de extremo a extremo mediante estilización neuronal con aplicación al corte robótico
Enseñar a los robots a cortar en el mundo real
Los robots mejoran en el aprendizaje de tareas complejas en simulaciones por ordenador, pero a menudo fallan cuando se trasladan al mundo real, donde la fricción, el desgaste y los materiales desordenados hacen todo menos predecible. Este artículo explora una nueva manera de salvar esa brecha para que un robot que aprende a cortar materiales de forma segura y eficiente en simulación pueda seguir haciéndolo sobre materiales reales y desconocidos, sin necesitar grandes cantidades de datos de entrenamiento reales.
Por qué es difícil pasar de la pantalla al taller
El aprendizaje por refuerzo permite que un robot descubra buenas estrategias por ensayo y error, pero los ensayos en el mundo real pueden ser lentos, riesgosos y caros. Por ello, los ingenieros suelen entrenar en simulación, donde millones de prácticas son baratas y seguras. El problema es que el corte simulado siempre es más limpio que la realidad. En el laboratorio, la herramienta puede vibrar, los motores tener holgura, los materiales variar y los sensores derivar. Estas diferencias crean una “brecha de dominio”: una política que parece brillante en simulación puede rendir mal o incluso ser peligrosa en hardware real. Las soluciones existentes dependen de modelos físicos detallados—que pueden estar equivocados—o de complejas arquitecturas de aprendizaje profundo que deben volver a entrenarse cada vez que cambian el hardware, los sensores o los materiales.
Tomando una idea del arte digital
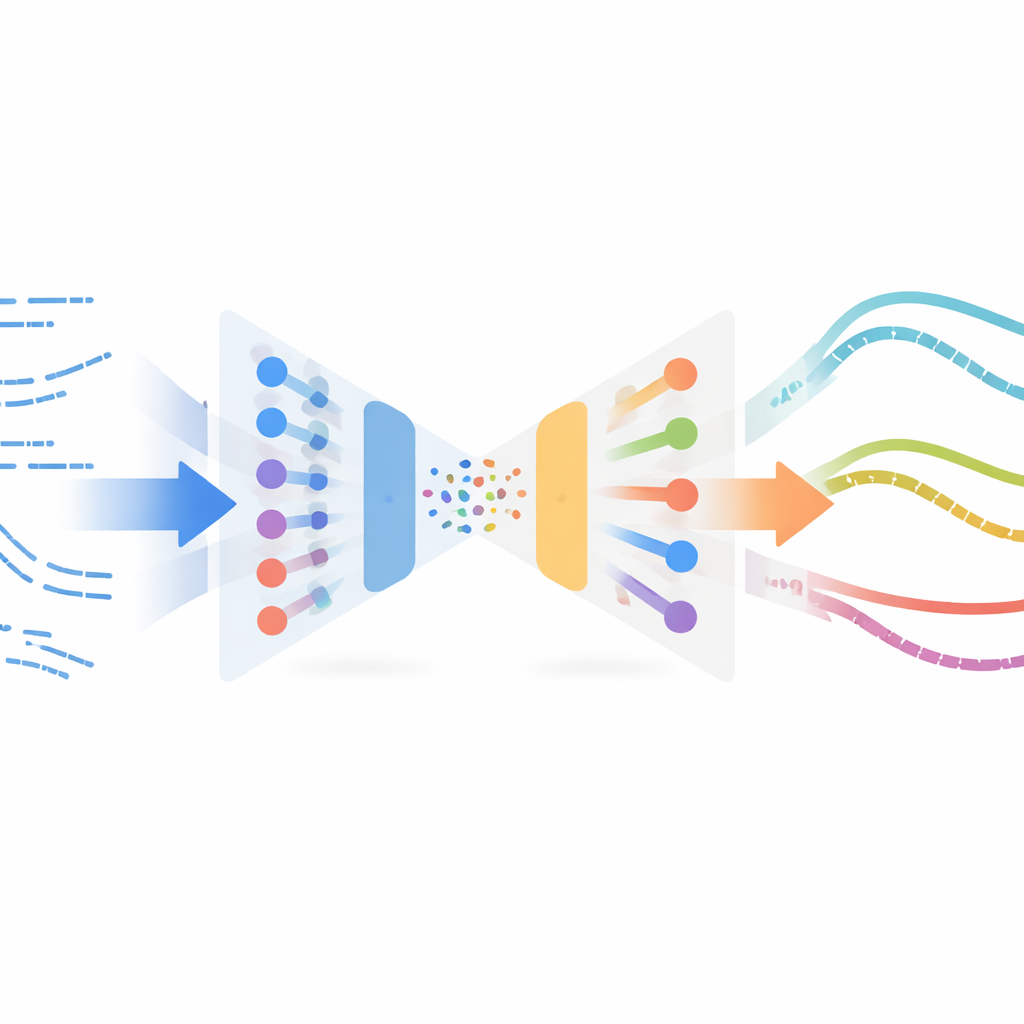
Los autores adaptan un concepto sorprendente del procesamiento de imágenes llamado transferencia de estilo neuronal. En aplicaciones de imagen, la transferencia de estilo toma el contenido de una imagen (por ejemplo, una fotografía) y el estilo de otra (por ejemplo, una pintura) y los mezcla en una nueva imagen. Aquí, en vez de imágenes, el “contenido” es el comportamiento de corte simulado del robot a lo largo del tiempo y el “estilo” es cómo se ve el corte real en los datos de los sensores. El método aprende una representación compacta de fragmentos cortos de movimiento usando un autoencoder variacional, un tipo de red neuronal que comprime y reconstruye series temporales. Esta red se entrena primero solo con trayectorias simuladas para que pueda codificar y decodificar estados y acciones del robot de forma fiable, sin necesitar etiquetas ni recompensas de experimentos reales.
Incorporando la sensación del mundo real a la experiencia simulada
Una vez entrenado este codificador, el sistema pasa todos los ejemplos reales disponibles de corte—recogidos off-policy, es decir, no procedentes de un controlador final y pulido—a través de la misma red. En este espacio latente compartido, los fragmentos simulados y reales que “se sienten” similares quedan cerca unos de otros. El método empareja entonces fragmentos simulados con los reales cercanos mediante una medida de similitud y realiza una optimización de transferencia de estilo: altera suavemente cada fragmento simulado para que conserve su estructura de tarea (por ejemplo, cuándo y cómo el robot avanza en el material) mientras adopta las huellas estadísticas de las lecturas reales de los sensores. Estos fragmentos estilizados forman un conjunto de datos sustituto “real”, etiquetado automáticamente con las acciones expertas de la simulación, y se usan después para entrenar una nueva política para el robot físico mediante aprendizaje por imitación.
Poniendo el método a prueba
Los investigadores probaron su enfoque en un robot colaborativo equipado con una sierra circular motorizada, cortando una variedad de materiales que incluían espuma, cartón, plástico, mica y aluminio. El robot tuvo que seguir trayectorias sobre superficies planas, desalineadas y curvas, ajustando la velocidad de avance, la profundidad de corte y la rigidez según avanzaba. La nueva política basada en transferencia de estilo se comparó con varias alternativas: usar directamente al experto entrenado en simulación, un método previo que añadía un modelo correctivo artesanal y dos esquemas avanzados de traducción por aprendizaje profundo (un autoencoder variacional condicional y un CycleGAN). En los estudios de caso, la política con transferencia de estilo cortó más rápido que el experto de simulación sin modificar y que el método basado en GAN, y alcanzó un rendimiento similar o mejor que las alternativas más complejas, manteniendo un comportamiento estable y trayectorias de herramienta más suaves.
Qué significa esto para los robots del futuro
En términos sencillos, el estudio demuestra que los robots pueden “tomar prestada la sensación” de la experiencia real sin un reentrenamiento extensivo ni modelos físicos precisos. Al mezclar la pericia simulada con el estilo de los datos reales de sensores, el robot aprende una estrategia de corte que se transfiere bien a distintos materiales y formas, incluso cuando no hay retroalimentación de recompensa directa desde el mundo real. Esto hace más práctico desplegar control basado en aprendizaje por refuerzo en tareas exigentes y con mucho contacto, como el desmontaje, el reciclaje o incluso la cirugía, donde experimentar en el sistema real es limitado y los errores son costosos.
Cita: Hathaway, J., Rastegarpanah, A. & Stolkin, R. End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting. Sci Rep 16, 13240 (2026). https://doi.org/10.1038/s41598-026-41735-5
Palabras clave: transferencia sim-a-real, corte robótico, aprendizaje por refuerzo, transferencia de estilo neuronal, adaptación de dominio