Clear Sky Science · zh
一种用于人机交互中人类情感识别的新型多模块神经网络策略
教会机器人读懂我们的情绪
随着机器人进入家庭、医院和课堂,仅仅执行指令已不够。要真正有用,它们必须感知我们的情绪并调整行为——安抚紧张的病人、平复情绪激动的司机,或鼓励害羞的学生。本文提出了一种新方法,使机器人能够快速且准确地从面部表情中读出人类情绪,即便在光照、背景杂乱或部分遮挡等常使机器困惑的现实环境中也能表现良好。

为何具有情感感知的机器人很重要
人机交互不仅依赖语音命令和精确动作。人们通过面部自然而然地传达情绪,我们也期望具有社会智能的机器能注意到并做出恰当反应。现有的情感识别系统通常仅在受控的实验室条件下表现良好:面部居中、光照充足且清晰可见。然而在日常生活中,面部可能转向、部分被遮挡或在光线较差的情况下被捕捉到,而且某些情绪——例如恐惧或厌恶——在训练图像中出现得更少。作者旨在通过设计一种足够稳健的情感识别系统来弥合这一差距,以便在安检、医疗支持、驾驶员监测和个性化教育等实际场景中部署。
融合多种类脑启发网络
研究者没有依赖单一的人工神经网络,而是构建了一个“多模块”系统,结合若干先进图像分析模型的优势。四种不同的卷积和基于变换器的网络分别以各自方式处理输入的人脸图像:有些注重实时使用的效率,另一些擅长捕捉细节或面部区域间的长程关系,还有一个强调诸如眼睛和嘴巴等关键区域。它们的输出被融合到一个丰富的共享表示中,同时捕捉细微纹理与整体表情模式。该融合表示随后被送入一组分类器,包括卷积网络、可在视频中跟踪随时间变化的循环单元以及传统的多层感知器,三者的组合投票产生最终的情绪标签。
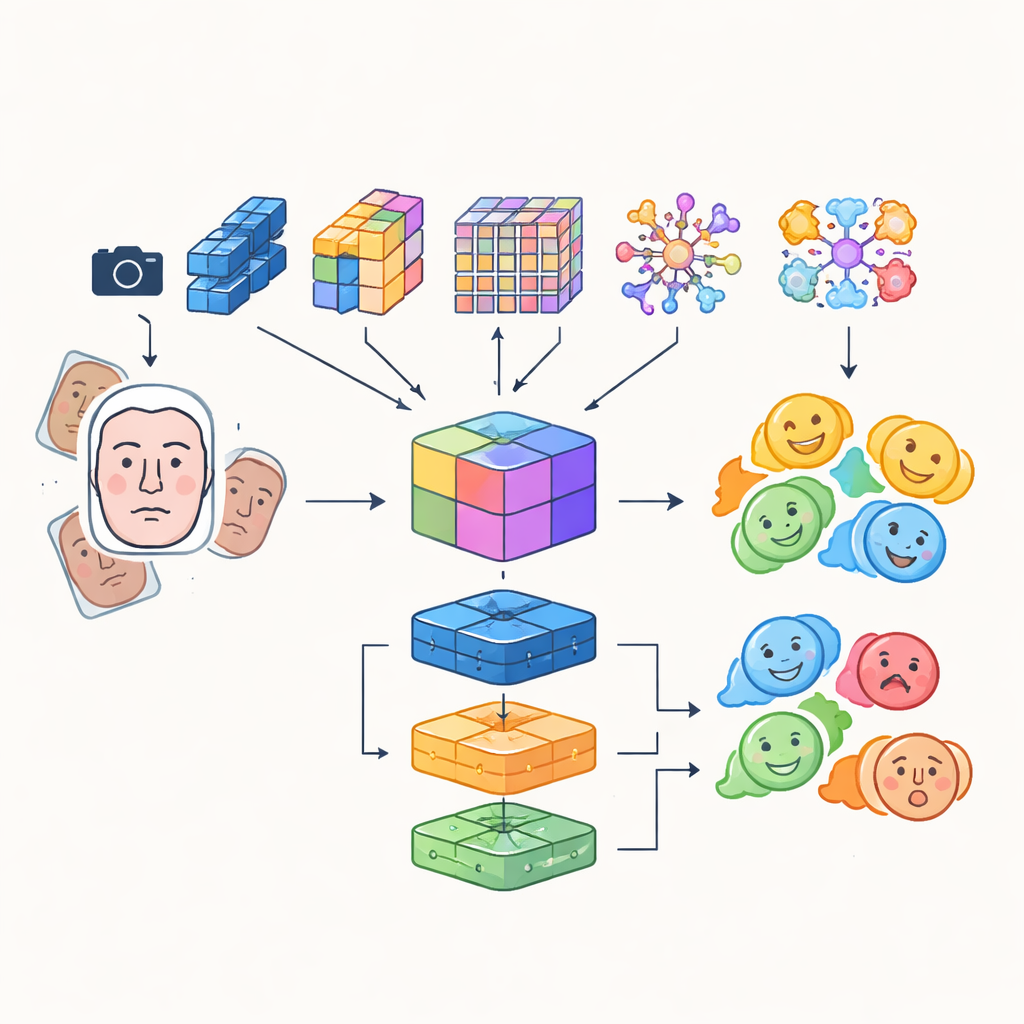
更锐利的“眼睛”和更聪明的训练数据
为确保机器人在正确时刻关注到正确的人脸,系统集成了检测变换器——一种现代目标检测方法,它将寻找人脸视为直接预测任务,而不是用许多重叠框扫描图像。该组件学会可靠定位人脸,即便在拥挤场景中也能工作,并将干净、构图良好的人脸区域传递给情感模块。作者还将自动学习到的特征与早期的手工描述子融合,这些描述子关注边缘和局部纹理,形成一种混合特征集,更能抵抗光照变化和部分遮挡。为弥补情感类别自然不平衡的问题——微笑面孔远多于恐惧面孔——他们大量增强训练数据,通过旋转、翻转及改变颜色和对比度,有效生成更多多样化的欠代表表情样本。
在真实且具有挑战性的人脸上测试
团队在两个人脸表情常用数据库——AffectNet 和 CK+——以及他们实验室录制的新建自定义数据集上评估了方法。该自定义数据集刻意包含苛刻的光照、复杂且变化的背景以及来自不同文化背景的人群,更好地模拟机器人在现实中可能遇到的情形。在这三套数据集中,多模块系统均取得了较高准确率:在公开集合上超过90%,在精心策划的实验室数据上约98%。数据增强持续提升性能,尤其在恐惧和厌恶等难辨情绪上效果显著,且该集成方案优于传统手工流水线和现代单网络基线。重要的是,通过将设计以高效模型族为中心,作者保持了足够快的处理速度以实现实时响应。
构建更敏感的机器伙伴
从实践角度看,这项工作表明可以为机器人配备分层视觉系统,不仅能找到人脸,还能以适合日常使用的可靠度读取其情绪内容。通过堆叠多种专用网络、加入现代人脸检测模块并谨慎扩展和平衡训练数据,系统能够在困难视觉条件下理解广泛的基本情绪。对非专家而言,结论很明确:凭借此类架构,未来的机器人和交互设备将更能感知某人是高兴、烦恼、焦虑还是冷漠——并据此调整其行为——使我们与机器的互动更自然、更具支持性、更有人情味。
引用: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
关键词: 人机交互, 情感识别, 面部表情, 深度学习, 基于变换器的视觉