Clear Sky Science · ar
استراتيجية شبكات عصبية متعددة الوحدات جديدة للتعرف على المشاعر البشرية في التفاعل بين الإنسان والروبوت
تعليم الروبوتات قراءة مشاعرنا
مع دخول الروبوتات إلى المنازل والمستشفيات والفصول الدراسية، لم يعد كافياً أن تلتزم فقط بالتعليمات. ولكي تكون مفيدة حقًا، يجب أن تلاحِظ كيف نشعر وتكيّف سلوكها — مواساة مريض متوتر، تهدئة سائق مضطرب، أو تشجيع طالب خجول. تعرض هذه الورقة طريقة جديدة لقراءة الروبوتات لمشاعر البشر من تعابير الوجه بسرعة ودقّة، حتى في بيئات العالم الحقيقي الفوضوية حيث يربك الإضاءة وخلفيات المشهد والانسدادات الجزئية الآلات غالبًا.

لماذا تهم الروبوتات الواعية عاطفيًا
يعتمد التفاعل بين الإنسان والروبوت على أكثر من الأوامر الصوتية والحركات الدقيقة. يشير الناس بطبيعتهم إلى المشاعر عبر وجوههم، ونتوقع من الآلات الاجتماعية الذكية أن تلاحظ وتستجيب بشكل مناسب. تعمل أنظمة التعرف على المشاعر القائمة غالبًا بشكل جيد في ظروف المختبر المسيطر عليها فقط: حيث تكون الوجوه في الوسط، مضاءة جيدًا، وواضحة. في الحياة اليومية، مع ذلك، تتحوّل الوجوه أو تُخفى جزئيًا أو تُلتقط في إضاءة ضعيفة، وتظهر بعض المشاعر — مثل الخوف أو الاشمئزاز — أقلّ تكرارًا في صور التدريب. يهدف المؤلفون إلى سد هذه الفجوة من خلال تصميم نظام للتعرف على المشاعر قوي بما يكفي للنشر في العالم الحقيقي في سياقات مثل فحص الأمن، دعم الرعاية الصحية، مراقبة السائق، والتعليم المخصّص.
مزج شبكات متعددة مستوحاة من الدماغ
بدلاً من الاعتماد على شبكة عصبية اصطناعية واحدة، يبني الباحثون نظامًا «متعدد الوحدات» يجمع نقاط القوة لعدة نماذج متقدمة لتحليل الصور. تفحص أربع شبكات مختلفة قائمة على الالتفاف والمحولات صور الوجوه الواردة كلٌّ بطريقته: يركّز بعضها على الكفاءة للاستخدام في الزمن الحقيقي، ويتفوّق بعضها الآخر في التقاط التفاصيل الدقيقة أو العلاقات بعيدة المدى بين مناطق الوجه، وتبرز إحداها المناطق الحرجة مثل العينين والفم. تدمج مخرجاتهم في تمثيل مشترك غني يلتقط كلًا من النسيج الدقيق والأنماط العامة للتعبير. يُغذى هذا التمثيل المدمج بعد ذلك إلى مجموعة من المصنفات، بما في ذلك شبكة التلافيف، ووحدة متكررة قادرة على تتبع التغيّرات مع الزمن في الفيديو، وشبكة إدراك متعددة الطبقات تقليدية، حيث يُنتِج تصويتهم المشترك تسمية العاطفة النهائية.
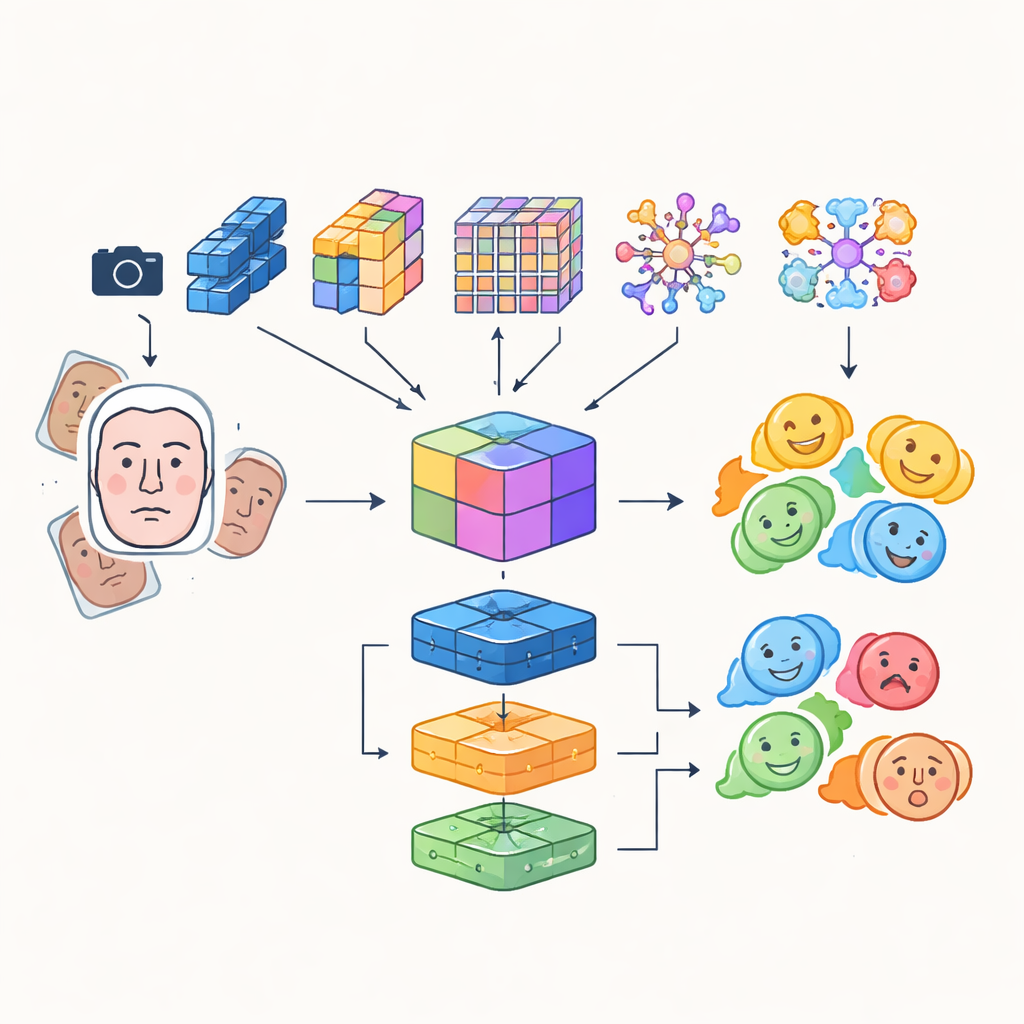
عيون أكثر حدة وبيانات تدريب أذكى
لضمان تركيز الروبوت على الوجه الصحيح في اللحظة المناسبة، يدمج النظام محول الكشف، نهج حديث لاكتشاف الكائنات يعامل إيجاد الوجه كمهمة تنبؤ مباشر بدلاً من مسح الصورة بعدد كبير من المربعات المتداخلة. يتعلّم هذا المكوّن تحديد الوجوه بشكل موثوق حتى في المشاهد المزدحمة، ويمرّر مناطق وجه نظيفة ومؤطرة جيدًا إلى وحدات التعرف على المشاعر. كما يدمج المؤلفون الميزات المتعلّمة تلقائيًا مع أوصاف قديمة مصنوعة يدويًا تُولي اهتمامًا للحواف والنسيج المحلي، مكوّنين مجموعة ميزات هجينة تقاوم تغيّر الإضاءة والانسدادات الجزئية بشكل أفضل. وللتعويض عن عدم توازن فئات المشاعر الطبيعي — وجود الكثير من الوجوه المبتسمة مقارنة بالخائفة — يعزّزون بيانات التدريب بشكل كبير عبر التدوير، والانعكاس، وتغيير الألوان والتباين، مولدين فعليًا أمثلة جديدة ومتنوّعة للتعابير الممثلة تمثيلًا ناقصًا.
الاختبار على وجوه حقيقية وصعبة
يقيّم الفريق نهجهم على قاعدتي بيانات للتعبيرات الوجهيّة مستخدمتين على نطاق واسع — AffectNet و CK+ — بالإضافة إلى مجموعة بيانات جديدة مخصّصة سُجلت في مختبرهم. تتضمّن هذه المجموعة المخصّصة عمداً إضاءة قاسية، وخلفيات معقّدة ومتغيرة، وأشخاصًا من بيئات ثقافية متنوّعة، محاكيةً بشكل أفضل الحالات التي قد يواجهها الروبوت في الواقع. عبر القواعد الثلاث، يحقّق النظام متعدد الوحدات دقة عالية، متجاوزًا 90% على المجموعات العامة وحوالي 98% على بيانات المختبر المنتقاة بعناية. يعزّز تكبير البيانات الأداء باستمرار، لا سيما للمشاعر الصعبة مثل الخوف والاشمئزاز، ويتفوّق التجميع المشترك على كلٍ من خطوط الأنابيب التقليدية المصنوعة يدويًا وأساليب الشبكة الواحدة الحديثة. ومن المهم، بأنّ التركيز على عائلة نماذج فعّالة حافظ على سرعة المعالجة كافية للاستجابات في الزمن الحقيقي.
بناء شركاء آليين أكثر حساسية
على الصعيد العملي، تُظهر هذه الدراسة أن الروبوتات يمكن تجهيزها بنظام رؤية متعدد الطبقات ليس فقط لإيجاد الوجوه بل أيضًا لقراءة محتواها العاطفي بمستوى من الموثوقية مناسب للاستخدام اليومي. من خلال تكديس شبكات متخصصة متعددة، وإضافة مكوّن حديث لكشف الوجوه، وتوسيع وموازنة بيانات التدريب بعناية، يستطيع النظام فهم مجموعة واسعة من المشاعر الأساسية حتى تحت ظروف بصرية صعبة. للمستخدمين غير المتخصصين، الخلاصة واضحة: بهذه البنية، ستتمكن الروبوتات والأجهزة التفاعلية المستقبلية من استشعار ما إذا كان الشخص سعيدًا أو منزعجًا أو قلقًا أو لا مباليًا — وتكييف أفعالها وفقًا لذلك — مما يجعل تفاعلاتنا مع الآلات أكثر طبيعية وداعمة وإنسانية.
الاستشهاد: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
الكلمات المفتاحية: التفاعل بين الإنسان والروبوت, التعرف على المشاعر, تعبيرات الوجه, التعلّم العميق, الرؤية المبنية على المحول