Clear Sky Science · pl
Nowa wielomodułowa strategia sieci neuronowych do rozpoznawania ludzkich emocji w interakcji człowiek-robot
Uczenie robotów rozumienia naszych uczuć
W miarę jak roboty trafiają do domów, szpitali i szkół, samo wykonywanie poleceń przestaje wystarczać. Aby być naprawdę pomocne, muszą wyczuwać nasze emocje i dostosowywać zachowanie — pocieszyć zdenerwowanego pacjenta, uspokoić zdenerwowanego kierowcę czy dodać otuchy nieśmiałemu uczniowi. W artykule przedstawiono nowy sposób, dzięki któremu roboty mogą szybko i dokładnie odczytywać ludzkie emocje z mimiki, nawet w złożonych, rzeczywistych warunkach, gdzie oświetlenie, zagracone tło i częściowe zasłonięcia często mylą systemy.

Dlaczego emocjonalnie świadome roboty mają znaczenie
Interakcja człowiek–robot opiera się na czymś więcej niż poleceniach głosowych i precyzyjnych ruchach. Ludzie naturalnie sygnalizują emocje przez twarz i oczekujemy, że społecznie inteligentne maszyny zauważą to i odpowiednio zareagują. Istniejące systemy rozpoznawania emocji często działają dobrze jedynie w kontrolowanych warunkach laboratoryjnych: twarze są wyśrodkowane, dobrze oświetlone i wyraźne. W codziennym życiu twarze bywają odwrócone, częściowo zasłonięte lub zarejestrowane w słabym świetle, a niektóre emocje — np. strach czy wstręt — występują w zbiorach treningowych znacznie rzadziej. Autorzy dążą do zmniejszenia tej przepaści, projektując system rozpoznawania emocji odporny na warunki rzeczywiste, przydatny w takich zastosowaniach jak kontrola bezpieczeństwa, wsparcie medyczne, monitorowanie kierowcy czy spersonalizowana edukacja.
Łączenie wielu sieci inspirowanych mózgiem
Zamiast polegać na jednej sztucznej sieci neuronowej, badacze zbudowali system „wielomodułowy”, który łączy zalety kilku zaawansowanych modeli analizy obrazu. Cztery różne sieci konwolucyjne i oparte na transformerach analizują nadchodzące obrazy twarzy każda na swój sposób: jedne skupiają się na efektywności zapewniającej działanie w czasie rzeczywistym, inne doskonale wychwytują drobne detale lub dalekosiężne zależności między obszarami twarzy, a jedna wyróżnia krytyczne rejony, takie jak oczy i usta. Ich wyjścia są łączone w bogatą, wspólną reprezentację, która obejmuje zarówno subtelne faktury, jak i globalne wzorce mimiczne. Ta zintegrowana reprezentacja trafia następnie do zestawu klasyfikatorów, w tym sieci konwolucyjnej, jednostki rekurencyjnej potrafiącej śledzić zmiany w czasie w wideo oraz klasycznego perceptronu wielowarstwowego; ich wspólne decyzje generują ostateczną etykietę emocji.
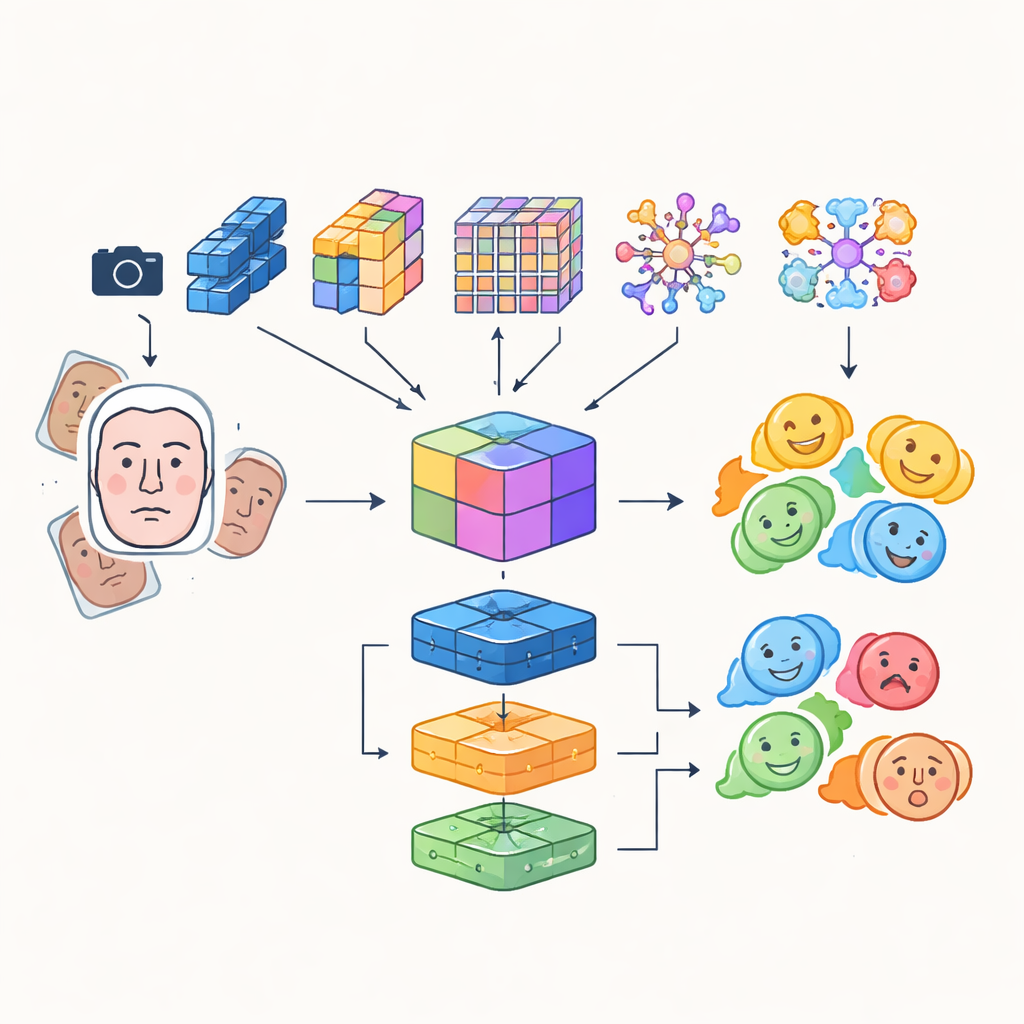
Bardziej precyzyjne wykrywanie i mądrzejsze dane treningowe
Aby upewnić się, że robot skupia się na właściwej twarzy w odpowiednim momencie, system integruje detekcyjny transformer — nowoczesne podejście do wykrywania obiektów, które traktuje znalezienie twarzy jako zadanie bezpośredniej predykcji zamiast skanowania obrazu wieloma nakładającymi się ramkami. Ten komponent uczy się precyzyjnie lokalizować twarze nawet w zatłoczonych scenach i przekazuje czyste, dobrze wykadrowane obszary twarzy modułom rozpoznawania emocji. Autorzy łączą również automatycznie uczone cechy z tradycyjnymi, ręcznie projektowanymi deskryptorami zwracającymi uwagę na krawędzie i lokalną teksturę, tworząc hybrydowy zestaw cech lepiej odporny na zmiany oświetlenia i częściowe zasłonięcia. Aby zrekompensować naturalną nierównowagę kategorii emocji — znacznie więcej uśmiechniętych twarzy niż przestraszonych — intensywnie augmentują dane treningowe przez obracanie, odbicia oraz zmianę kolorów i kontrastu, skutecznie generując nowe, zróżnicowane przykłady słabiej reprezentowanych ekspresji.
Testy na rzeczywistych i wymagających zestawach twarzy
Zespół ocenił swoje podejście na dwóch powszechnie używanych bazach danych mimiki twarzy — AffectNet i CK+ — oraz na nowym, własnoręcznie przygotowanym zbiorze nagranym w ich laboratorium. Ten niestandardowy zestaw celowo zawiera ostre oświetlenie, złożone i zmienne tła oraz osoby z różnych środowisk kulturowych, lepiej naśladując sytuacje, z którymi robot może spotkać się w terenie. We wszystkich trzech zbiorach system wielomodułowy osiąga wysoką dokładność, przekraczając 90% na publicznych kolekcjach i około 98% na starannie przygotowanych danych laboratoryjnych. Augmentacja danych konsekwentnie poprawia wyniki, szczególnie dla trudnych emocji, takich jak strach i wstręt, a zespół modeli przewyższa zarówno klasyczne rozwiązania oparte na ręcznie projektowanych cechach, jak i nowoczesne systemy oparte na pojedynczej sieci. Co ważne, dzięki skoncentrowaniu projektu na wydajnej rodzinie modeli, autorzy utrzymują przetwarzanie wystarczająco szybkie do działania w czasie rzeczywistym.
Budowanie bardziej wrażliwych maszyn towarzyszących
W praktyce praca ta pokazuje, że roboty mogą być wyposażone w warstwowy system widzenia, który nie tylko odnajduje twarze, ale także odczytuje ich emocjonalną zawartość z poziomem niezawodności odpowiednim do codziennego użytku. Poprzez łączenie kilku wyspecjalizowanych sieci, dodanie nowoczesnego modułu wykrywania twarzy oraz staranne rozszerzanie i wyrównywanie danych treningowych, system potrafi rozpoznawać szeroki zakres podstawowych emocji nawet w trudnych warunkach wizualnych. Dla osób niebędących ekspertami wniosek jest prosty: dzięki takiej architekturze przyszłe roboty i interaktywne urządzenia będą lepiej wyczuwać, kiedy ktoś jest szczęśliwy, zdenerwowany, niespokojny czy obojętny — i odpowiednio dostosowywać swoje działania — sprawiając, że nasze interakcje z maszynami będą bardziej naturalne, wspierające i ludzkie.
Cytowanie: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Słowa kluczowe: interakcja człowiek-robot, rozpoznawanie emocji, ekspresje twarzy, uczenie głębokie, wizja oparta na transformerach