Clear Sky Science · de
Eine neuartige Multi-Modul-Neuronale-Netzwerk-Strategie zur Erkennung menschlicher Emotionen in der Mensch-Roboter-Interaktion
Roboter beibringen, unsere Gefühle zu lesen
Da Roboter Einzug in Wohnungen, Krankenhäuser und Klassenzimmer halten, reicht es nicht mehr, dass sie nur Befehle ausführen. Um wirklich hilfreich zu sein, müssen sie wahrnehmen, wie wir uns fühlen, und ihr Verhalten anpassen — einen nervösen Patienten trösten, einen aufgebrachten Fahrer beruhigen oder einen schüchternen Schüler ermutigen. Diese Arbeit stellt einen neuen Ansatz vor, mit dem Roboter menschliche Emotionen aus Gesichtsausdrücken schnell und präzise erkennen können, selbst in unordentlichen realen Umgebungen, in denen Beleuchtung, Hintergrundchaos und partielle Verdeckungen Maschinen oft irritieren.

Warum emotional bewusste Roboter wichtig sind
Mensch–Roboter-Interaktion beruht auf mehr als Sprachbefehlen und präzisen Bewegungen. Menschen signalisieren Gefühle natürlich über ihr Gesicht, und wir erwarten von sozial intelligenten Maschinen, dass sie das bemerken und angemessen reagieren. Bestehende Systeme zur Emotionserkennung funktionieren häufig nur unter kontrollierten Laborbedingungen gut: Gesichter sind zentriert, gut beleuchtet und klar sichtbar. Im Alltag hingegen sind Gesichter oft gedreht, teilweise verdeckt oder bei schlechter Beleuchtung aufgenommen, und einige Emotionen — etwa Angst oder Ekel — kommen in Trainingsbildern viel seltener vor. Die Autoren wollen diese Lücke schließen, indem sie ein System zur Emotionserkennung entwerfen, das robust genug für reale Einsätze in Bereichen wie Sicherheitskontrollen, Gesundheitsversorgung, Fahrüberwachung und personalisierte Bildung ist.
Verschiedene gehirninspirierte Netze kombinieren
Anstatt sich auf ein einzelnes künstliches neuronales Netz zu verlassen, bauen die Forschenden ein „Multi-Modul“-System, das die Stärken mehrerer fortschrittlicher Bildanalysemodelle kombiniert. Vier verschiedene, auf Faltung und Transformern basierende Netzwerke untersuchen dabei eingehende Gesichtsaufnahmen auf je eigene Weise: Einige legen Wert auf Effizienz für den Echtzeit-Einsatz, andere sind gut darin, feine Details oder fernreichende Beziehungen zwischen Gesichtsregionen zu erfassen, und eines hebt kritische Bereiche wie Augen und Mund hervor. Deren Ausgaben werden zu einer reichen gemeinsamen Repräsentation verschmolzen, die sowohl subtile Texturen als auch globale Ausdrucksmuster erfasst. Diese verschmolzene Repräsentation wird anschließend einer Gruppe von Klassifikatoren zugeführt — darunter ein Faltungsnetz, eine rekurrente Einheit, die zeitliche Veränderungen in Videos verfolgen kann, und ein traditionelles mehrschichtiges Perzeptron — deren kombinierte Abstimmung das endgültige Emotionslabel ergibt.
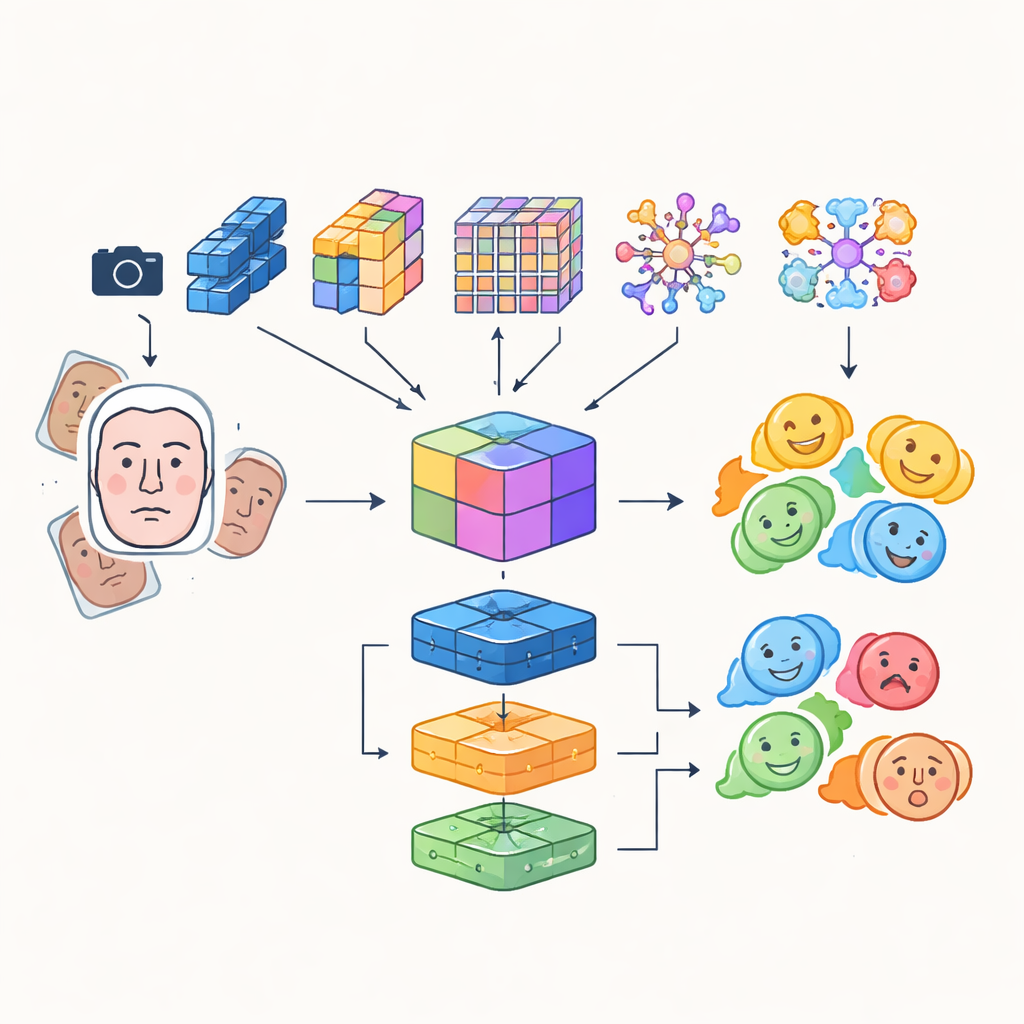
Scharfere Wahrnehmung und klügeres Trainingsmaterial
Damit der Roboter im richtigen Moment auf das richtige Gesicht fokussiert, integriert das System einen Detection Transformer, einen modernen Ansatz zur Objekterkennung, der das Auffinden eines Gesichts als direkte Vorhersageaufgabe behandelt, statt das Bild mit vielen sich überlappenden Boxen zu durchsuchen. Diese Komponente lernt, Gesichter zuverlässig zu lokalisieren, selbst in überfüllten Szenen, und übergibt sauber gerahmte Gesichtsbereiche an die Emotionsmodule. Die Autoren kombinieren außerdem automatisch gelernte Merkmale mit älteren, handgefertigten Deskriptoren, die Kanten und lokale Textur betonen, und erzeugen so ein hybrides Merkmalset, das besser gegen Änderungen in der Beleuchtung und partielle Verdeckungen resistent ist. Um das natürliche Ungleichgewicht der Emotionskategorien — deutlich mehr lächelnde als ängstliche Gesichter — auszugleichen, erweitern sie die Trainingsdaten intensiv durch Drehen, Spiegeln sowie Veränderung von Farbe und Kontrast, wodurch effektiv neue, vielfältige Beispiele für unterrepräsentierte Ausdrücke entstehen.
Tests mit realen und herausfordernden Gesichtern
Das Team evaluiert den Ansatz auf zwei weit verbreiteten Datenbanken für Gesichtsausdrücke — AffectNet und CK+ — sowie auf einem neuen, im eigenen Labor aufgenommenen Datensatz. Dieser spezielle Datensatz enthält bewusst harte Beleuchtung, komplexe und sich verändernde Hintergründe sowie Personen aus unterschiedlichen kulturellen Umgebungen, um Situationen zu imitieren, denen ein Roboter im Feld begegnen könnte. Über alle drei Datensätze hinweg erzielt das Multi-Modul-System hohe Genauigkeit: es übertrifft 90 % bei den öffentlichen Sammlungen und erreicht rund 98 % auf den sorgfältig kuratierten Labordaten. Datenaugmentation verbessert konstant die Leistung, insbesondere bei schwierigen Emotionen wie Angst und Ekel, und das kombinierte Ensemble übertrifft sowohl klassische handgefertigte Pipelines als auch moderne Ein-Netzwerk-Baselines. Wichtig ist außerdem, dass die Autoren durch die Fokussierung auf eine effiziente Modellfamilie die Verarbeitung schnell genug für Echtzeitreaktionen halten.
Sensiblere maschinelle Partner bauen
Praktisch zeigt diese Arbeit, dass Roboter mit einem geschichteten Sehsystem ausgestattet werden können, das nicht nur Gesichter findet, sondern deren emotionale Inhalte mit einer Zuverlässigkeit liest, die für den täglichen Einsatz geeignet ist. Durch das Stapeln mehrerer spezialisierter Netzwerke, das Hinzufügen eines modernen Gesichtserkennungsmoduls und das sorgfältige Erweitern sowie Ausbalancieren der Trainingsdaten kann das System ein breites Spektrum grundlegender Emotionen auch unter schwierigen visuellen Bedingungen verstehen. Für Nicht-Expertinnen und Nicht-Experten ist die Quintessenz klar: Mit einer solchen Architektur werden zukünftige Roboter und interaktive Geräte besser wahrnehmen können, ob jemand glücklich, aufgebracht, ängstlich oder gleichgültig ist — und ihr Verhalten entsprechend anpassen — wodurch unsere Interaktion mit Maschinen natürlicher, unterstützender und menschlicher wirkt.
Zitation: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Schlüsselwörter: Mensch-Roboter-Interaktion, Emotionserkennung, Gesichtsausdrücke, Deep Learning, transformatorbasierte Vision