Clear Sky Science · en
A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction
Teaching Robots to Read Our Feelings
As robots move into homes, hospitals, and classrooms, it is no longer enough for them to simply follow instructions. To be truly helpful, they must sense how we feel and adapt their behavior—comforting a nervous patient, calming an upset driver, or encouraging a shy student. This paper presents a new way for robots to read human emotions from facial expressions quickly and accurately, even in messy real-world settings where lighting, background clutter, and partial occlusions often confuse machines.

Why Emotionally Aware Robots Matter
Human–robot interaction depends on more than voice commands and precise movements. People naturally signal emotions through their faces, and we expect socially intelligent machines to notice and respond appropriately. Existing emotion-recognition systems often work well only in controlled lab conditions: faces are centered, well lit, and clearly visible. In everyday life, however, faces are turned, partially hidden, or captured in poor lighting, and some emotions—such as fear or disgust—appear far less often in training images. The authors aim to bridge this gap by designing an emotion-recognition system robust enough for real-world deployments in settings like security screening, healthcare support, driver monitoring, and personalized education.
Blending Multiple Brain-Inspired Networks
Instead of relying on a single artificial neural network, the researchers build a "multi-module" system that combines the strengths of several advanced image-analysis models. Four different convolutional and transformer-based networks each examine incoming face images in their own way: some focus on efficiency for real-time use, others excel at capturing fine details or long-range relationships between facial regions, and one highlights critical areas such as the eyes and mouth. Their outputs are fused into a rich shared representation that captures both subtle textures and global patterns of expression. This fused representation is then fed to a group of classifiers, including a convolutional network, a recurrent unit that can track changes over time in video, and a traditional multi-layer perceptron, whose combined vote produces the final emotion label.
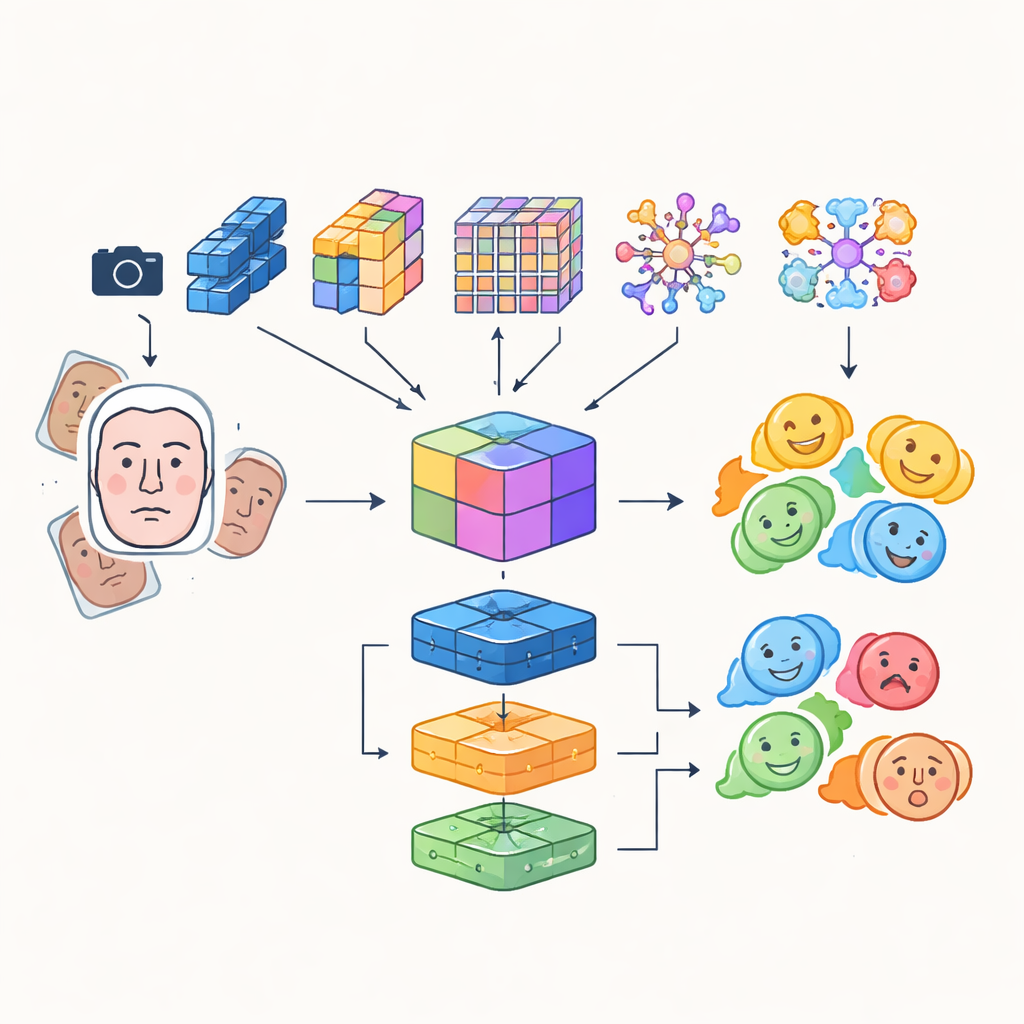
Sharper Eyes and Smarter Training Data
To ensure the robot focuses on the right face at the right moment, the system integrates a detection transformer, a modern object-detection approach that treats finding a face as a direct prediction task rather than scanning the image with many overlapping boxes. This component learns to pinpoint faces reliably, even in crowded scenes, and passes clean, well-framed facial regions to the emotion modules. The authors also blend automatically learned features with older, hand-crafted descriptors that pay attention to edges and local texture, creating a hybrid feature set that can better resist changes in illumination and partial occlusion. To compensate for the natural imbalance of emotional categories—many more smiling faces than fearful ones—they heavily augment the training data by rotating, flipping, and altering color and contrast, effectively generating new, varied examples of underrepresented expressions.
Testing on Real and Challenging Faces
The team evaluates their approach on two widely used facial-expression databases—AffectNet and CK+—as well as a new custom-made dataset recorded in their lab. This custom dataset deliberately includes harsh lighting, complex and shifting backgrounds, and people from diverse cultural settings, better mimicking situations a robot might encounter in the wild. Across all three datasets, the multi-module system achieves high accuracy, exceeding 90% on the public collections and around 98% on the carefully curated lab data. Data augmentation consistently boosts performance, particularly for difficult emotions like fear and disgust, and the combined ensemble outperforms both classic hand-crafted pipelines and modern single-network baselines. Importantly, by centering the design on an efficient model family, the authors keep processing fast enough for real-time responses.
Building More Sensitive Machine Partners
In practical terms, this work shows that robots can be equipped with a layered vision system that not only finds faces but also reads their emotional content with a level of reliability suitable for everyday use. By stacking multiple specialized networks, adding a modern face-detection module, and carefully expanding and balancing the training data, the system can understand a wide range of basic emotions even under difficult visual conditions. For non-experts, the takeaway is straightforward: with this kind of architecture, future robots and interactive devices will be better able to sense when someone is happy, upset, anxious, or indifferent—and to adjust their actions accordingly—making our interactions with machines feel more natural, supportive, and humane.
Citation: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Keywords: human-robot interaction, emotion recognition, facial expressions, deep learning, transformer-based vision