Clear Sky Science · es
Una novedosa estrategia multimódulo de redes neuronales para el reconocimiento de emociones humanas en la interacción humano-robot
Enseñar a los robots a leer nuestras emociones
A medida que los robots entran en hogares, hospitales y aulas, ya no basta con que sigan instrucciones. Para ser verdaderamente útiles, deben percibir cómo nos sentimos y adaptar su comportamiento—consolar a un paciente nervioso, calmar a un conductor inquieto o animar a un estudiante tímido. Este artículo presenta una nueva forma para que los robots lean las emociones humanas a partir de las expresiones faciales de manera rápida y precisa, incluso en entornos reales desordenados donde la iluminación, el fondo ocluso y las obstrucciones parciales suelen confundir a las máquinas.

Por qué importan los robots con sensibilidad emocional
La interacción humano–robot depende de algo más que comandos de voz y movimientos precisos. Las personas transmiten emociones de forma natural a través del rostro, y esperamos que las máquinas socialmente inteligentes las detecten y respondan adecuadamente. Los sistemas actuales de reconocimiento de emociones suelen funcionar bien solo en condiciones de laboratorio controladas: los rostros están centrados, bien iluminados y claramente visibles. En la vida cotidiana, sin embargo, los rostros están girados, parcialmente ocultos o captados con mala iluminación, y algunas emociones—como el miedo o el asco—aparecen con poca frecuencia en las imágenes de entrenamiento. Los autores buscan cerrar esta brecha diseñando un sistema de reconocimiento emocional lo bastante robusto para despliegues en el mundo real en entornos como controles de seguridad, asistencia sanitaria, monitorización de conductores y educación personalizada.
Combinando múltiples redes inspiradas en el cerebro
En lugar de confiar en una única red neuronal artificial, los investigadores construyen un sistema “multimódulo” que combina las fortalezas de varios modelos avanzados de análisis de imágenes. Cuatro redes diferentes, basadas en convoluciones y transformadores, examinan de forma independiente las imágenes faciales entrantes: unas se centran en la eficiencia para uso en tiempo real, otras son eficaces captando detalles finos o relaciones a larga distancia entre regiones faciales, y una destaca áreas críticas como ojos y boca. Sus salidas se fusionan en una representación compartida rica que captura tanto texturas sutiles como patrones globales de la expresión. Esta representación fusionada se alimenta luego a un conjunto de clasificadores, incluidos una red convolucional, una unidad recurrente capaz de rastrear cambios a lo largo del tiempo en vídeo y un perceptrón multicapa tradicional, cuyo voto combinado produce la etiqueta emocional final.
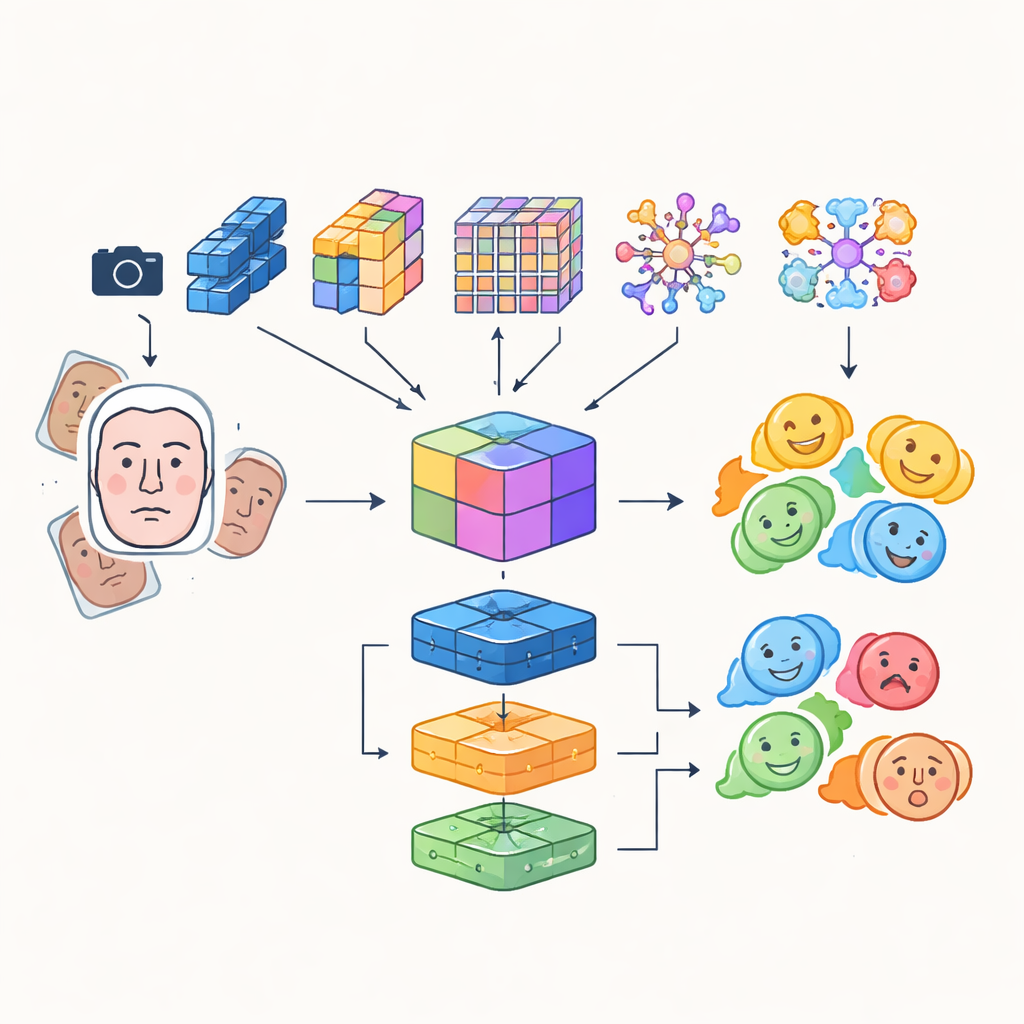
Miradas más agudas y datos de entrenamiento más inteligentes
Para asegurar que el robot se concentre en el rostro correcto en el momento adecuado, el sistema integra un transformador de detección, un enfoque moderno de detección de objetos que trata la localización de un rostro como una tarea de predicción directa en lugar de escanear la imagen con muchas cajas superpuestas. Este componente aprende a localizar rostros con fiabilidad, incluso en escenas concurridas, y pasa regiones faciales limpias y bien encuadradas a los módulos de emoción. Los autores también combinan características aprendidas automáticamente con descriptores tradicionales hechos a mano que prestan atención a bordes y texturas locales, creando un conjunto de características híbrido que resiste mejor los cambios de iluminación y la oclusión parcial. Para compensar el desequilibrio natural entre categorías emocionales—muchas más caras sonrientes que temerosas—augmentan intensamente los datos de entrenamiento rotando, volteando y alterando el color y el contraste, generando efectivamente nuevos ejemplos variados de expresiones infrarepresentadas.
Pruebas con rostros reales y desafiantes
El equipo evalúa su enfoque en dos bases de datos de expresiones faciales ampliamente utilizadas—AffectNet y CK+—así como en un nuevo conjunto de datos hecho a medida grabado en su laboratorio. Este conjunto personalizado incluye deliberadamente iluminación dura, fondos complejos y cambiantes, y personas de entornos culturales diversos, emulando mejor situaciones que un robot podría encontrar en libertad. En los tres conjuntos, el sistema multimódulo alcanza alta precisión, superando el 90 % en las colecciones públicas y alrededor del 98 % en los datos de laboratorio cuidadosamente seleccionados. La aumentación de datos mejora consistentemente el rendimiento, especialmente para emociones difíciles como el miedo y el asco, y el conjunto combinado supera tanto a las canalizaciones clásicas de características hechas a mano como a las líneas base modernas de red única. Es importante destacar que, al centrar el diseño en una familia de modelos eficientes, los autores mantienen el procesamiento lo suficientemente rápido para respuestas en tiempo real.
Construir compañeros de máquina más sensibles
En términos prácticos, este trabajo demuestra que los robots pueden equiparse con un sistema de visión por capas que no solo detecta rostros, sino que también lee su contenido emocional con un nivel de fiabilidad adecuado para el uso cotidiano. Apilando múltiples redes especializadas, añadiendo un moderno módulo de detección facial y ampliando y equilibrando cuidadosamente los datos de entrenamiento, el sistema puede comprender una amplia gama de emociones básicas incluso en condiciones visuales difíciles. Para los no especialistas, la conclusión es clara: con este tipo de arquitectura, los futuros robots y dispositivos interactivos estarán mejor capacitados para detectar cuándo alguien está contento, molesto, ansioso o indiferente—y para ajustar sus acciones en consecuencia—haciendo que nuestras interacciones con las máquinas se sientan más naturales, comprensivas y humanas.
Cita: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Palabras clave: interacción humano-robot, reconocimiento de emociones, expresiones faciales, aprendizaje profundo, visión basada en transformadores