Clear Sky Science · ru
Новая много-модульная стратегия нейронных сетей для распознавания человеческих эмоций в взаимодействии человек–робот
Обучение роботов понимать наши чувства
По мере того как роботы проникают в дома, больницы и классы, им уже недостаточно просто выполнять инструкции. Чтобы быть по-настоящему полезными, они должны улавливать наши эмоции и адаптировать поведение — утешить нервного пациента, успокоить расстроенного водителя или поддержать стеснительного ученика. В этой статье представлен новый подход, позволяющий роботам быстро и точно считывать человеческие эмоции по выражению лица, даже в реальных, «грязных» условиях, где освещение, загроможденный фон и частичные закрытия часто сбивают алгоритмы с толку.

Почему важны эмоционально отзывчивые роботы
Взаимодействие человек–робот включает не только голосовые команды и точные движения. Люди естественным образом передают эмоции через лицо, и мы ожидаем, что социально интеллигентные машины это заметят и отреагируют соответствующе. Существующие системы распознавания эмоций часто хорошо работают лишь в контролируемых лабораторных условиях: лица выровнены, хорошо освещены и четко видны. В повседневной жизни лица могут быть повернуты, частично закрыты или сняты при плохом освещении, и некоторые эмоции — например страх или отвращение — встречаются в обучающих данных гораздо реже. Авторы ставят задачу сократить этот разрыв, разработав систему распознавания эмоций, достаточно устойчивую для реального применения в таких областях, как досмотр, медицинская поддержка, мониторинг водителя и персонализированное образование.
Сочетание нескольких сетей, вдохновленных работой мозга
Вместо опоры на одну искусственную нейронную сеть исследователи строят «много-модульную» систему, объединяющую преимущества нескольких продвинутых моделей анализа изображений. Четыре различные сверточные и трансформерные сети по‑разному анализируют входные изображения лиц: одни ориентированы на эффективность для работы в реальном времени, другие хорошо улавливают тонкие детали или дальние взаимосвязи между областями лица, а одна выделяет критические зоны, такие как глаза и рот. Их выходы объединяются в богатое общее представление, которое фиксирует как тонкие текстуры, так и глобальные шаблоны выражения. Это объединённое представление затем подаётся в набор классификаторов, включая сверточную сеть, рекуррентный модуль, способный отслеживать изменения во времени в видео, и традиционный многослойный персептрон; их совместное голосование даёт окончательную метку эмоции.
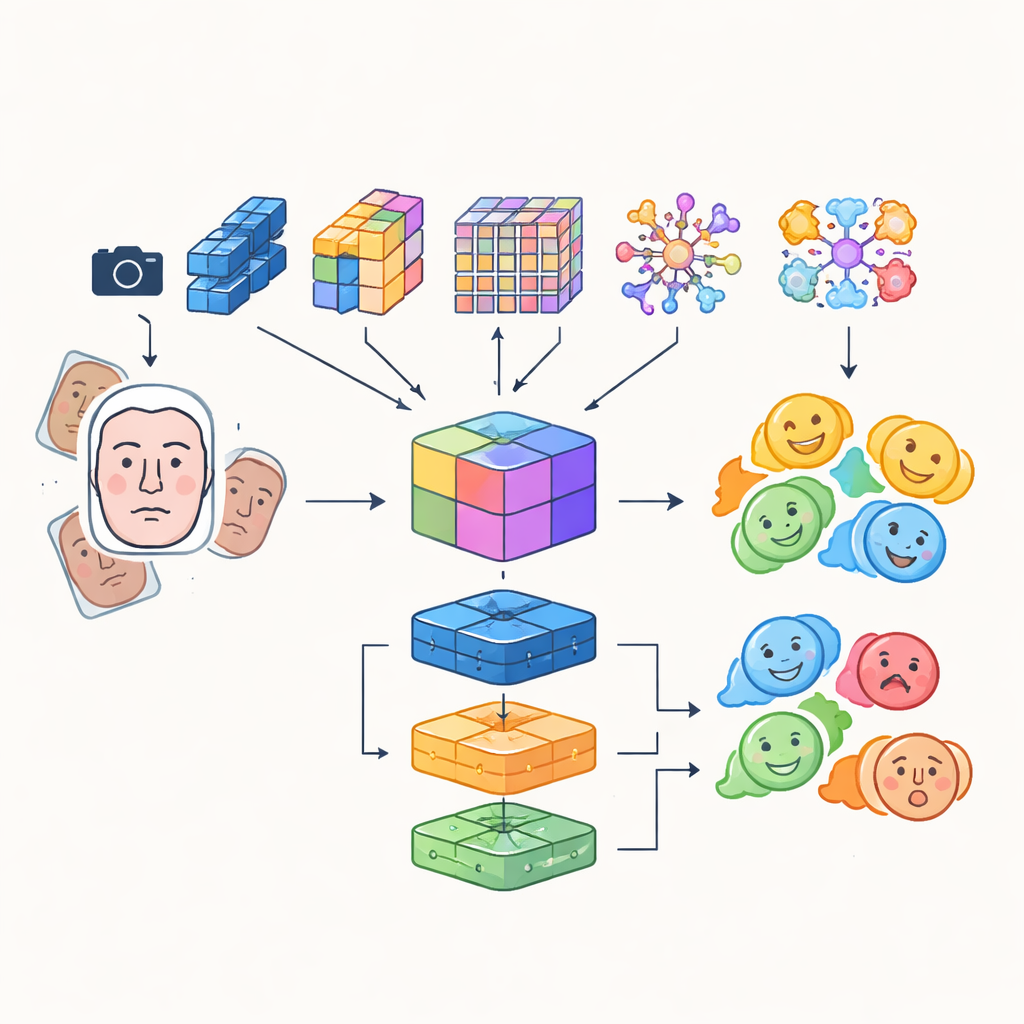
Более острый взгляд и умнее подготовленные данные
Чтобы система фокусировалась на нужном лице в нужный момент, в неё интегрирован detection transformer — современный подход к детекции объектов, который рассматривает поиск лица как задачу прямого предсказания, а не как сканирование изображения множеством пересекающихся рамок. Этот компонент обучается надёжно локализовывать лица даже в многолюдных сценах и передаёт чистые, хорошо кадрированные участки лица модулям распознавания эмоций. Авторы также смешивают автоматически извлекаемые признаки с более старыми, ручными дескрипторами, которые акцентируют внимание на краях и локальной текстуре, создавая гибридный набор признаков, лучше сопротивляющийся изменениям освещения и частичным закрытиям. Чтобы компенсировать естественный дисбаланс эмоциональных категорий — например, гораздо больше улыбающихся лиц, чем испуганных — они интенсивно расширяют обучающую выборку поворотами, отражениями, изменением цвета и контраста, эффективно генерируя новые, разнообразные примеры мало представленных выражений.
Тестирование на реальных и сложных лицах
Команда оценивает свой подход на двух широко используемых базах данных выражений лица — AffectNet и CK+ — а также на новой собственной базе данных, записанной в их лаборатории. Эта собственная база намеренно включает резкое освещение, сложные и изменяющиеся фоны и людей из разных культурных сред, лучше имитируя ситуации, с которыми робот может столкнуться в реальной жизни. По всем трём наборам данных много-модульная система показывает высокую точность: более 90% на публичных коллекциях и около 98% на тщательно отобранных лабораторных данных. Аугментация данных стабильно повышает результаты, особенно для сложных эмоций вроде страха и отвращения, а объединённый ансамбль превосходит как классические конвейеры с ручными признаками, так и современные одно-сетевые базовые модели. Важно, что, ориентируясь на эффективную семью моделей, авторы сохраняют достаточную скорость обработки для ответов в реальном времени.
Создание более чутких машинных партнёров
В практическом смысле эта работа демонстрирует, что роботов можно оснастить многослойной зрительной системой, которая не только находит лица, но и считывает их эмоциональное содержание с уровнем надёжности, подходящим для повседневного использования. Сочетая несколько специализированных сетей, добавляя современный модуль детекции лиц и аккуратно расширяя и балансируя обучающие данные, система способна распознавать широкий спектр базовых эмоций даже при сложных визуальных условиях. Для непрофессионалов вывод прост: с такой архитектурой будущие роботы и интерактивные устройства смогут лучше понимать, когда человек счастлив, расстроен, тревожится или равнодушен — и соответствующим образом корректировать свои действия, делая наше общение с машинами более естественным, поддерживающим и человечным.
Цитирование: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Ключевые слова: взаимодействие человек–робот, распознавание эмоций, мимика, глубокое обучение, визуальные трансформеры