Clear Sky Science · pt
Uma nova estratégia multi-módulo de redes neurais para reconhecimento de emoção humana na interação humano-robô
Ensinando Robôs a Ler Nossos Sentimentos
À medida que robôs entram em lares, hospitais e salas de aula, não basta mais que sigam instruções. Para serem verdadeiramente úteis, precisam perceber como nos sentimos e adaptar seu comportamento — confortar um paciente nervoso, acalmar um motorista perturbado ou incentivar um aluno tímido. Este artigo apresenta uma nova forma de os robôs reconhecerem emoções humanas a partir de expressões faciais de modo rápido e preciso, mesmo em cenários reais e desordenados, onde iluminação, fundo confuso e oclusões parciais frequentemente confundem as máquinas.

Por que Robôs com Consciência Emocional Importam
A interação humano–robô depende de mais do que comandos de voz e movimentos precisos. As pessoas sinalizam emoções naturalmente pelo rosto, e esperamos que máquinas socialmente inteligentes percebam e respondam adequadamente. Sistemas existentes de reconhecimento de emoção costumam funcionar bem apenas em condições de laboratório controladas: rostos centralizados, bem iluminados e claramente visíveis. No cotidiano, entretanto, rostos estão virados, parcialmente ocultos ou capturados em iluminação ruim, e algumas emoções — como medo ou nojo — aparecem com muito menos frequência nas imagens de treino. Os autores buscam reduzir essa lacuna projetando um sistema de reconhecimento de emoções robusto o bastante para implantações no mundo real em cenários como triagem de segurança, suporte à saúde, monitoramento de motoristas e educação personalizada.
Misturando Múltiplas Redes Inspiradas no Cérebro
Em vez de confiar em uma única rede neural artificial, os pesquisadores constroem um sistema “multi-módulo” que combina as forças de vários modelos avançados de análise de imagens. Quatro redes diferentes, baseadas em convolução e em transformers, examinam as imagens faciais de entrada de maneiras distintas: algumas priorizam eficiência para uso em tempo real, outras se destacam em capturar detalhes finos ou relações de longo alcance entre regiões do rosto, e uma destaca áreas críticas como olhos e boca. As saídas são fundidas em uma representação compartilhada rica que captura tanto texturas sutis quanto padrões globais de expressão. Essa representação fundida é então alimentada a um conjunto de classificadores, incluindo uma rede convolucional, uma unidade recorrente capaz de acompanhar mudanças ao longo do tempo em vídeo, e um perceptron multicamada tradicional, cujo voto combinado produz o rótulo final da emoção.
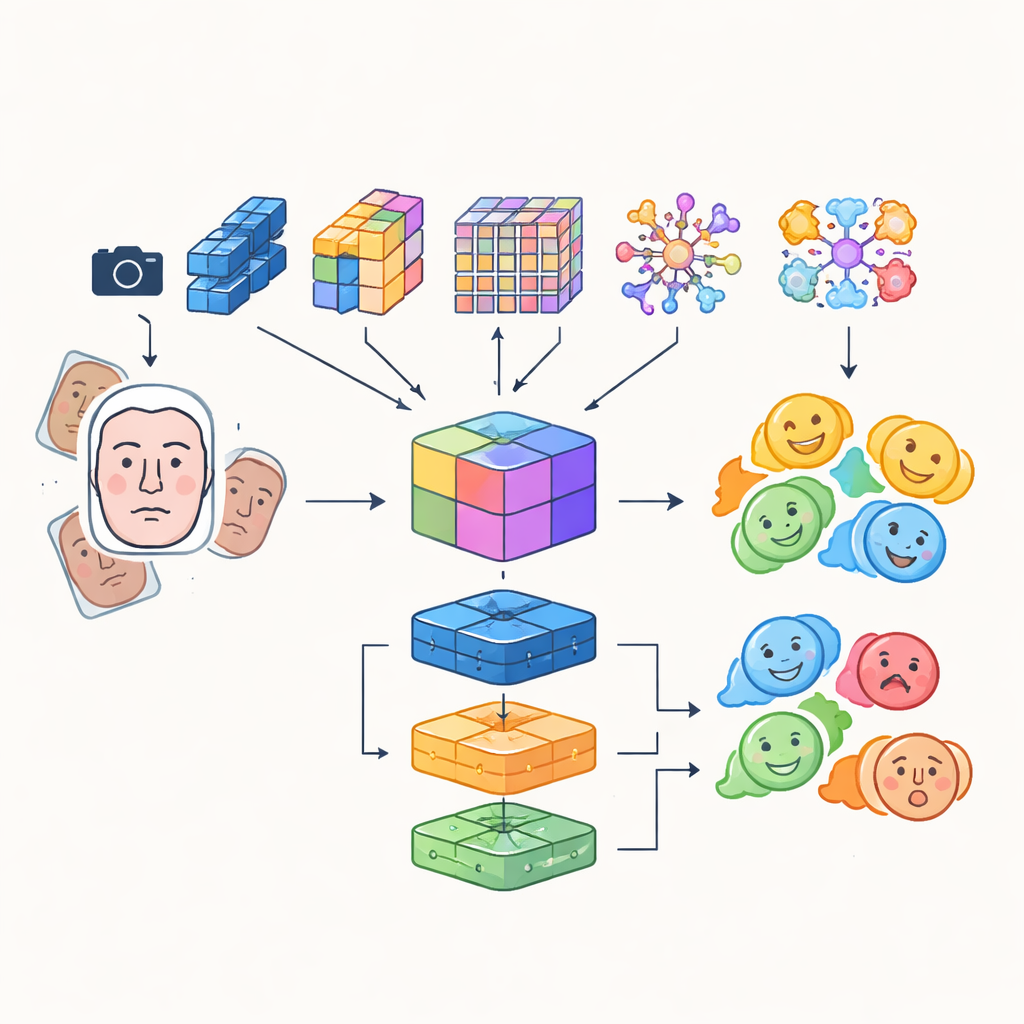
Olhos Mais Afiados e Dados de Treinamento Mais Inteligentes
Para garantir que o robô foque no rosto certo no momento certo, o sistema integra um detector baseado em transformer, uma abordagem moderna de detecção de objetos que trata a localização do rosto como uma predição direta em vez de escanear a imagem com muitas caixas sobrepostas. Esse componente aprende a localizar rostos de forma confiável, mesmo em cenas lotadas, e passa regiões faciais limpas e bem enquadradas para os módulos de emoção. Os autores também combinam características aprendidas automaticamente com descritores manuais mais antigos que prestam atenção a bordas e texturas locais, criando um conjunto híbrido de características que resiste melhor a mudanças de iluminação e oclusões parciais. Para compensar o desequilíbrio natural nas categorias emocionais — muito mais rostos sorrindo do que com medo — eles aumentam fortemente os dados de treinamento rotacionando, espelhando e alterando cor e contraste, gerando efetivamente novos exemplos variados de expressões sub-representadas.
Testando com Rostos Reais e Desafiadores
A equipe avalia sua abordagem em duas bases de dados amplamente usadas de expressões faciais — AffectNet e CK+ — assim como em um novo conjunto de dados criado em seu laboratório. Esse conjunto customizado inclui propositalmente iluminação severa, fundos complexos e variáveis, e pessoas de contextos culturais diversos, imitando melhor as situações que um robô pode encontrar no mundo real. Em todas as três bases, o sistema multi-módulo alcança alta acurácia, excedendo 90% nas coleções públicas e cerca de 98% nos dados criteriosamente curados do laboratório. A ampliação de dados aumenta consistentemente o desempenho, particularmente para emoções difíceis como medo e nojo, e o ensemble combinado supera tanto pipelines clássicos com características manuais quanto redes únicas modernas. Importante: ao centrar o projeto em uma família de modelos eficiente, os autores mantêm o processamento rápido o suficiente para respostas em tempo real.
Construindo Parceiros de Máquina Mais Sensíveis
Em termos práticos, este trabalho mostra que robôs podem ser equipados com um sistema de visão em camadas que não apenas encontra rostos, mas também lê seu conteúdo emocional com um nível de confiabilidade adequado ao uso cotidiano. Ao empilhar múltiplas redes especializadas, adicionar um módulo moderno de detecção facial e expandir e balancear cuidadosamente os dados de treinamento, o sistema pode entender uma ampla gama de emoções básicas mesmo sob condições visuais difíceis. Para não especialistas, a conclusão é direta: com esse tipo de arquitetura, futuros robôs e dispositivos interativos serão mais capazes de perceber quando alguém está feliz, perturbado, ansioso ou indiferente — e ajustar suas ações de acordo — tornando nossas interações com máquinas mais naturais, solidárias e humanas.
Citação: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Palavras-chave: interação humano-robô, reconhecimento de emoções, expressões faciais, aprendizado profundo, visão baseada em transformer