Clear Sky Science · sv
En ny flermodulsstrategi med neurala nätverk för igenkänning av mänskliga känslor i människa–robot-interaktion
Lära robotar att läsa våra känslor
När robotar flyttar in i hem, sjukhus och klassrum räcker det inte längre att de bara följer instruktioner. För att vara verkligt hjälpsamma måste de kunna uppfatta hur vi känner och anpassa sitt beteende — trösta en nervös patient, lugna en upprörd förare eller uppmuntra en blyg elev. Denna artikel presenterar ett nytt sätt för robotar att snabbt och noggrant läsa mänskliga känslor från ansiktsuttryck, även i röriga verkliga miljöer där ljusförhållanden, bakgrundsröran och partiella skymningar ofta förvirrar maskiner.

Varför känslomedvetna robotar spelar roll
Människa–robot-interaktion bygger på mer än röstkommandon och precisa rörelser. Människor signalerar naturligt känslor genom sina ansikten, och vi förväntar oss att socialt intelligenta maskiner ska uppmärksamma och reagera lämpligt. Befintliga system för känsloigenkänning fungerar ofta bra enbart i kontrollerade labbförhållanden: ansikten är centrerade, väl belysta och tydligt synliga. I vardagslivet däremot är ansikten vridna, delvis dolda eller inspelade i dåligt ljus, och vissa känslor — som rädsla eller avsmak — förekommer mycket mer sällan i träningsbilder. Författarna syftar till att överbrygga detta gap genom att designa ett känsloigenkänningssystem som är robust nog för verkliga användningsområden som säkerhetskontroller, vårdstöd, förarövervakning och personlig utbildning.
Att blanda flera hjärninspirerade nätverk
I stället för att förlita sig på ett enda artificiellt neuralt nätverk bygger forskarna ett "flermodulärt" system som kombinerar styrkorna hos flera avancerade bildanalysmodeller. Fyra olika konvolutions- och transformerbaserade nätverk granskar inkommande ansiktsbilder på sina egna sätt: några fokuserar på effektivitet för realtidsbruk, andra är utmärkta på att fånga fina detaljer eller långdistansrelationer mellan ansiktsregioner, och ett framhäver kritiska områden som ögon och mun. Deras utdata förenas till en rik gemensam representation som fångar både subtila texturer och globala uttrycksmönster. Denna sammanslagna representation matas sedan till en grupp klassificerare, inklusive ett konvolutionsnätverk, en rekurrent enhet som kan följa förändringar över tid i video, och en traditionell flerskiktsperceptron, vars samlade omröstning ger den slutliga känsloklassificeringen.
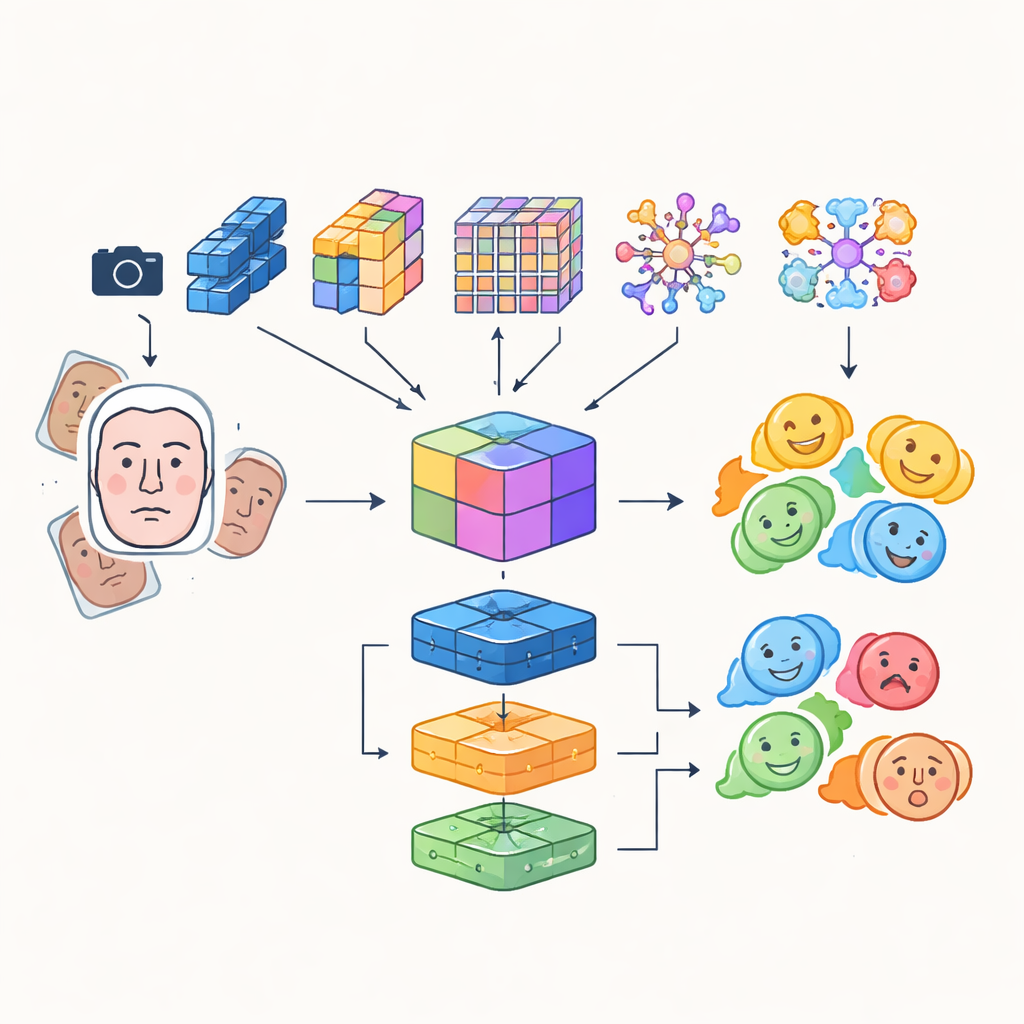
Skarpare blickar och smartare träningsdata
För att säkerställa att roboten fokuserar på rätt ansikte i rätt ögonblick integrerar systemet en detektionstransformer, en modern metod för objektigenkänning som behandlar att hitta ett ansikte som en direkt prediktionsuppgift istället för att skanna bilden med många överlappande rutor. Denna komponent lär sig att pricka in ansikten pålitligt, även i trånga scener, och förser känslomodulerna med rena, välinramade ansiktsregioner. Författarna blandar också automatiskt inlärda funktioner med äldre, handgjorda deskriptorer som uppmärksammar kanter och lokal textur, vilket skapar en hybrid funktionsuppsättning som bättre står emot förändringar i belysning och partiell ocklusion. För att kompensera för den naturliga obalansen i känslokategorier — många fler leende ansikten än rädda — augmenterar de träningsdata kraftigt genom att rotera, vända och ändra färg och kontrast, vilket effektivt genererar nya, varierade exempel av underrepresenterade uttryck.
Testning på verkliga och utmanande ansikten
Teamet utvärderar sin metod på två välanvända databaser för ansiktsuttryck — AffectNet och CK+ — samt på en ny egenproducerad dataset inspelad i deras labb. Denna egna dataset inkluderar medvetet hård belysning, komplexa och skiftande bakgrunder samt personer från olika kulturella miljöer, vilket bättre efterliknar situationer en robot kan möta i verkligheten. Över alla tre dataset når det flermodulära systemet hög noggrannhet, över 90 % på de publika samlingarna och cirka 98 % på det omsorgsfullt kurerade labbmaterialet. Dataaugmentation förbättrar konsekvent prestandan, särskilt för svåra känslor som rädsla och avsmak, och ensemblelösningen överträffar både klassiska handgjorda pipelines och moderna enkla nätverksbaslinjer. Viktigt är att genom att utgå från en effektiv modellfamilj håller författarna bearbetningen tillräckligt snabb för realtidsreaktioner.
Att bygga mer känsliga maskinpartners
I praktiska termer visar detta arbete att robotar kan utrustas med ett lager på lager-videosystem som inte bara hittar ansikten utan också läser deras känslomässiga innehåll med en pålitlighet som är lämplig för vardagsanvändning. Genom att stapla flera specialiserade nätverk, lägga till en modern ansiktsdetektionsmodul och noggrant utöka och balansera träningsdata kan systemet förstå ett brett spektrum av grundläggande känslor även under svåra visuella förhållanden. För icke-experter är slutsatsen enkel: med denna typ av arkitektur kommer framtida robotar och interaktiva enheter bättre kunna känna när någon är glad, upprörd, ängslig eller likgiltig — och anpassa sina handlingar därefter — vilket gör våra interaktioner med maskiner mer naturliga, stödjande och mänskliga.
Citering: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Nyckelord: människa–robot-interaktion, känsloigenkänning, ansiktsuttryck, djuplärande, transformer-baserad vision