Clear Sky Science · fr
Une nouvelle stratégie multi-module de réseaux neuronaux pour la reconnaissance des émotions humaines dans l’interaction homme-robot
Apprendre aux robots à lire nos émotions
À mesure que les robots investissent les foyers, les hôpitaux et les salles de classe, il ne suffit plus qu’ils exécutent des consignes. Pour être véritablement utiles, ils doivent percevoir nos émotions et adapter leur comportement : réconforter un patient nerveux, calmer un conducteur contrarié ou encourager un élève timide. Cet article présente une nouvelle méthode permettant aux robots de reconnaître rapidement et précisément les émotions humaines à partir des expressions faciales, même dans des environnements réels désordonnés où l’éclairage, l’encombrement de l’arrière-plan et les occultations partielles perturbent souvent les machines.

Pourquoi des robots sensibles aux émotions sont importants
L’interaction homme–robot repose sur plus que des commandes vocales et des mouvements précis. Les personnes expriment naturellement des émotions par le visage, et nous attendons des machines socialement intelligentes qu’elles les remarquent et réagissent de manière appropriée. Les systèmes actuels de reconnaissance des émotions fonctionnent souvent bien uniquement en conditions de laboratoire contrôlées : les visages sont centrés, bien éclairés et clairement visibles. Dans la vie courante, toutefois, les visages sont tournés, partiellement cachés ou capturés dans un mauvais éclairage, et certaines émotions — comme la peur ou le dégoût — apparaissent beaucoup moins souvent dans les images d’entraînement. Les auteurs cherchent à réduire cet écart en concevant un système de reconnaissance des émotions suffisamment robuste pour des déploiements réels dans des contextes tels que le contrôle de sécurité, l’assistance médicale, la surveillance du conducteur et l’éducation personnalisée.
Mélanger plusieurs réseaux inspirés du cerveau
Plutôt que de s’appuyer sur un unique réseau neuronal artificiel, les chercheurs construisent un système « multi-module » qui combine les forces de plusieurs modèles avancés d’analyse d’image. Quatre réseaux différents, à base de convolutions et de transformeurs, examinent chacun les images de visage selon leur propre approche : certains privilégient l’efficacité pour une utilisation en temps réel, d’autres excellent à capturer les détails fins ou les relations à longue portée entre régions faciales, et l’un met en évidence les zones critiques comme les yeux et la bouche. Leurs sorties sont fusionnées en une représentation partagée riche qui capte à la fois les textures subtiles et les motifs globaux d’expression. Cette représentation fusionnée est ensuite transmise à un ensemble de classifieurs, incluant un réseau convolutionnel, une unité récurrente capable de suivre les changements temporels dans la vidéo, et un perceptron multi-couches traditionnel, dont le vote combiné produit l’étiquette émotionnelle finale.
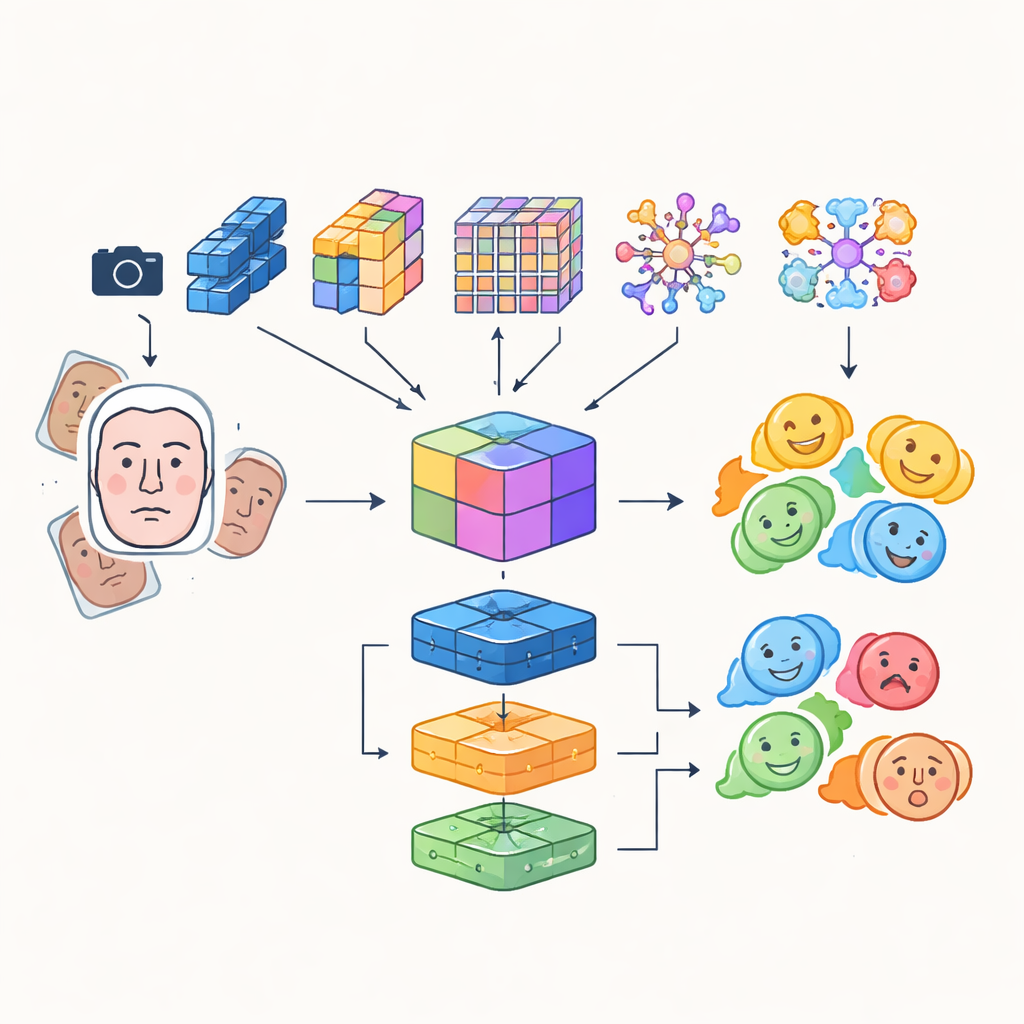
Des « yeux » plus précis et des données d’entraînement plus intelligentes
Pour s’assurer que le robot se concentre sur le bon visage au bon moment, le système intègre un transformeur de détection, une approche moderne de détection d’objets qui considère la localisation d’un visage comme une tâche de prédiction directe plutôt que comme un balayage de l’image avec de nombreuses boîtes chevauchantes. Ce composant apprend à repérer les visages de façon fiable, même dans des scènes encombrées, et transmet des régions faciales propres et bien cadrées aux modules d’émotion. Les auteurs combinent également des caractéristiques automatiquement apprises avec d’anciens descripteurs faits main qui prêtent attention aux contours et à la texture locale, créant un ensemble de caractéristiques hybride mieux à même de résister aux changements d’illumination et aux occultations partielles. Pour compenser le déséquilibre naturel des catégories émotionnelles — beaucoup plus de visages souriants que de visages effrayés — ils augmentent fortement les données d’entraînement en tournant, retournant et modifiant la couleur et le contraste, générant ainsi de nouveaux exemples variés des expressions sous-représentées.
Tests sur des visages réels et difficiles
L’équipe évalue son approche sur deux bases de données d’expressions faciales largement utilisées — AffectNet et CK+ — ainsi que sur un nouveau jeu de données créé en interne dans leur laboratoire. Ce jeu de données personnalisé inclut délibérément des éclairages rudes, des arrière-plans complexes et changeants, et des personnes issues de contextes culturels divers, reproduisant mieux les situations que pourrait rencontrer un robot sur le terrain. Sur les trois ensembles, le système multi-module atteint une grande précision, dépassant 90 % sur les collections publiques et environ 98 % sur les données de laboratoire soigneusement sélectionnées. L’augmentation des données améliore systématiquement les performances, en particulier pour les émotions difficiles comme la peur et le dégoût, et l’ensemble combiné surpasse à la fois les pipelines classiques faits main et les modèles baselines à réseau unique modernes. Fait important, en centrant la conception sur une famille de modèles efficaces, les auteurs conservent une vitesse de traitement suffisante pour des réponses en temps réel.
Construire des partenaires machines plus sensibles
Concrètement, ce travail montre que les robots peuvent être équipés d’un système de vision en couches qui non seulement détecte les visages mais en lit aussi le contenu émotionnel avec un niveau de fiabilité adapté à l’usage quotidien. En empilant plusieurs réseaux spécialisés, en ajoutant un module moderne de détection de visage et en élargissant et équilibrant soigneusement les données d’entraînement, le système peut comprendre une large gamme d’émotions de base même dans des conditions visuelles difficiles. Pour les non-spécialistes, la conclusion est simple : avec ce type d’architecture, les futurs robots et dispositifs interactifs seront mieux à même de percevoir quand quelqu’un est heureux, contrarié, anxieux ou indifférent — et d’ajuster leurs actions en conséquence — rendant nos interactions avec les machines plus naturelles, solidaires et humaines.
Citation: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Mots-clés: interaction homme-robot, reconnaissance des émotions, expressions faciales, apprentissage profond, vision basée sur transformeur